[Machine Learning] Sự ảnh hưởng của Features tới Performance của Model
Tầm quan trọng của Features trong hiệu suất của Model
Khi bước chân vào lĩnh vực khoa học dữ liệu, chúng ta thường bị cuốn hút bởi những thuật toán phức tạp và mạnh mẽ như Deep Learning hay Neural Networks. Một câu hỏi thường được đặt ra là làm thế nào để tối ưu hóa các tham số để đạt được kết quả tốt nhất. Tuy nhiên, các nhà nghiên cứu và thực hành lâu năm lại nhận thấy rằng, sự thành bại của một mô hình đôi khi không nằm ở thuật toán, mà nằm ở chính dữ liệu đầu vào. Chúng ta tạm gọi thành phần cốt lõi này là Features(Đặc trưng). Hay nói một cách tường minh hơn, đó là cách chúng ta "biểu diễn" dữ liệu để máy tính có thể hiểu và học được.
Trong cộng đồng Data Science, có một nguyên lý bất di bất dịch: "Garbage In, Garbage Out". Điều này dẫn dắt chúng ta đến việc xem xét lại vai trò của Features so với thuật toán.
Bản chất của Features và Thuật toán
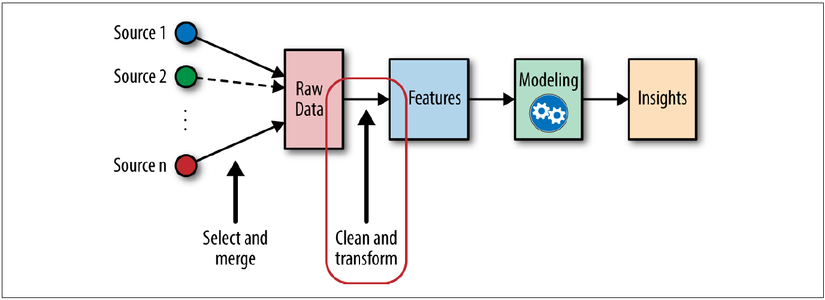
Để dễ hình dung, chúng ta có thể lấy ví dụ về việc nấu ăn. Nếu xem quá trình tạo ra một món ăn ngon là việc xây dựng một model có độ chính xác cao, thì thuật toán(Algorithm) chính là công thức nấu ăn hay kỹ năng của người đầu bếp. Trong khi đó, Features chính là các nguyên liệu đầu vào.
Dù cho người đầu bếp có kỹ năng thượng thừa đến đâu (sử dụng các thuật toán tối tân nhất), nhưng nếu nguyên liệu đầu vào kém chất lượng, ôi thiu (Features tồi, nhiễu), thì thành phẩm không thể nào đạt chuẩn. Ngược lại, nếu nguyên liệu tươi ngon và được sơ chế kỹ lưỡng (Features tốt), thì ngay cả một công thức nấu ăn đơn giản cũng có thể tạo ra một món ăn chấp nhận được. Điều này cho thấy tầm quan trọng mang tính nền tảng của việc lựa chọn và xử lý đặc trưng.
Sự biểu diễn dữ liệu (Data Representation)
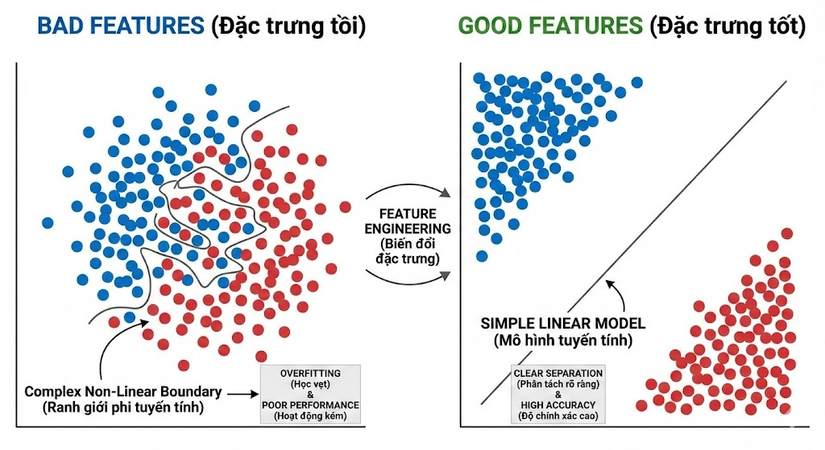
Như hình ảnh minh họa về các điểm xanh và đỏ, chúng ta thấy rõ sự khác biệt giữa hai cách biểu diễn dữ liệu.
Trong trường hợp các điểm dữ liệu nằm xen kẽ, chồng chéo lên nhau, chúng ta gọi đây là Bad Features(Đặc trưng tồi). Lúc này, bài toán phân loại trở nên cực kỳ phức tạp. Model sẽ phải nỗ lực rất nhiều để vẽ ra một đường ranh giới phi tuyến tính ngoằn ngoèo nhằm phân tách các điểm này. Điều này thường dẫn đến việc model hoạt động kém hiệu quả hoặc rơi vào trạng thái Overfitting(Học vẹt) – tức là học cả những nhiễu loạn của dữ liệu thay vì quy luật chung.
Ngược lại, hãy nhìn vào trường hợp Good Features(Đặc trưng tốt). Bằng một số phương pháp biến đổi không gian dữ liệu (Feature Engineering), các điểm cùng loại được gom cụm lại với nhau một cách rõ ràng. Lúc này, vấn đề trở nên đơn giản hơn rất nhiều. Chúng ta chỉ cần một đường kẻ thẳng (Linear Model) là có thể phân loại chính xác tuyệt đối.
Tại sao Features lại quyết định hiệu suất (Performance)?
Một mô hình máy học, về bản chất, không hiểu được ngữ nghĩa của dữ liệu như con người. Chúng chỉ làm việc với các con số và vector. Do đó:
- Đơn giản hóa bài toán: Features tốt giúp biến đổi một bài toán phức tạp thành bài toán đơn giản. Nó làm nổi bật các thông tin quan trọng(Signal) và giảm thiểu nhiễu(Noise), giúp thuật toán dễ dàng tìm ra quy luật.
- Cải thiện độ chính xác và tốc độ: Khi dữ liệu được biểu diễn tốt, model hội tụ nhanh hơn và đạt độ chính xác cao hơn mà không cần tiêu tốn quá nhiều tài nguyên tính toán.
- Khả năng giải thích (Interpretability): Việc xây dựng features dựa trên kiến thức miền(Domain Knowledge) giúp chúng ta hiểu được tại sao model lại đưa ra dự đoán đó, thay vì coi nó như một hộp đen(Black box).
Kết luận
Thay vì dành toàn bộ thời gian để tinh chỉnh các siêu tham số của thuật toán, các kỹ sư dữ liệu nên tập trung nhiều hơn vào Feature Engineering. Một mô hình đơn giản với dữ liệu được biểu diễn tốt (Good representation) sẽ luôn hiệu quả hơn một mô hình phức tạp nhưng phải xử lý dữ liệu hỗn độn. Đó chính là chìa khóa để xây dựng các hệ thống AI bền vững và hiệu quả.
Cám ơn các bạn đã đọc hết bài viết của mình nhé!
All rights reserved
