[Machine Learning] Nghệ thuật xử lý Numeric Data trong Machine Learning
Nghệ thuật xử lý Numeric Data trong Machine Learning
Trong lịch sử phát triển của toán học và khoa học máy tính, con số luôn là ngôn ngữ cơ bản nhất để mô tả thế giới. Từ những phép đo đạc thiên văn cổ đại cho đến các ma trận phức tạp trong Deep Learning ngày nay, Numeric Data (Dữ liệu số) đóng vai trò như xương sống của hầu hết các mô hình định lượng. Tuy nhiên, việc đưa các con số thô vào mô hình Machine Learning đôi khi không đơn giản như chúng ta nghĩ. Một câu hỏi thú vị được đặt ra: Liệu con số "100" ở cột A có giá trị tương đương với con số "100" ở cột B trong mắt của thuật toán?
Hôm nay, chúng ta sẽ đi sâu vào bản chất của dữ liệu số và cách "cư xử" với chúng để mô hình đạt hiệu suất tối ưu.
1. Thế nào là một Good Feature trong dữ liệu số?
Chúng ta thường nghe nói về việc thu thập càng nhiều dữ liệu càng tốt. Nhưng trong Feature Engineering, chất lượng quan trọng hơn số lượng. Một Good Feature (Đặc trưng tốt) không đơn thuần chỉ là đại diện cho một khía cạnh quan trọng của dữ liệu (như tuổi tác, thu nhập), mà quan trọng hơn, nó phải mang theo chiều hướng kết quả của đầu ra (Output Target).
Nói một cách tường minh, một feature tốt phải chứa "tín hiệu" (signal) giúp phân biệt các mẫu dữ liệu. Ví dụ, trong bài toán dự đoán giá nhà, "diện tích sàn" là một feature tốt vì nó có tương quan tuyến tính rõ ràng với giá nhà (target): diện tích tăng thì giá thường tăng. Ngược lại, "mã số căn hộ" dù cũng là số, nhưng nó không mang theo chiều hướng dự đoán nào cho giá cả, và do đó là một feature tồi (thậm chí là nhiễu).
2. Tính Scale (Quy mô) và sự nhạy cảm của mô hình
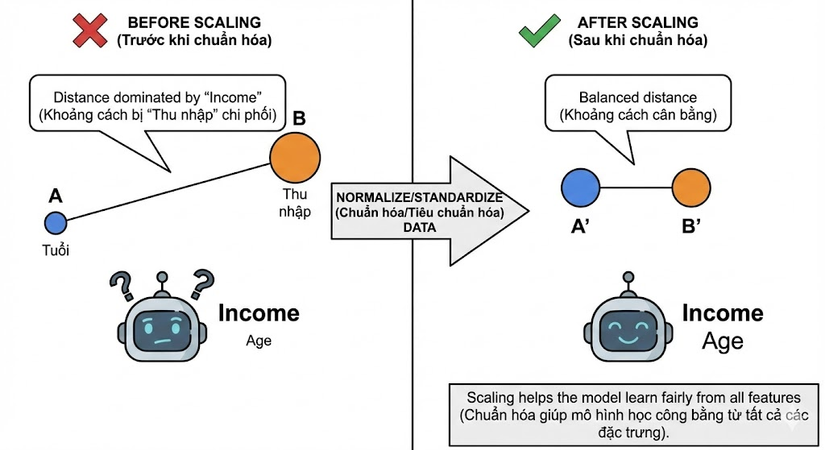
Một vấn đề kinh điển khi làm việc với Numeric Data là sự chênh lệch về đơn vị đo lường, hay còn gọi là Scale. Hãy tưởng tượng chúng ta có hai biến số: "Thu nhập" (đơn vị hàng triệu đồng, ví dụ: 20,000,000) và "Tuổi" (đơn vị năm, ví dụ: 30).
Đối với các mô hình dựa trên khoảng cách như K-Nearest Neighbors (KNN), K-Means, hay các thuật toán sử dụng Gradient Descent (như Linear Regression, Neural Networks), sự chênh lệch này là chí mạng. Các thuật toán này thường sử dụng Euclidean distance (Khoảng cách Euclid) để đo độ tương đồng giữa các điểm dữ liệu. Vì biến "Thu nhập" có giá trị tuyệt đối lớn hơn rất nhiều so với "Tuổi", khoảng cách Euclid sẽ bị chi phối hoàn toàn bởi "Thu nhập", khiến biến "Tuổi" trở nên vô nghĩa trong mắt thuật toán.
Để giải quyết vấn đề này, các kỹ sư dữ liệu bắt buộc phải thực hiện Normalize (Chuẩn hóa) hoặc Standardize (Tiêu chuẩn hóa) dữ liệu, đưa tất cả các biến về cùng một miền giá trị (thường là [0, 1] hoặc phân phối chuẩn với mean=0, std=1) để đảm bảo tính công bằng giữa các features.
3. Ngoại lệ: Logical Functions và Decision Tree
Tuy nhiên, không phải thuật toán nào cũng "sợ" sự chênh lệch về scale. Có một nhóm các mô hình dựa trên Logical functions (Hàm logic), mà đại diện tiêu biểu là Decision Tree (Cây quyết định) và các biến thể của nó (Random Forest, XGBoost).
Decision Tree hoạt động bằng cách đặt ra các câu hỏi cắt lớp dữ liệu, ví dụ: "Tuổi > 30?" hay "Thu nhập > 10 triệu?". Bản chất của việc này là các phép so sánh (thresholding) trên từng feature độc lập. Việc bạn nhân đôi giá trị của cột "Thu nhập" hay chia nó cho 10 không làm thay đổi cấu trúc của cây hay kết quả của phép so sánh (miễn là thứ tự của dữ liệu được giữ nguyên). Do đó, các mô hình dạng cây có đặc tính Scale Invariant (Bất biến với quy mô), giúp giảm bớt gánh nặng tiền xử lý (Preprocessing) cho người xây dựng mô hình.
4. Sự phân bổ (Distribution) và Target Engineering
Cuối cùng, một khía cạnh tinh tế nhưng thường bị bỏ qua là hình dạng phân bổ của dữ liệu số (Distribution of numeric features).
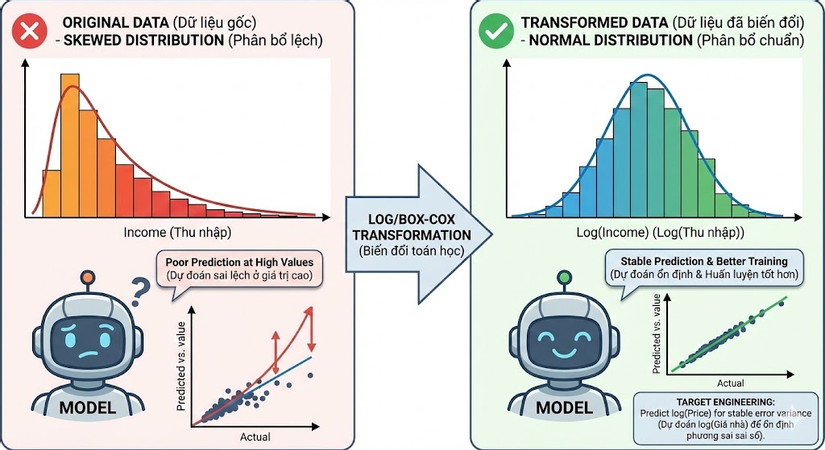
Nhiều thuật toán thống kê (như Linear Regression) hoạt động tốt nhất khi dữ liệu tuân theo phân phối chuẩn (Gaussian distribution) - hình quả chuông đối xứng. Tuy nhiên, dữ liệu thực tế (như thu nhập tài chính, lượt view website) thường bị lệch (skewed), với phần đuôi dài (long tail). Việc để nguyên dữ liệu bị lệch này có thể khiến mô hình dự đoán sai lệch lớn ở các giá trị cao.
Giải pháp ở đây là áp dụng các phép biến đổi toán học (Transform), phổ biến nhất là Log Transformation hoặc Box-Cox Transformation, để "ép" dữ liệu về dạng phân phối chuẩn hơn.
Không chỉ áp dụng cho features đầu vào, tư duy này còn áp dụng cho cả biến mục tiêu (output), gọi là Target Engineering. Ví dụ, thay vì dự đoán trực tiếp giá nhà (một số rất lớn và biến động mạnh), chúng ta có thể dự đoán log(giá nhà). Việc này giúp ổn định phương sai của sai số (variance of errors), làm cho quá trình huấn luyện mô hình trở nên trơn tru và hội tụ tốt hơn.
Kết luận
Làm việc với Numeric Data không chỉ là đưa những con số vào máy tính. Đó là việc thấu hiểu bản chất toán học của từng thuật toán để có cách đối xử phù hợp với từng feature. Từ việc chuẩn hóa scale cho khoảng cách Euclid đến việc biến đổi phân phối cho hồi quy tuyến tính, mỗi bước xử lý đều góp phần quyết định sự thành bại của hệ thống AI.
Cám ơn các bạn đã xem hết bài viết của mình!
All rights reserved
