
Mờ Lờ Óp #1 - Tổng quan về Mờ Lờ Óp
Bài đăng này đã không được cập nhật trong 3 năm
Mở đầu
Trong Kinh Thánh có một câu nói nổi tiếng rằng Đức tin mà không có việc làm là một ĐỨC TIN CHẾT. Cũng như vậy, trong lĩnh vực AI cũng có một câu nói như thế rằng MÔ HÌNH AI mà chỉ nằm trên Jupyter Notebook là một MÔ HÌNH CHẾT. Bạn có thấy câu nói này nổi tiếng không, chắc là chưa phải không (vì mình với mới nghĩ ra mà 😀😀😀. Dù chưa được nổi tiếng lắm nhưng điều mình muốn nhấn mạnh rằng dù chúng ta có làm giời biển gì với mô hình của mình, đạt được độ chính xác suất xắc đi chăng nữa thì cuối cùng chúng ta cũng phải đưa nó đến tay người dùng. Như vậy mới là một dự án AI thành công. Điều này sẽ dẫn chúng ta đến rất nhiều vấn đề nữa cần phải tìm hiểu gọi chung là MLOps - Machine Learning Operations. Mình dự định sẽ viết một chuỗi các bài về chủ đề này note lại các kiến thức cơ bản nhất. Và đây là bài đầu tiên. OK, lét gâu.
Các khái niệm chính
Mục tiêu của MLOps
Mục tiêu chung là xây dựng, triển khai, tối ưu và vận hành hệ thống AI trên môi trường production
Vòng đời của một sản phẩm ML
 Bao gồm 4 giai đoạn chính là
Bao gồm 4 giai đoạn chính là
- Scoping: ĐỊnh nghĩa mục tiêu, phạm vi và các vấn đề cần giải quyết trong dự án
- Data: Chuẩn bị dữ liệu, trích chọn các đặc trưng, xử lý input cho mô hình
- Modeling: Xây dựng mô hình AI
- Deployment: Triển khai và vận hành sản phẩm trên môi trường production.
Giai đoạn trong MLOps
- Phát triển & Thử nghiệm (thuật toán ML, mô hình ML mới)
- Xây dựng pipeline Continuous Integration (Build source code và run tests)
- Xây dựng pipeline Continuous Delivery: Deploy pipeline lên môi trường production
- Automated Triggering tự động thực hiện các tác vụ trên môi trường pruduction
- Model Continuous Delivery (Model serving for prediction)
- Monitoring Thu thập dữ liệu về hiệu suất mô hình trên dữ liệu thực tế.
Các hiện tượng thường gặp
Data Drift
Phân phối dữ liệu khi huấn luyện KHÁC VỚI phân phối dữ liệu trên thực tế sử dụng
Từ khoá cần lưu ý là đây là THAY ĐỔI. Thế giới liên tục thay đổi và chúng ta phải thích ứng. Tương tự như vậy, dữ liệu trên thực té luôn luôn thay đổi và mô hình của chúng ta phải thích ứng với những sự thay đổi đó.
Vòng đời chính của sản phẩm ML
Một câu hỏi đặt ra ngay từ lúc đầu bài viết đó là Sau khi huấn luyện mô hình AI rồi thì sao? Chúng ta sẽ làm gì tiếp theo.. Câu trả lời đó là đưa nó lên production thôi. Và rất nhiều vấn đề chúng ta sẽ phải đối mặt kể từ đây. Hãy luôn luôn tâm niệm rằng, chúng ta không chỉ xây dựng mô hình tốt trên Jupyter Notebook mà còn phải đưa nó vào thực tế sử dụng, đưa nó đến tay của thật nhiều người dùng.
Ví dụ kiểm tra lỗi điện thoại
Bài toán
Sử dụng Computer Vision để phát hiện lỗi trên màn hình điện thoại như vết vỡ, khoanh vùng vết vỡ trên màn hình điện thoại. Với các dataset chuẩn bị là các màn hình điện thoại bị trầy xước và bounding box tương ứng chúng ta có thể huấn luyện một mô hình object detection đơn giản để giải quyết bài toán này.
Câu hỏi đặt ra
Làm thế nào để triển khai dịch vụ này lên production?
Giải pháp
- Sử dụng một prediction server accept API calls, có thể triển khai trên cloud hay edge devices
- Nhận image dầu vào là một ảnh
- Đưa ra dự đoán với ảnh đầu vào
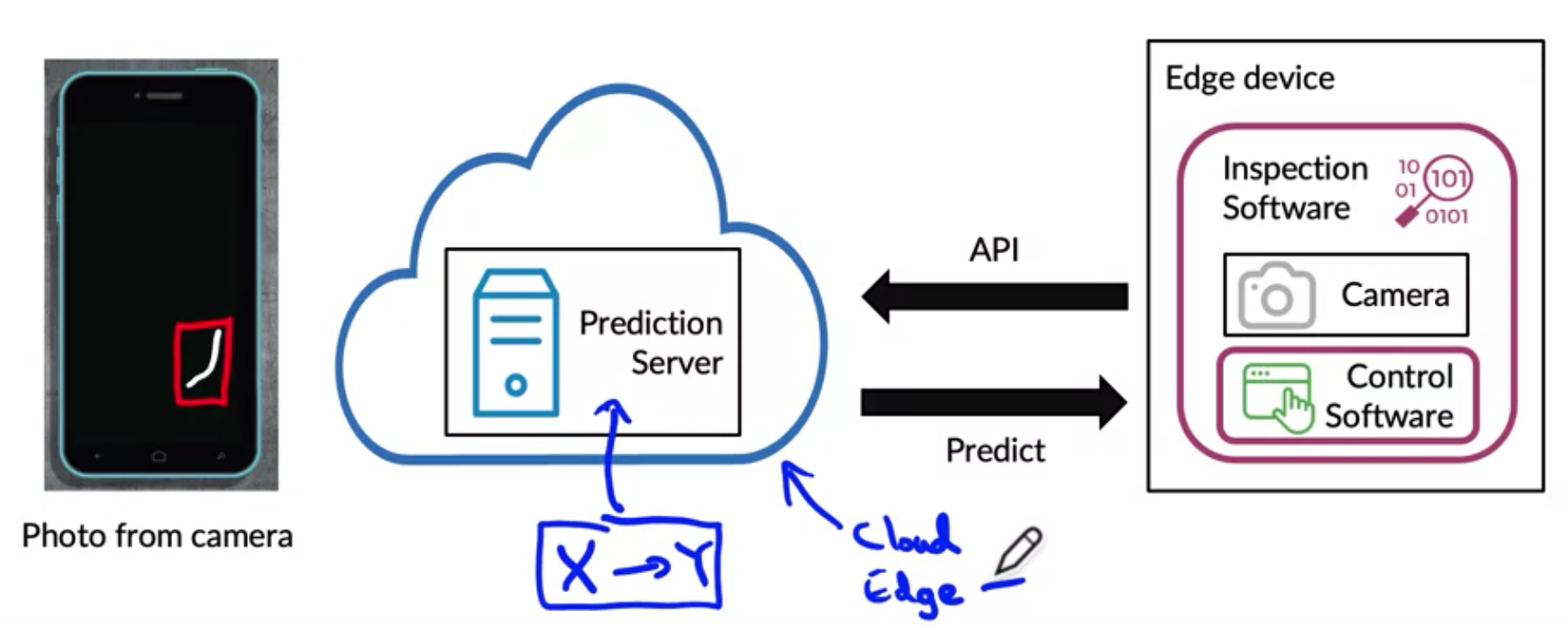
Vấn đề xảy ra...
- Các mô hình huấn luyện có thể hoạt động tốt trên test set. Tuy nhiên với dữ liệu thực tế thì CHƯA CHẮC.
- Trong thực tế đôi khi ảnh có thể bị tối hơn, vết xước dài hơn, điều kiện chụp ảnh cũng khác hơn. Đây goi là hiện tượng data Drift hay concept Drift.

Và còn rất rất nhiều hiện tượng khác xảy ra trong quá trình triển khai mà chúng ta không lường trước được.
Thời gian thực hiện MLOps
Thời gian thực hiện MLOps thường là dài hơn rất nhiều so với thời gian phát triển mô hình. Thông thường, thời gian phát triển mô hình chỉ chiếm khoảng 5 - 10% mà thôi.

Case study: Speech Recognition
Bước 1: Scoping

- Định nghĩa bài toán: Nhận diện giọng nói
- Đầu vào: X là một giọng nói
- Đầu ra: Y là một chuỗi text
- Định nghĩa metrics đánh giá:
- accuracy: độ chính xác của mô hình
- latency: độ trễ của mô hình
- throughput: số lượng phép xử lý trên một đơn vị thời gian
- Đánh giá, ước lượng tài nguyên cần sử dụng và timeline phát triển
Bước 2: Chuẩn bị dữ liệu

- Đinh nghĩa dữ liệu: Đưa ra các câu hỏi để định nghĩa dữ liệu
- Dữ liệu có được gán nhãn nhất quán hay không?
- Ví dụ với một đoạn audio chứa tiếng anh có thể có hai cách annotate:
- Đây là câu hỏi về MLOps
- Đây là câu hỏi về mờ lờ ọp
- ....
- Ví dụ với một đoạn audio chứa tiếng anh có thể có hai cách annotate:
- Độ dài trung binh của audio là bao nhiêu?
- Các môi trường thu thập audio là như thế nào (có nhiều giọng nói khác nhau hay không, có ồn hay không...)
- Thiết bị thu thập dữ liệu có yêu cầu gì không?
- Dữ liệu có được gán nhãn nhất quán hay không?
Bước 3: Modeling

Chúng ta có công thức đơn giản như sau:
ML MODEL = A + B + C trong đó
- A là code
- B là hyperparams
- C là data
Công việc cụ thể của từng đội như sau:
- Đội Research / Academia’s: thì Data là cố định, thay đổi Code và Hyperparams
- Đội Product thì Code là cố định, Data và Hyperparams thay đổi.
Bước 4: Deployment
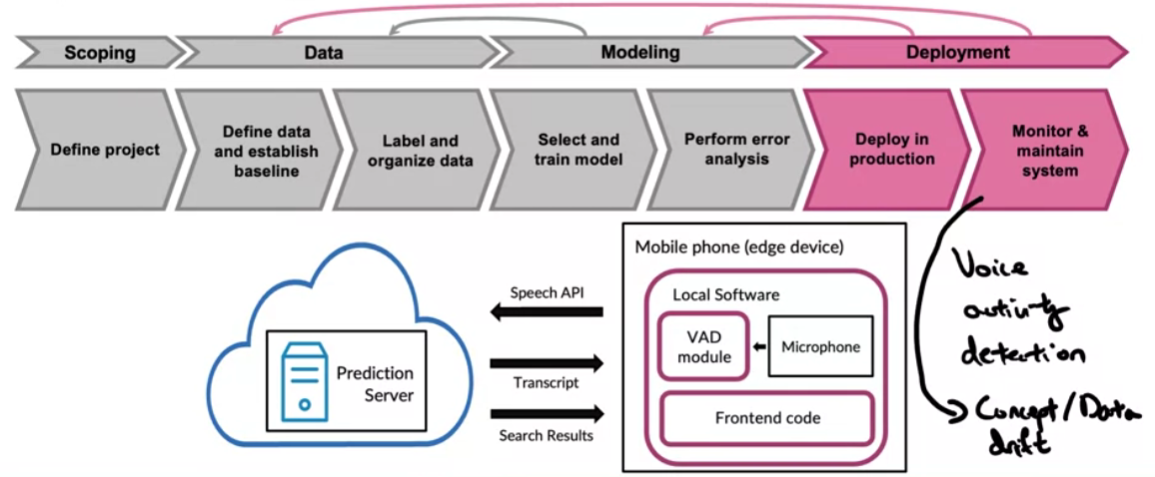
Đây là một bước rất quan trọng và cũng khá dài nên chúng ta sẽ cùng bàn luận nó trong bài viết tiếp theo nhé.
Tạm kết
Chúng ta đã tìm hiểu sơ lượng về các thành phần chính trong một hệ thống ML cũng như các công việc chính trong MLOps. Hẹn gặp lại các bạn trong các bài tiếp theo.
All rights reserved
