
Mem0 - Kiến trúc Long Term Memory cho hệ thống AI Agent
1. Giới Thiệu
Xin chào mọi người, lại là tôi đây. Trong bài viết này mình xin giới thiệu về Mem0, một phương pháp quản lý Long Term Memory trong hệ thống AI Agents. Bài này mình chủ yếu đọc từ paper và trình bày cấu trúc theo paper: Mem0
Mọi người có thể đọc paper gốc để nắm được chi tiết.
Mem0 sẽ tập trung vào vấn đề chính là phần Long Term Memory trong hệ thống AI Agents. Thì trước tiên chúng ta nên tìm hiểu qua về Memory trong AI Agents là gì.
Tất nhiên là đây chỉ là một module nhỏ trong hệ thống AI Agents thôi, và có thể do mình tìm hiểu chưa kỹ, hi vọng nhận được góp ý từ các bạn.
2. Memory trong AI Agents
Memory trong AI Agents là một bộ nhớ, được xây dựng bên ngoài mô hình ngôn ngữ lớn (LLM) để cung cấp cho hệ thống AI Agent một trí nhớ dài hạn, có cấu trúc và bền bỉ. Tương tự như con người chúng ta sẽ có trí nhớ, tập trung vào cuộc hội thoại, các trí nhớ lâu dài.
Memory trong AI Agents chia làm hai phần: Trí nhớ ngắn hạn (Short Term Memory) và Trí nhớ dài hạn (Long Term Memory)
2.1. Trí nhớ ngắn hạn (Short Term Memory)
Đây là bộ nhớ không bền bỉ, ví dụ như Github Copilot của Visual Studio Code, Short Term Memory chính là một phiên làm việc, một cuộc hội thoại với Agent, và sẽ mất dữ liệu, mất lịch sử trò chuyện khi sang phiên làm việc mới
Ảnh dưới đây là ví dụ của một phiên làm việc, hay còn gọi là short term memory của copilot
2.2. Trí nhớ dài hạn (Long Term Memory)
Khác với Short Term Memory, thì Long Term Memory là dạng trí nhớ lâu dài, bền bỉ, sẽ được lưu trữ riêng biệt, nó có thể lưu ở một file local, có thể là trên cloud. Thật ra là tùy vào nhiều yếu tố như là tính bảo mật, truy cập từ nhiều thiết bị sẽ quyết định nên chọn cách lưu trữ nào
Mem0 sẽ chủ yếu tập trung vào phần Long Term Memory.
3. Giới thiệu về Mem0 (Mem Zero)
3.1. Vấn đề của hệ thống AI Agents nếu không có memory
Đây là phần 1. Introduction trong paper gốc, mình sẽ chủ yếu tóm tắt lại các ý chính. Trí nhớ của con người là đại diện cho sự thông minh, chúng ta nhớ những gì được học, những quyết định của chúng ta trong cuộc sống sẽ dựa trên kiến thức, tri thức chúng ta học được. Tri thức có thể tích lũy qua ngày, tuần, tháng, năm và thậm chí là cả cuộc đời.
Một hệ thống AI Agents cũng nên như thế, tuy nhiên bộ nhớ của các hệ thống đang bị giới hạn bởi sự phụ thuộc vào thứ gọi là "fixed context windows", tức là số lượng token có thể trích xuất ra bị giới hạn, bộ nhớ sẽ có lúc bị đầy, và khi tình trạng đó diễn ra thì Agent sẽ quên đi thông tin.
Ảnh dưới được trích trong paper, mô tả về hệ thống AI Agent với memory.

Như các bạn có thể thấy, với hệ thống AI Agent không có trí nhớ lâu dài (ở bên trái), khi người dùng nói về việc ăn chay và tránh các sản phẩm từ sữa. Thì đến ngày hôm sau được hỏi lại về bữa tối, AI lại gợi ý là "Chicken Alfredo" 😭.
Còn hình bên phải là hệ thống AI Agent có trí nhớ lâu dài, bền bỉ, đến ngày hôm sau thì AI vẫn gợi ý chính xác yêu cầu của người dùng
Câu hỏi đặt ra là, nếu tăng "context window" lên thì có kết quả tốt hay không? Thì OpenAI's GPT-4 (với 128K tokens), o1 (200K context), Claude Sonnet 3.7 (200K Tokens) và Google's Gemini (với ít nhất 10M tokens) đã thực hiện điều đó, tuy nhiên điều thực sự xảy ra là kết quả xử lý sẽ bị chậm hơn nhiều, và đến một lúc nào đó cũng sẽ vượt quá context windows (thậm chí là với Gemini 10M Tokens).
Đến đây thì chắc các bạn cũng thấy đủ vấn đề và tầm quan trọng của Long Term Memory rồi.
Thật ra thì có nhiều hệ thống xử lý vấn đề Memory ví dụ như Zep, MemGPT... rồi, tuy nhiên mình chưa có nhiều thời gian nghiên cứu về các phần trên, thì trong paper của Mem0 cũng đề cập để so sánh với Zep, MemGPT, cho thấy được sự cải tiến rõ rệt:
- Mem0 tốn trung bình 7k token cho mỗi cuộc hội thoại, còn Zep vượt quá 600k token)
- Mem0 thiết kết để có thể truy xuất ngay lập tức trong khi Zep bị phát hiện là tắc nghẽn, xử lý rất chậm.
- Tuy nhiên với ưu điểm trên thì Mem0 cũng phải đánh đổi lại về độ chính xác cụ thể Zep đạt điểm cao nhất trong phần "Open-Domain" , nhưng Mem0 vượt trội hơn Zep ở các hạng mục khác như Single-hop và Temporal.
Mem0 giới thiệu Mem0, kiến trúc giúp dynamically captures, organize, retrievers từ cuộc hội thoại, và , một framework giúp xây dựng theo dạng graph-based dựa trên Mem0 để mô tả tốt hơn các mối quan hệ phức tạp.
3.2. Mem0
Chúng ta sẽ nhìn qua về kiến trúc của Mem0 trước.
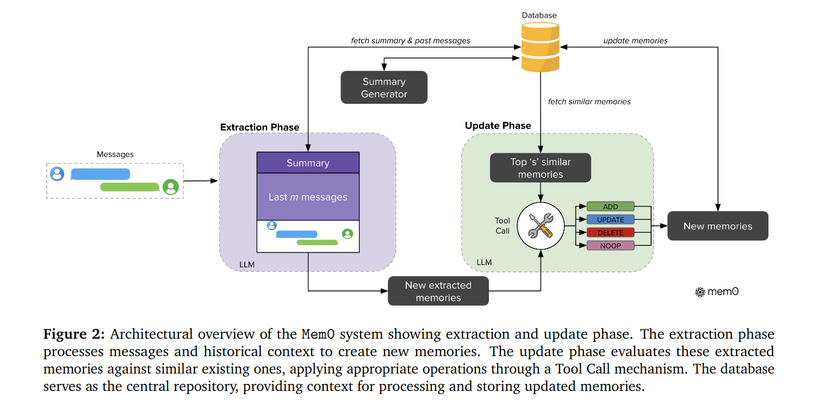
Kiến trúc của Mem0 sẽ bao gồm 2 phase chính là: Extraction và Update Chúng ta sẽ đi vào từng phần trước.
3.2.1. Extraction Phase
Phần Extraction Phase sẽ thực hiện công việc chủ yếu là bóc ra các thông tin quan trọng từ cuộc hội thoại giữa người dùng và Agent, nhận các thành phần như:
- Cặp message pair : với là current message và là message trước đó. Tức là biểu diễu cho 1 tin nhắn và phản hồi hoàn chỉnh từ Agent.
- Conversation Summary S: được trích từ database, là tổng hợp của cuộc hội thoại hiện tại.
- Last m mesages: Là last m messages... lịch sử cuộc trò chuyện của người dùng với Agent {}
Khối Extraction Phase thực chất là một LLM, dành riêng cho tác vụ Extract Memories (hàm ) sử dụng để extracts các thông tin quan trọng (trong paper là salient memories )
Tóm gọm lại, Extraction Phase được viết dưới dạng công thức:
- Input: (P) với P = (S, {}, , )
- Output: Danh sách các thông tin quan trọng = {, , ..., } được LLM trích xuất ra.
3.2.2. Update Phase
Tiếp theo đến với Update Phase, phần này cũng thực chất là LLM, mục tiêu là sử dụng các thông tin quan trọng từ Extraction Phase và đưa qua LLM thông qua Tool Call (hay còn gọi là function calling) để thực hiện các hành động như:
- ADD: thêm mới thông tin
- UPDATE: cập nhật thông tin
- DELETE: xóa thông tin
- NOOP: no operation
Chúng ta lại đi đến từng bước thực hiện của Update Phase:
- Top 's' similar memories (với mỗi từ bước Extraction Phase sẽ được query database để lấy ra cách memories liên quan)
- LLM sẽ nhận sử dụng các Top 's' similar memories, New Extracted Memories để quyết định xem "với mỗi thông tin mới trong , thì ta nên lựa chọn operation là ADD, UPDATE, DELETE hay NOOP
- Kết quả sẽ ra được New memories được update vào database.
Trong Paper gốc có đề cập sử dụng 'm' = 10 là previous messages, 's' = 10 similar memories và sử dụng GPT-4o-mini để inference.
3.2.3. Summary Generator
Ngoài ra còn một module chạy độc lập là Summary Generator, sử dụng để sinh ra Summary của cuộc trò chuyện giữa Agent với User.
3.3.
Ngoài ra paper Mem0 có đề cập đến một framework để lưu trữ Long Term Memory một các hiệu quả, thay vì chỉ lưu trữ embedding trong database, và chúng ta có , là một dạng graph-based memory xây trên nền tảng của neo4j.
Thì chắc các bạn cũng đã nghe qua về GraphRAG rồi, GraphRAG sẽ chủ yếu mô tả được mối quan hệ giữa các thực thể (hay còn gọi là entities) với nhau. Các bạn có thể đọc thêm về GraphRAG trước tìm hiểu về
Dưới đây là kiến trúc graph-based của :
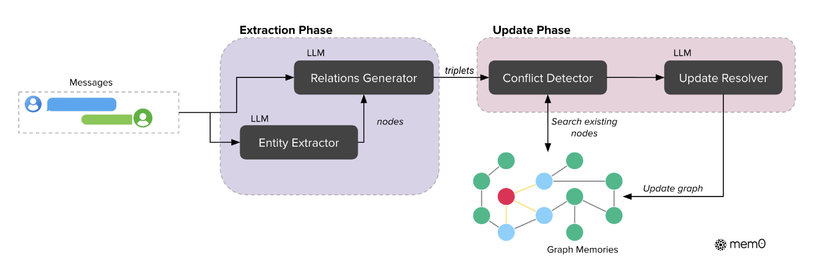
Trong framework này, memories sẽ được biểu diễn như một directed labeled graph G = {V, E, L}, cụ thể:
- Nodes V biểu diễn cho entities (e.g. ALICE, SAN_FRANCISCO...)
- Edges E biểu diễn cho mối quan hệ giữa các entities (e.g. LIVES_IN)
- Labels L sẽ gán ý nghĩa cho các nodes (e.g. ALICE - Person, SAN_FRANCISCO - City)
Mỗi node sẽ được biểu diễn (hay còn gọi là chứa) bởi 3 thành phần:
- Entity Type: Loại của node đó (e.g. Person, Location, Event)
- Embedding Vector: Vector embedding của tên node.
- Metadata bao gồm thời gian được tạo ra (timestamp ), để Agent có được những thông tin như 'xưa từng làm ở chỗ này, bây giờ thì làm ở chỗ khác' (kiểu vậy 😃)
Relationships được cấu trúc thành bộ 3 gồm (, r, ) với:
- : entity source (tên của node nguồn)
- : entity destination (tên của node đích)
- r: labeled edge (hay còn gọi là relationship) kết nối chúng lại với nhau
xây dựng trên nền của Mem0 nên cũng sẽ bao gồm 2 thành phần chính là Extraction Phase và Update Phase, ý nghĩa vẫn sẽ tương tự như Mem0, thay đổi sẽ là tương tác với đồ thị (graph-based)
3.3.1. Extraction Phase.
Phần này sẽ gồm 2 khối chính là Entity Extractor và Relations Generator.
Entity Extractor (LLM)
Module này chủ yếu xử lý input text (pair message như Mem0), để xác định các entities và type của nó, và truyền trực tiếp vào khối Relations Generator
Entity Extractor chủ yếu sẽ xác định các diverse information unit. Ví dụ với cuộc hội thoại về kế hoạch chuyến bay, entities có thể là đích đến (thành phố), phương tiện vận chuyển, ngày tháng năm, hoạt động vui chơi giải trí...)
Relations Generator (LLM)
Module này sẽ nhận input text (pair message như Mem0), các entities từ Entity Extractor để tạo ra các kết nối có ý nghĩa giữa các entities, mục đích là tạo ra các relationship triplets sẽ nắm bắt được các ngữ nghĩa có cấu trúc của thông tin (semantic structure of the information) - Đấy là lý do nó cần đầu vào là cặp message, để có thể hiểu được mối quan hệ giữa các entities bóc ra.
Đầu ra là các relationship triplet là dạng (, r, ) đã được trình bày ở phần trên.
3.3.2. Update Phase
Với mỗi relationship triple từ Extraction Phase, sẽ tính toán các embedding cho cả source và destination entities, và sẽ thực hiện tìm kiếm các các node đã tồn tại bằng semantic similarity của đồ thị (tất nhiên là với threshold 't'). Thì dựa trên việc các node đã tồn tại hay chưa mà graph có thể tạo ra cả 2 node, chỉ tạo 1 node, hoặc là sử dụng node đã tồn tại (cập nhật relationship như ví dụ ''xưa từng làm ở chỗ này, bây giờ thì làm ở chỗ khác")
Để đảm bảo tính nhất quán trong knowledge graph, họ sử dụng module conflict detection để xác định các mối quan hệ có thể bị xung đột (conflicting existing relationships) (chủ yếu là query graph)
Tiếp theo đến module Update Resolver, sẽ nhận đầu vào là các node từ module confict detection, chủ yếu để cập nhật các node đã lỗi thời, 😹 lại là ví dụ "xưa từng làm ở chỗ này, bây giờ thì làm ở chỗ khác"
4. Tổng kết
(Đoạn này mình hỏi gemini 2.5 pro🫠) Mem0 đã thắng lớn bằng cách tập trung vào sự hiệu quả và gọn nhẹ.
- Nhanh và Rẻ : Đây là thắng lợi lớn nhất của Mem0, bằng cách chủ động trích xuất và hợp nhất các thông tin quan trọng
- Chi phí Token: Tiết kiệm hơn 90% chi phí token.
- Độ trễ: Giảm hơn 91% độ trễ p95 so với full-context.
- Chi phí lưu trữ: Gọn nhẹ hơn Zep một cách đáng kinh ngạc (7k token so với 600k token).
- Thông minh và Linh hoạt (Vượt trội về kiến trúc): không chỉ là một RAG đơn giảnn nó là một quy trình 2 giai đoạn Extraction và Update
Tuy nhiên luôn có sự đánh đổi. Mem0 không phải là hoàn hảo. Bài báo đã chỉ ra rõ:
- Nó vẫn chưa chính xác bằng phương pháp "full-context" (67% - 68% J-score so với 73%).
Mem0 (bản cơ sở) vẫn thua Zep trong các câu hỏi Open-Domain (miền mở).
Mem0 chấp nhận một sự đánh đổi nhỏ về độ chính xác tuyệt đối để đổi lấy hiệu suất và chi phí vượt trội.
Nó chứng minh rằng tương lai của AI Agent không phải là tạo ra các Context Window lớn vô tận, mà là xây dựng các hệ thống bộ nhớ ngoài thông minh, gọn nhẹ và có cấu trúc.
Mem0 và đã cung cấp một "bộ công cụ" mạnh mẽ, cho thấy một AI "nhớ" được mọi thứ mà vẫn nhanh và rẻ là hoàn toàn khả thi.
5. Tài liệu tham khảo
All rights reserved
