[MLE - 01] Machine Learning Experiment, why ?
Bài đăng này đã không được cập nhật trong 4 năm
1. Một dự án Machine Learning được thực hiện như thế nào ?
Các bạn có thể nghe nói rất nhiều về Machine Learning và ứng dụng của nó, nhưng ít ai biết rằng quá trình phát triển nó lại là một công việc gần giống với các nhà nghiên cứu (Trừ phi vấn đề bạn gặp phải đã được giải quyết, và bạn có thể lấy kết quả nghiên cứu từ một tổ chức đã giải quyết vấn đề đó). Việc phát triển một dự án Machine Learning bao gồm 3 phần chính, và được thực hiện liên tục tạo thành một vòng đời khép kín, cho đến khi bạn đạt được kết quả mong muốn.
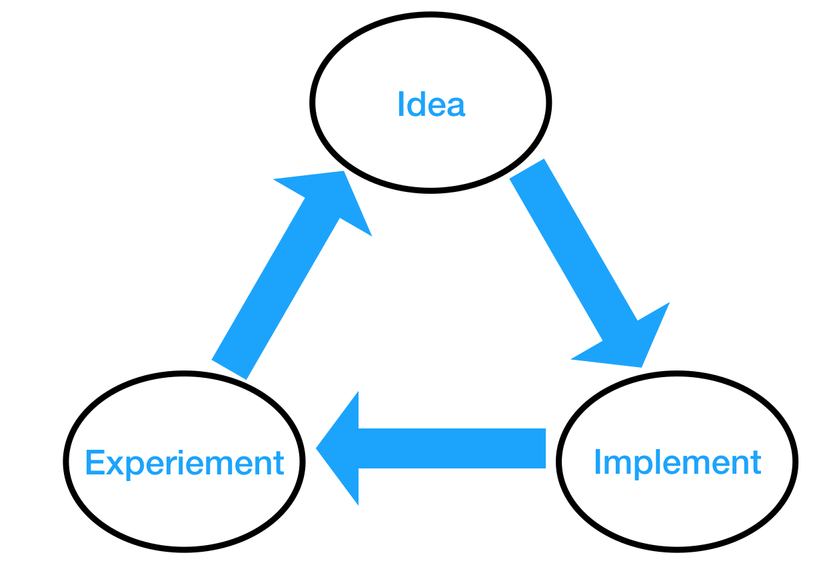 Idea: Đây là nơi ta quyết định sẽ làm gì với dự án của mình, lựa chọn giải thuật nào, có nên thu thập thêm dữ liệu hay không, có nên kiểm tra lại dữ liệu hiện tại xem có vấn đề gì không, có nên thay đổi các tham số của mô hình hay không,..
Implement: Đây là nơi ta triển khai những gì ta lựa chọn ở trên, thu thập thêm dữ liệu, thay đổi giải thuật, thay đổi cấu trúc model (Deep Learning), thử training lại mô hình với tham số mới..
Experiment: Đây là nơi mà series này đang nói đến, ta sẽ đo đạc, kiểm tra xem mô hình có vấn đề gì không, hiệu quả đến mức nào...
Khi bắt đầu dự án, bạn lựa chọn một giải thuật đơn giản -> Implement chúng -> Kiểm tra xem hiệu quả của chúng tới đâu -> Hiệu quả chưa tốt -> Thử với giải thuật mới, tham số mới, thêm dữ liệu mới -> Implement chúng -> Kiểm tra xem hiệu quả của hệ thống hiện tại ra sao -> ... Công việc trên tạo nên vòng đời khép kín cho quá trình phát triển dự án ML, bên cạnh việc hiểu các giải thuật, các tham số, ý nghĩa của dữ liệu.. và triển khai chúng qua việc lập trình, xây dựng hệ thống, xây dựng hệ thống phần cứng phù hợp... thì việc phát hiện vấn đề, đo đạc hiệu năng của hệ thống là vô cùng quan trọng.
Hãy lấy một ví dụ để mọi việc được sáng tỏ hơn
Idea: Đây là nơi ta quyết định sẽ làm gì với dự án của mình, lựa chọn giải thuật nào, có nên thu thập thêm dữ liệu hay không, có nên kiểm tra lại dữ liệu hiện tại xem có vấn đề gì không, có nên thay đổi các tham số của mô hình hay không,..
Implement: Đây là nơi ta triển khai những gì ta lựa chọn ở trên, thu thập thêm dữ liệu, thay đổi giải thuật, thay đổi cấu trúc model (Deep Learning), thử training lại mô hình với tham số mới..
Experiment: Đây là nơi mà series này đang nói đến, ta sẽ đo đạc, kiểm tra xem mô hình có vấn đề gì không, hiệu quả đến mức nào...
Khi bắt đầu dự án, bạn lựa chọn một giải thuật đơn giản -> Implement chúng -> Kiểm tra xem hiệu quả của chúng tới đâu -> Hiệu quả chưa tốt -> Thử với giải thuật mới, tham số mới, thêm dữ liệu mới -> Implement chúng -> Kiểm tra xem hiệu quả của hệ thống hiện tại ra sao -> ... Công việc trên tạo nên vòng đời khép kín cho quá trình phát triển dự án ML, bên cạnh việc hiểu các giải thuật, các tham số, ý nghĩa của dữ liệu.. và triển khai chúng qua việc lập trình, xây dựng hệ thống, xây dựng hệ thống phần cứng phù hợp... thì việc phát hiện vấn đề, đo đạc hiệu năng của hệ thống là vô cùng quan trọng.
Hãy lấy một ví dụ để mọi việc được sáng tỏ hơn 
2. Ví dụ cụ thể ?
Giả sử ta đang làm bài toán về phân loại trong một bức ảnh có người hay không.

 Chúng ta bắt đầu dự án với một giải thuật nào đó, đội dev rất nhanh giúp bạn có được phần implement, và giờ công việc của ta chỉ là đánh giá xem, hệ thống có tốt hay không, khả năng phát hiện người trong bức ảnh tốt tới mức nào. Một cách suy nghĩ thông thường nhất là ta lấy một lượng lớn ảnh và cho hệ thống phán đoán và kết quả rất khả quan độ chính xác đạt tới 99%. Bạn ung dung đem hệ thống cho khách hàng sử dụng và kết quả là sản phẩm của bạn chẳng dự đoán được có người xuất hiện trong ảnh hay không, lúc nào nó cũng đoán không có người trong ảnh. Dự án tan tành từ trong trứng nước!
Tại sao khi test, kết quả đạt tới 99% chính xác nhưng khi khách hàng sử dụng thì nó chẳng hoạt động gì cả, code lỗi chăng ? Cũng có thể, bạn đổ tại đội dev, họ khẳng định không có sai sót gì -> mất tình đồng nghiệp, dev xịn chạy hết qua hàng xóm, công ty phá sản, bạn thất nghiệp về bán bún ngoài vỉa hè ) Đùa chút như vậy, nhưng thực tế rằng, chuyện độ chính xác đạt 99% nhưng hệ thống lại chẳng hoạt động tốt là chuyện.. bình thường.
Bạn thử tưởng tượng nếu như data sử dụng để test toàn là ảnh không có người, chỉ có 1% trong số đó có người và "vô tình" hệ thống thân yêu của bạn lại luôn dự đoán trong ảnh không có người. Thế là nàng nghiễm nhiên có 99% chính xác. Vậy nên việc thử nghiệm trong dự án Machine Learning không đơn thuần chỉ là quẳng cho nó ít test case và chạy, bạn cần phải hiểu và "tinh tế" đôi chút. Như vậy mới giúp cho hệ thống tốt hơn và không bị những con số như 99% che mắt. Nếu như bạn hứng thú, hãy cùng tôi đi tiếp series này trong bài viết tiếp theo
Tài liệu tham khảo: website http://www.deeplearning.org/
Chúng ta bắt đầu dự án với một giải thuật nào đó, đội dev rất nhanh giúp bạn có được phần implement, và giờ công việc của ta chỉ là đánh giá xem, hệ thống có tốt hay không, khả năng phát hiện người trong bức ảnh tốt tới mức nào. Một cách suy nghĩ thông thường nhất là ta lấy một lượng lớn ảnh và cho hệ thống phán đoán và kết quả rất khả quan độ chính xác đạt tới 99%. Bạn ung dung đem hệ thống cho khách hàng sử dụng và kết quả là sản phẩm của bạn chẳng dự đoán được có người xuất hiện trong ảnh hay không, lúc nào nó cũng đoán không có người trong ảnh. Dự án tan tành từ trong trứng nước!
Tại sao khi test, kết quả đạt tới 99% chính xác nhưng khi khách hàng sử dụng thì nó chẳng hoạt động gì cả, code lỗi chăng ? Cũng có thể, bạn đổ tại đội dev, họ khẳng định không có sai sót gì -> mất tình đồng nghiệp, dev xịn chạy hết qua hàng xóm, công ty phá sản, bạn thất nghiệp về bán bún ngoài vỉa hè ) Đùa chút như vậy, nhưng thực tế rằng, chuyện độ chính xác đạt 99% nhưng hệ thống lại chẳng hoạt động tốt là chuyện.. bình thường.
Bạn thử tưởng tượng nếu như data sử dụng để test toàn là ảnh không có người, chỉ có 1% trong số đó có người và "vô tình" hệ thống thân yêu của bạn lại luôn dự đoán trong ảnh không có người. Thế là nàng nghiễm nhiên có 99% chính xác. Vậy nên việc thử nghiệm trong dự án Machine Learning không đơn thuần chỉ là quẳng cho nó ít test case và chạy, bạn cần phải hiểu và "tinh tế" đôi chút. Như vậy mới giúp cho hệ thống tốt hơn và không bị những con số như 99% che mắt. Nếu như bạn hứng thú, hãy cùng tôi đi tiếp series này trong bài viết tiếp theo
Tài liệu tham khảo: website http://www.deeplearning.org/
All rights reserved
