Mạng tự tổ chức
Bài đăng này đã không được cập nhật trong 4 năm
Trong bài viết trước, mình có giới thiệu phần thuật toán của mạng lan truyền ngược. Hôm nay, mình sẽ tiếp tục giới thiệu về mạng thứ 2 được áp dụng khác phổ biến trong trí tuệ nhân tạo đó là: Mạng neural tự tổ chức. Mạng neural tự tổ chức SOM (Self-Organizing Map) được đề xuất bởi giáo sư Teuvo Kohonen vào năm 1982. Nó còn gọi là: Bản đồ/Ánh xạ đặc trưng tự tổ chức (SOFM-Self Organizing Feature Map) hay đơn giản hơn là mạng neural Kohonen. SOM được coi là một trong những mạng neural hữu ích nhất cho việc mô phỏng quá trình học của não người. Nó không giống với các mạng neural khác chỉ quan tâm đến giá trị và dấu hiệu của thông tin đầu vào, mà có khả năng khai thác các mối liên hệ có tính chất cấu trúc bên trong không gian dữ liệu thông qua một bản đồ đặc trưng. Bản đồ đặc trưng bao gồm các neural tự tổ chức theo các giá trị đầu vào nhất định; do đó nó có thể được huấn luyện để tìm ra các quy luật và sự tương quan giữa các giá trị nhập vào, từ đó dự đoán các kết quả tiếp theo. Có thể nói, nếu một hệ thống mô phỏng quá trình học của não người được thực hiện thì bản đồ đặc trưng của SOM đóng vai trò như trái tim của hệ thống. Tính tự tổ chức của SOM được thực hiện bởi nguyên tắc học cạnh tranh, không giám sát nhằm tạo ra ánh xạ của dữ liệu từ không gian nhiều chiều về không gian ít chiều hơn (thường là hai chiều), nhưng vẫn đảm bảo được quan hệ về mặt hình trạng của dữ liệu. Điều này có nghĩa là các dữ liệu có đặc trưng tương đồng nhau thì sẽ được đại diện bởi cùng một neural hoặc các neural gần nhau và các neural gần nhau thì sẽ tương đồng với nhau hơn so với những neural ở xa. Kết quả là hình thành bản đồ đặc trưng của tập dữ liệu. Đây thực chất là một phép chiếu phi tuyến tạo ra “ánh xạ đặc trưng” cho phép phát hiện và phân tích những đặc trưng trong không gian đầu vào; do đó, SOM là một công cụ hiệu quả cho việc phân cụm trực quan và phân tích dữ liệu nhiều chiều.
1. Mô hình cấu trúc của mạng Kohonen
Mạng neural SOM có cấu trúc đơn lớp, bao gồm: các tín hiệu vào và lớp ra Kohonen
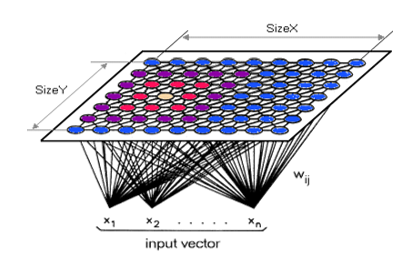
- Hình 1. Cấu trúc mạng SOM với lớp Kohonen 2 chiều
trong đó tất cả các đầu vào được kết nối đầy đủ với mọi neural trên lớp ra Kohonen. Kiến trúc mạng của SOM thuộc đồng thời cả hai nhóm mạng truyền thẳng và mạng phản hồi, do dữ liệu được truyền từ đầu vào tới đầu ra và có sự ảnh hưởng giữa các neural trong lớp Kohonen. Lớp Kohonen thường được tổ chức dưới dạng một ma trận 2 chiều các neural theo dạng lưới hình chữ nhật hoặc hình lục giác. Mỗi đơn vị i (neural) trong lớp Kohonen được gắn một vector trọng số wi= [wi1, wi2, …, win], với n là kích thước (số chiều) vector đầu vào; wi,j là trọng số của neural i ứng với đầu vào j.
Các neural của lớp ra được sắp xếp trên một mảng 2 chiều. Mảng này được gọi là lớp ra Kohonen. Lớp đầu ra này rất khác với lớp đầu ra của mạng neural truyền thẳng. Đối với mạng truyền thẳng, nếu chúng ta có một mạng neural với 5 neural đầu ra, chúng sẽ có thể cho kết quả bao gồm 5 giá trị. Còn trong mạng neural Kohonen chỉ có một neural đầu ra cho ra một giá trị. Giá trị duy nhất này có thể là đúng hoặc sai. Dữ liệu đầu ra từ mạng neural Kohonen thường là các chỉ số của neural.
Trong trường hợp lưới hai chiều, các neural nằm trên bản đồ có thể tồn tại hai loại cấu trúc liên kết là hình lục giác hoặc hình chữ nhật. Tuy nhiên, cấu trúc liên kết hình lục giác đều thì tốt hơn trong tác vụ trực quan hoá vì mỗi neural có 6 neural lân cận trong khi với cấu trúc hình chữ nhật thì chỉ là 4.
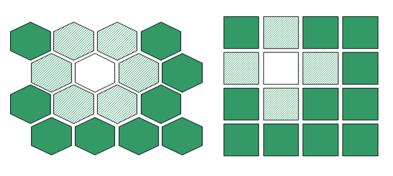
- Hình 2: Cấu trúc hình lục giác đều và cấu trúc hình chữ nhật.
Trong đó:
Lớp vào (Input Layer): dùng để đưa dữ liệu huấn luyện vào mạng Kohonen. Kích thước lớp vào tương ứng với kích thước của mỗi mẫu học.
Lớp ra (Output Layer): các neural của lớp ra được sắp xếp trên mảng hai chiều. Mảng này gọi là lớp ra Kohonen.
Tất cả các noron của lớp vào đều được nối với các neural trên lớp ra. Mỗi liên kết giữa đầu vào và đầu ra của mạng Kohonen tương ứng với một trọng số. Kích thước của mỗi véc tơ trọng số bằng kích thước của lớp vào. Nói cách khác, mỗi neural của lớp Kohonen sẽ có thêm một vector trọng số n chiều (với n là số đầu vào).
2. Học ganh đua
SOM là một kỹ thuật mạng neural truyền thẳng sử dụng thuật toán học không giám sát (học ganh đua) và qua quá trình “tự tổ chức”, sắp xếp đầu ra cho một thể hiện hình học của dữ liệu ban đầu.
Học không giám sát liên quan đến việc dùng các phương pháp quy nạp để phát hiện tính quy chuẩn được thể hiện trong tập dữ liệu. Mặc dù có rất nhiều thuật toán mạng neural cho học không giám sát, trong đó có thuật toán học ganh đua (Conpetitive Learning, Rumelhart & Zipser, 1985). Học ganh đua có thể coi là thuật toán học mạng neural không giám sát thích hợp nhất trong khai phá dữ liệu, và nó cũng minh họa cho sự phù hợp của các phương pháp học mạng neural một lớp.
Nhiệm vụ học xác định bởi học ganh đua là sự phân chia một ví dụ huấn luyện cho trước vào trong một tập các cụm dữ liệu. Các cụm dữ liệu sẽ thể hiện các luật biểu diễn trong tập dữ liệu như các minh hoạ giống nhau được ánh xạ vào các lớp giống nhau.
Biến thể của học ganh đua mà chúng ta xét ở đây đôi khi được gọi là học ganh đua đơn điệu, liên quan đến việc học trong mạng neural một lớp. Các đơn vị đầu vào trong mạng có các giá trị liên quan đến lĩnh vực đang xét, và k đơn vị đầu ra thể hiện k lớp ví dụ đầu vào được phân cụm.
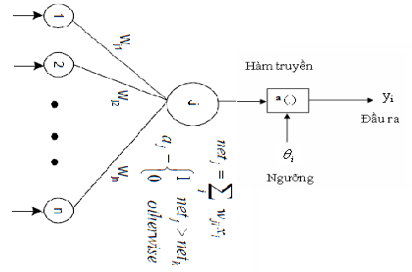
- Hình 3: Đơn vị (neural) xử lý ganh đua
Giá trị đầu vào cho mỗi đầu ra trong phương pháp này là một tổ hợp tuyến tính của các đầu vào:
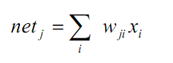 Trong đó:
Trong đó:
xi là đầu vào thứ i; i = 1,2,…,n.
wji là trọng số liên kết đầu vào thứ i với đầu ra thứ j, j = 1,2, …,m.
Gọi S(netj ) là hàm chuyển tín hiệu (hàm tương tác hay hàm kích hoạt đầu ra), có thể là hàm đơn điệu không giảm liên tục như hàm Sigmoid hoặc hàm bước nhẩy đơn vị sau:
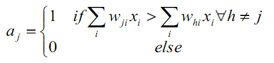 Đơn vị đầu ra có giá trị đầu vào lớn nhất được coi là chiến thắng, và kích hoạt đó được coi bằng 1 (thắng cuộc), còn các kích hoạt khác của các đầu ra còn lại được cho bằng 0 (thua cuộc). Quá trình như vậy được gọi là ganh đua.
Quá trình huấn luyện cho học ganh đua liên quan đến hàm chi phí:
Đơn vị đầu ra có giá trị đầu vào lớn nhất được coi là chiến thắng, và kích hoạt đó được coi bằng 1 (thắng cuộc), còn các kích hoạt khác của các đầu ra còn lại được cho bằng 0 (thua cuộc). Quá trình như vậy được gọi là ganh đua.
Quá trình huấn luyện cho học ganh đua liên quan đến hàm chi phí:
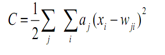 Trong đó:
Trong đó:
aj là kích hoạt của đầu ra thứ j.
xi là đầu vào thứ i.
wji là trọng số từ đầu vào thứ i với đầu ra thứ j.
Luật cập nhật các trọng số là:
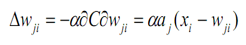 với α là hằng số, chỉ tốc độ học.
với α là hằng số, chỉ tốc độ học.
Ý tưởng chính của học ganh đua là đối với mỗi đầu ra là lấy ra “độ tin cậy” cho tập con các ví dụ huấn luyện. Chỉ một đầu ra là chiến thắng trong số ví dụ đưa ra, và vectơ trọng số cho đơn vị chiến thắng được di chuyển về phía vectơ đầu vào. Giống như quá trình huấn luyện, vectơ trọng số của mỗi đầu ra di chuyển về phía trung tâm của các ví dụ. Huấn luyện xong, mỗi đầu ra đại diện cho một nhóm các ví dụ, và vectơ trọng số cho các đơn vị phù hợp với trọng tâm của các nhóm. Học ganh đua có liên quan mật thiết với phương pháp thống kê nổi tiếng như là phương pháp phân cụm K thành phần chính. Khác nhau cơ bản giữa hai phương pháp là học ganh đua là phương pháp trực tuyến, nghĩa là trong suốt quá trình học nó cập nhập trọng số mạng sau mỗi ví dụ được đưa ra, thay vì sau tất cả các ví dụ được đưa ra như được làm trong phương pháp phân cụm K thành phần chính. Học ganh đua phù hợp với các tập dữ liệu lớn, vì các thuật toán trực tuyến thường có giải pháp nhanh hơn trong mọi trường hợp.
3. Thuật toán SOM
Về bản chất, SOM được biết đến như một kỹ thuật nén dữ liệu dựa trên vecto trọng số (trực quan hóa dữ liệu).
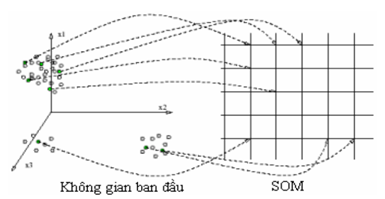
- Hình 4: Không gian ban đầu và không gian sau khi thực hiện thuật toán SOM
Input: Dữ liệu huấn luyện gồm tập n vectơ: V={V1, V2, …, Vi, …, Vn}, mỗi vectơ ứng với một neural (nút) đầu vào; Trong đó, mỗi vecto Vi gồm p chiều: Vi={v1, v2, …, vp}.
Khởi tạo tham số số lần lặp t=1
Bước 1: Khởi tạo vecto trọng số cho mỗi neural
Tương ứng với mỗi vector Vi, vecto trọng số Wi cũng gồm p chiều Wi={w1, w2, …, wp}
Và tập vector trọng số có m bộ: W={W1, W2, …, Wi, …, Wm}
Bước 2: Chọn ngẫu nhiên một vecto Vi ϵ V làm mẫu huấn luyện
Bước 3: Tìm mẫu khớp tốt nhất BMU (Best Matching Unit)–phần tử neural chiến thắng
Tìm phần tử khớp nhất giữa các vecto trọng số Wi𝜖W và vecto đầu vào Vi. Neural nào có vecto trọng số Wi gần với vecto đầu vào Vi nhất thì neural đó được chọn là BMU.
Để xác định BMU, ta tính khoảng cách Euclid giữa các vecto trọng số Wi với vecto Vi chọn ở Bước 2 theo công thức sau:
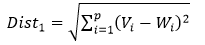
Trong đó:
Dist1: khoảng cách giữa vecto trọng số Wi và vecto đầu vào Vi
V_i: vecto đầu vào đang xét
W_i: vecto trọng số của phần tử được chọn
Dist1 min thì neural có vecto trọng số tương ứng được chọn là BMU.
Bước 4: Xây dựng các phần tử lân cận
Bước này sẽ xác định các neural nào thuộc vùng lân cận của BMU. Để xác định vùng lân cận của BMU, tính bán kính lấy tâm là BMU tới các neural còn lại, gọi là bán kính lân cận. Neural nào có khoảng cách tới BMU nằm trong bán kính lân cận thì neural đó là phần tử lân cận của BMU. Bán kính lân cận được xác định lớn nhất thường là bán kính tính theo kích thước của mạng, nhưng sau đó giá trị này sẽ giảm dần sau một số bước thực hiện.
Bán kính lân cận của BMU tại thời điểm t được xác định bằng công thức:
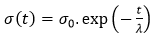 trong đó:
σ(t): bán kính lân cận của BMU tại thời điểm t.
σ0: bán kính lân cận của BMU tại thời điểm t0 và được tính bằng công thức: σ0= $ \frac{max(width,height)}{2} $
Width: chiều rộng mạng Kohonen (do người dùng tự định nghĩa).
Height: chiều dài mạng Kohonen (do người dùng tự định nghĩa).
t: bước lặp hiện tại.
λ: hằng số thời gian. Trong đó: λ= $ \frac{N}/{log(σ0)} $
N: số lần lặp để chạy thuật toán.
trong đó:
σ(t): bán kính lân cận của BMU tại thời điểm t.
σ0: bán kính lân cận của BMU tại thời điểm t0 và được tính bằng công thức: σ0= $ \frac{max(width,height)}{2} $
Width: chiều rộng mạng Kohonen (do người dùng tự định nghĩa).
Height: chiều dài mạng Kohonen (do người dùng tự định nghĩa).
t: bước lặp hiện tại.
λ: hằng số thời gian. Trong đó: λ= $ \frac{N}/{log(σ0)} $
N: số lần lặp để chạy thuật toán.
Sau khi tính được bán kính lân cận, ta tính khoảng cách từ BMU tới các neural còn lại để xác định neural nào là phần tử lân cận của BMU. Nếu khoảng cách đó nhỏ hơn bán kính thì neural tương ứng là phần tử lân cận của BMU.
Khoảng cách từ BMU tới các neural được tính theo công thức Euclid:
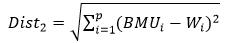 Dist2: khoảng cách từ BMU tới các neural còn lại.
Dist2: khoảng cách từ BMU tới các neural còn lại.
Các phần tử lân cận bao gồm BMU sẽ được cập nhật lại trọng số ở bước tiếp theo.

- Hình 4 13: Bán kính lân cận và phần tử lân cận sau một số lần lặp
Bước 5: Hiệu chỉnh trọng số các phần tử lân cận – Quá trình học của SOM
Trọng số của các phần tử lân cận đã xác định ở bước 4 bao gồm cả BMU sẽ được hiệu chỉnh để chúng có giá trị gần giống với giá trị của vecto đầu vào đang xét.
Các vecto trọng số được hiệu chỉnh theo công thức:
W(t+1)=W(t) + θ(t)L(t)(V(t)-W(t))
trong đó:
W(t+1): vecto trọng số tại bước lặp (t+1).
W(t): vecto trọng số tại bước lặp t.
θ(t): hàm nội suy theo thời gian học, nó thể hiện sự tác động của khoảng cách đối với quá trình học.
Hàm nội suy θ(t) được tính theo công thức:
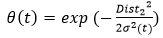 Trong đó:
Dist2: khoảng cách từ BMU tới các phần tử lân cận.
L(t): hàm nội suy tốc độ học cho mỗi bước lặp được tính theo công thức:
Trong đó:
Dist2: khoảng cách từ BMU tới các phần tử lân cận.
L(t): hàm nội suy tốc độ học cho mỗi bước lặp được tính theo công thức:
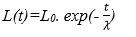 L0: giá trị khởi tạo ban đầu của tốc độ học.
Tốc độ học được nội suy dần sau một số lần lặp và giá trị của hàm sẽ tiền dần về 0 khi số lần lặp đạt tới những bước cuối cùng.
Bước 6: Tăng t, lấy mẫu huấn luyện tiếp theo
Lặp lại bước 2 cho đến giải thuật tối ưu tức
L0: giá trị khởi tạo ban đầu của tốc độ học.
Tốc độ học được nội suy dần sau một số lần lặp và giá trị của hàm sẽ tiền dần về 0 khi số lần lặp đạt tới những bước cuối cùng.
Bước 6: Tăng t, lấy mẫu huấn luyện tiếp theo
Lặp lại bước 2 cho đến giải thuật tối ưu tứcW(t+1)=W(t)hoặc đạt đến số lần lặp xác định N cho trước (t = N). Thuật toán dừng khi thực hiện đủ số lần lặp hoặc không có sự thay đổi nào của các vecto trọng số.
Quá trình thực hiện thuật toán SOM được tóm tắt như sau:
Bước 1: Khởi tạo giá trị cho các vecto trọng số.
Bước 2: Chọn một vecto từ tập vecto đầu vào.
Bước 3: Tìm mẫu khớp tốt nhất (Best Matching Unit - BMU)
Tính toán khoảng cách giữa vecto đầu vào với tất cả các vecto trọng số theo công thức Euclid:
Dist min thì neural có vecto trọng số tương ứng được chọn làm BMU
Bước 4: Tìm các phần tử lân cận.
Bước 5: Cập nhật lại trọng số của các phần tử lân cận và BM W(t+1)=W(t) + θ(t)L(t)(V(t)-W(t))
Bước 6: Tăng t, lặp tiếp bước 2.
4. SOM với bài toán phân cụm
Với khả năng mạnh mẽ trong việc biểu diễn dữ liệu từ không gian nhiều chiều về không gian ít chiều hơn mà vẫn có thể bảo tồn được quan hệ hình trạng của dữ liệu trong không gian đầu vào, nên chức năng chính của SOM là trình diễn cấu trúc của toàn bộ tập dữ liệu và giúp quan sát trực quan cấu trúc cũng như sự phân bố tương quan giữa các mẫu dữ liệu trong không gian của tập dữ liệu. Do đó, SOM được ứng dụng rất nhiều trong các bài toán thực tế, từ những bài toán có tính chất nền tảng của khai phá dữ liệu như phân cụm, phân lớp cho tới những bài toán ứng dụng trong các lĩnh vực khác. Cụ thể, từ năm 1980 đến nay, đã có hàng nghìn bài báo, công trình nghiên cứu liên quan đến SOM, được liệt kê trong các “Bibliography of selforganizing map (SOM) papers. Trong những năm gần đây, có thể kể ra một số nghiên cứu ứng dụng SOM đại diện trong các lĩnh vực như: thị giác máy và phân tích ảnh, nhận dạng và phân tích tiếng nói, phân tích dữ liệu y tế, xử lý tín hiệu trong viễn thông, công nghiệp và các dữ liệu thế giới thực khác, xử lý dữ liệu video giao thông, xử lý các loại dữ liệu liên tục theo thời gian...
SOM là phương pháp phân cụm theo cách tiếp cận mạng neural và thuật toán học ganh đua. Vectơ trọng số của ma trận SOM chính là trọng tâm cụm, việc phân cụm có thể cho kết quả tốt hơn bằng cách kết hợp các đơn vị trong ma trận để tạo thành các cụm lớn hơn. Một điểm thuận lợi của phương pháp này là vùng Voronoi của các đơn vị ma trận là lồi, bằng cách kết hợp của một số đơn vị trong ma trận với nhau tạo nên các cụm không lồi. Việc sử dụng các độ đo khoảng cách khác nhau và các chuẩn kết liên kết khác nhau có thể tạo thành các cụm lớn hơn.
Ma trận khoảng cách: chiến lược chung trong phân cụm các đơn vị của SOM là tìm ma trận khoảng cách giữa các vectơ tham chiếu và sử dụng giá trị lớn trong ma trận như là chỉ số của đường biên cụm. Trong không gian ba chiều, các cụm sẽ được thể hiện như “các thung lũng”. Vấn đề là làm sao để quyết định các đơn vị trong ma trận thuộc về một cụm nào đó cho trước.
Để giải quyết được vấn đề này, người ta thường sử dụng thuật toán tích tụ (Agglomerative Algorithm), gồm các bước:
- Quy cho mỗi đơn vị trong ma trận một cụm riêng.
- Tính toán khoảng cách giữa tất cả các cụm.
- Ghép hai cụm gần nhất.
- Nếu số cụm tồn tại bằng số cụm do người dùng định nghĩa trước thì dừng, nếu không lặp lại từ bước 2.
SOM cũng được áp dụng trong phân cụm tập dữ liệu không chuẩn hoá. Dùng luật của học ganh đua, vectơ trọng số có thể điều chỉnh theo hàm phân bố xác suất của các vectơ đầu vào. Sự tương đồng giữa vectơ đầu vào x và vectơ trọng số w được tính toán bằng khoảng cách Ơclit. Trong suốt quá trình huấn luyện một vectơ trọng số wj tuỳ ý được cập nhập tại thời điểm t là:
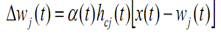 Với
Với
- $ \alpha(t) $ là tỷ lệ học giảm dần trong quá trình huấn luyện
hci(t)là hàm lân cận giữa vectơ trọng số chiến thắngwcvà vectơ trọng sốwj,hci(t)cũng giảm dần trong quá trình huấn luyện. Mối quan hệ lân cận được xác định bằng cấu trúc hình học và mối quan hệ này cố định trong suốt quá trình học.
Kết thúc quá trình học, điều chỉnh lại bán kính lân cận đủ nhỏ để cập nhập lại cho các vectơ trọng số chiến thắng wc và các lân cận gần chúng nhất. Đối với cấu trúc một chiều nó có thể được biểu diễn bằng luật huấn luyện. Công thức trên là một sấp xỉ của hàm đơn điệu của phân bố xác suất trên các vectơ đầu vào. Trong cấu trúc hai chiều thì kết quả trả về là một sự tương quan giữa độ xấp xỉ và bình phương lỗi tối thiểu của vectơ lượng tử. Ưu điểm, nhược điểm của thuật toán SOM
-
Ưu điểm
- Rất dễ hiểu, cài đặt đơn giản và làm việc rất tốt.
- Biểu diễn trực quan dữ liệu đa chiều vào không gian ít chiều hơn và đặc trưng của dữ liệu được giữ lại trên bản đồ.
- Hiệu quả trong quá trình phân tích đòi hỏi trí thông minh để đưa ra quyết định nhanh chóng. Nó giúp cho người phân tích hiểu vấn đề hơn trên một tập dữ liệu tương đối lớn.
- Xác định các cụm dữ liệu giúp cho việc tối ưu phân bổ nguồn lực
=> Thuật toán SOM được ứng dụng rất nhiều trong nhận dạng tiếng nói, điều khiển tự động, hóa-sinh trắc học, phân tích tài chính và xử lý ngôn ngữ tự nhiên…
-
Nhược điểm
- Chi phí cho việc tính toán lớn khi số chiều của dữ liệu tăng lên
- Việc xác định ranh giới giữa các nhóm trên lớp ra Kohonen gặp nhiều khó khăn, trong trường hợp dữ liệu biến thiên liên tục, sự phân chia giữa các nhóm là rất nhỏ.
- Khối lượng tính toán là tương đối lớn, do vậy tốc độ xử lý của giải thuật cũng là một thách thức cần xét tới.
VD: Xét một mạng Kohonen sử dụng thuật toán SOM với kích thước 20x30=600 neural, độ phân giải bức ảnh đầu vào được tính bằng đơn vị megapixel tức là có tới hàng triệu điểm ảnh. Như vậy, riêng trong quá trình huấn luyện, việc tìm BMU đã phải duyệt qua khoảng 600 triệu lần các neural mà chưa tính đến các phép tính khoảng cách, so sánh, cập nhật trọng số…
- Mỗi lần chạy thuật toán SOM, ta đều tìm thấy độ tương tự khác nhau giữa các vecto mẫu. Các vecto mẫu thường được bao quanh bởi mẫu tương tự, tuy nhiên các mẫu tương tự không phải lúc nào cũng gần nhau. Nếu có rất nhiều sắc thái màu tím, không phải lúc nào cũng thu được một tập lớn tất cả các màu tìm trong một cụm, đôi khi các cụm sẽ phân chia và sẽ có hai nhóm màu tím. Sử dụng dữ liệu màu sắc, ta có thể nói hai cụm dữ liệu này là tương tự nhưng với hầu hết các dữ liệu khác, hai cụm trông hoàn toàn không liên quan tới nhau. Vì vậy, cần lưu ý rất nhiều để xây dựng được một bản đồ tốt cuối cùng.
All rights reserved
