Mít đặc và biết tuốt nói chuyện về những lời đồn trong tối ưu SQL
Bài đăng này đã không được cập nhật trong 2 năm
Mít đặc: Hi anh Tuốt tôi có biết một số mẹo hay về tối ưu hôm nay tôi muốn chia sẻ với anh. Những điều này được đồn đại trong giới developer năm này qua năm khác nên tôi nghĩ nó hiệu quả.
Biết tuốt: Hay quá tôi rất muốn nghe
Mít đặc: Điều đầu tiên, Select * sẽ kém hơn là Select cụ thể các trường.
Biết tuốt: Ý là nếu bạn liệt kê tất cả các trường trong câu truy vấn thì sẽ nhanh hơn là SELECT *?
Mít đặc: Tôi cho là như vậy, dù gì db đỡ phải nghĩ trả về trường gì thì chắc là nhanh hơn chứ?
Biết tuốt: Không hẳn là như vậy, Select * chậm hơn select theo trường, nhưng không phải cứ thay Select * bằng select theo trường thì hiệu năng sẽ được cải thiện, điều này cần hiểu sâu hơn một chút.
Mít đặc: Ồ đã là best practice rồi cần gì phải ngâm cứu thêm, theo rule là chạy chứ
Biết tuốt: Thực ra việc select * chậm hơn thông thường theo một số case. Nếu một câu lệnh chỉ select các trường trong index thì nó sẽ nhanh hơn select * tới 100 lần
Mít đặc: Đó nó đúng chưa nào? Nhưng tại sao lại như vậy
Biết tuốt: Như chúng ta đã biết ở series tối ưu database. Việc đọc dữ liệu có hai phần, một phần duyệt trên index, một phần là đọc dữ liệu trong bảng. Nếu dữ liệu ta cần đọc có hết trên index, cơ sở dữ liệu không cần đọc trong bảng nữa, nên có thể tăng tốc gấp 100 lần
Mít đặc: Ồ vậy trường hợp thông thường thì sao? có thể thêm nhiều lần chứ
Biết tuốt: Còn trường hợp chiếm RAM bộ nhớ, Mạng, rồi tốn trình dọn rác, mất công đọc, có thể tăng tốc thêm 5 lần, tuy nhiên bạn nhớ không phải là do select * làm chậm mà là chúng ta nên biết cách truy vấn đủ. Dù cho có select thông thường nhưng mà lấy tất các trường thì cũng không khác gì select *
Mít đặc: Đúng vậy, không phải select * là vấn đề mà bản chất là select thừa trường là vấn đề. OK vậy tiếp theo còn có một tin đồn khác là count(1) sẽ nhanh hơn count ( * ) vì rõ là select * chậm hơn select 1 đúng không?
Biết tuốt: Nghe có vẽ như vậy, nhưng thực ra lại không đúng, bởi vì count( * ) sẽ là count(0) nên hiệu năng là như nhau
Mít đặc: ồ vậy tin đồn này vớ vẩn tôi sẽ dùng count( * ) , Tiếp theo có 1 trick thú vị đây. Là trong bảng cứ trường nào mà có độ selectivity cao thì đánh index trường đó đầu tiên trong index
Biết tuốt: Nghe có vẻ đúng nhỉ, những trường selectivity cao là những trường mà độ trùng lặp ít, nên khi truy vấn theo index sẽ nhanh hơn nhỉ?
Mít đặc: Đúng thế, tip này khá là đúng
Biết tuốt: Thực ra chọn trường này đầu tiên hay không cũng phải phụ thuộc truy vấn, nếu không hiểu về thứ tự trong index có thể gây ra hậu quả lớn!
Mít đặc: Cho xin cái ví dụ xem nào?
Biết tuốt: Ví dụ bạn có bảng Employee có các trường (ID, Name, OrganizationID,Created,Modified). Theo logic của bạn thì ID,Created và Modified sẽ có selectivity cao nhất đúng không? Vì ID là khóa chính sẽ không cần add vào index vậy Index sẽ là (Created,Modified,OrganizationID) đúng không?
Mít đặc: Đúng vậy, vì Created và Modified có selectivity rất cao
Biết tuốt: Nhưng tôi muốn tìm theo cơ cấu tổ chức thì làm thế nào? Câu lệnh sẽ là
SELECT * FROM Employee
WHERE OrganizationID=101
Order By Modified
Trường hợp này sẽ làm sao? Rõ ràng trường OrganizationID có trong index mà không được dùng tới.
Mít đặc: Ồ trường hợp này đúng là phải để trường OrganizationID lên đầu. Rồi đến Modified do có Order By
Biết tuốt: Đúng vậy, việc đánh index phải dựa và query và dữ liệu thực tế chứ không phải selectivity cao là lên đầu bảng
Mít đặc: Vậy trong trường hợp mà query có dùng cả các trường cần index thì cho trường selectivity lên cao là đúng chứ!
Biết tuốt: Trong trường hợp vậy thì đúng, nhưng cũng cần xem tổng quát các query mà chọn thứ tự phù hợp
Mít đặc: Ok vậy là tin đồn cũng đúng trong một số trường hợp, tôi còn tin nữa là lâu lâu thỉnh thoảng phải reindex lại nếu không index bị lủng không hoạt động được nữa.
Biết tuốt: Vậy à. Thực ra nếu bạn biết cấu trúc index bạn sẽ thấy rằng index được tạo nên bởi cây cân bằng, cho nên dù thêm dữ liệu lệch thế nào đi nữa, độ sâu của nó vẫn luôn được cân bằng chứ không bị lệch như cây nhị phân
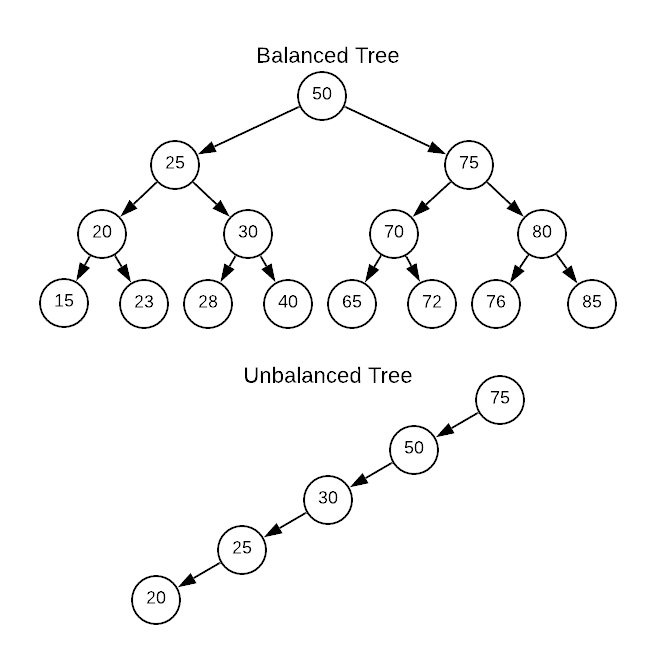
Vì vậy nó sẽ không tăng độ sâu:
Mít đặc: vậy là việc reindex không có tác dụng gì à?
Biết tuốt: Thực ra là có một chút, việc Update hay delete nhiều quá sẽ làm cho việc phân bố không gian trong index không được chặt chẽ, có thể chưa được tối ưu lắm. Việc reindex sẽ giúp việc này tốt hơn, tuy nhiên nó chỉ có hiệu quả tầm 30%, và chỉ hiệu quả cho những câu lệnh tốn kém như Full Index Scan, còn những câu lệnh lấy về 1 vài bản ghi thì việc reindex không có giá trị gì. Mà chính những câu lệnh này mới mang lại sức mạnh cho index
Mít đặc: Vậy cũng không phải lớn lắm nhỉ, có nhiều lời đồn mà có vẻ 50-50 quá. Tôi chốt lại một lời nữa là Dynamic SQL thì chậm hơn câu SQL thường đúng không?
Biết tuốt: Bạn đã đo chưa? Bản chất dynamic sql cũng là câu SQL được chạy thôi, tuy nhiên bạn có thể thấy nó chậm hơn câu SQL thường là do Dynamic SQL thông thường không được cache lại execution plan, nên bị chậm hơn chỗ này. Nếu bạn vẫn dùng dynamic SQL nhưng truyền paramter thì cũng không ảnh hưởng gì hiệu năng do cache được execution plan mà con tránh được SQL Injection
Mít đặc: Ồ vậy là chỉ cần thêm tham số thì Dynamic SQL cũng giống SQL thông thường, cảm ơn bạn, Tôi sẽ cho bạn một upvote, tôi đã thấy nhiều điều hơn về các tin đồn, nó cũng đúng trong một vài trường hợp nhưng không phải lúc nào cũng đúng. Chào nhé!
All rights reserved
