m0lecon CTF 2020 Teaser Crypto Writeup
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Xin chào các bạn, lại là mình, một người không biết gì nhưng vẫn thích chơi CTF đây  Hôm nay mình có được rủ chơi vòng loại m0lecon CTF 2020, và mình quyết định làm các câu thuộc chủ đề mình thích, đó là Crypto! Trong đó, đề có 5 bài Crypto, và mình chỉ làm được 3 — bài rand-the-m0le có reverse và bạn team RE của mình MIA, và bài King Exchange thì sử dụng Elliptic Curve Cryptography, và phần này thì mình lười quá chưa học (^^;) Vậy bài này sẽ writeup 3 (thực ra là 2) bài mình làm được nhé!
Hôm nay mình có được rủ chơi vòng loại m0lecon CTF 2020, và mình quyết định làm các câu thuộc chủ đề mình thích, đó là Crypto! Trong đó, đề có 5 bài Crypto, và mình chỉ làm được 3 — bài rand-the-m0le có reverse và bạn team RE của mình MIA, và bài King Exchange thì sử dụng Elliptic Curve Cryptography, và phần này thì mình lười quá chưa học (^^;) Vậy bài này sẽ writeup 3 (thực ra là 2) bài mình làm được nhé!
Kid Exchange
Đề bài
In our super secret agency we don't trust standard protocols. We even have our own way to trade keys! I bet you won't find any issue
Author: @matpro
Source files: https://github.com/ngoctnq-1957/m0lecon-2017-crypto-source/tree/master/Kid Exchange
Tìm hiểu
Nhìn nhanh thì bạn có thể thấy đây là một cặp server/client trao đổi key exchange. Không chần chừ gì nữa, nhảy luôn vào toán nào!
Mỗi bên generate ra 4 số 128-bit ngẫu nhiên, nhưng thực ra sau khi nhân modulo xong thì chỉ còn 2 giá trị bí mật là và thôi.
n = 128
m = 2**n
x = [int.from_bytes(os.urandom(n//8),'big') for _ in range(4)] #private key
e1 = (x[0] * x[1]) % m
e2 = (x[2]**2 + 3 * x[3]) % m
Và 2 giá trị public được gửi đi cho người còn lại để tạo ra cặp key đối xứng:
p1 = (e1**2 - 2 * e1 * e2 + 2 * e2**2) % m
p2 = (e1 * e2) % m
Sau 2 dòng gửi tiếp theo, mỗi người có 2 giá trị bí mật của mình, và 2 giá trị công cộng của đằng kia. Thay vì gọi p3 và p4 như trong code, mình chọn để giá trị đó là và — các giá trị có "phẩy" là các giá trị của người còn lại.
Trước khi tiếp tục, chúng ta cần chứng minh một bổ đề nho nhỏ:
Bổ đề:
Chứng minh: để mình gạch đầu dòng ra cho dễ theo dõi (giáo viên chủ nhiệm toán của mình mà thấy bài này chắc không nhìn mặt mình nữa luôn):
- Theo hàm phi Euler, ta có:
- Theo định lý Euler, ta có
với mọi giá trị của , sao cho . Từ đó ta có
Từ bổ đề trên ta sẽ có biểu thức sau, giúp mình có thể viết tắt tắt đi chút và bỏ qua toàn bộ modulo (^^;) Các phép toán trở về sau sẽ được thực hiện vành :
Để chứng minh độ chính xác của thuật toán và hiểu được cơ chế trao đổi key này hoạt động như thế nào, chúng ta nghiên cứu các dòng tiếp theo:
e3 = (p3 + 4 * p4) % m
e4 = pow(3, p3 * e3, m)
Chúng ta tạm thời chỉ quan tâm và xử lý luỹ thừa trước:
e5 = pow(e1, 4, m)
e6 = pow(e2, 4, m)
e7 = (e5 + 4 * e6) % m
Ba dòng trên tóm tắt lại gọn gàng thành:
Bạn bắt đầu thấy sự đối xứng rồi đúng không
k = pow(e4, e7, m)
Và key đối xứng được tính ra bằng cách:
Lời giải
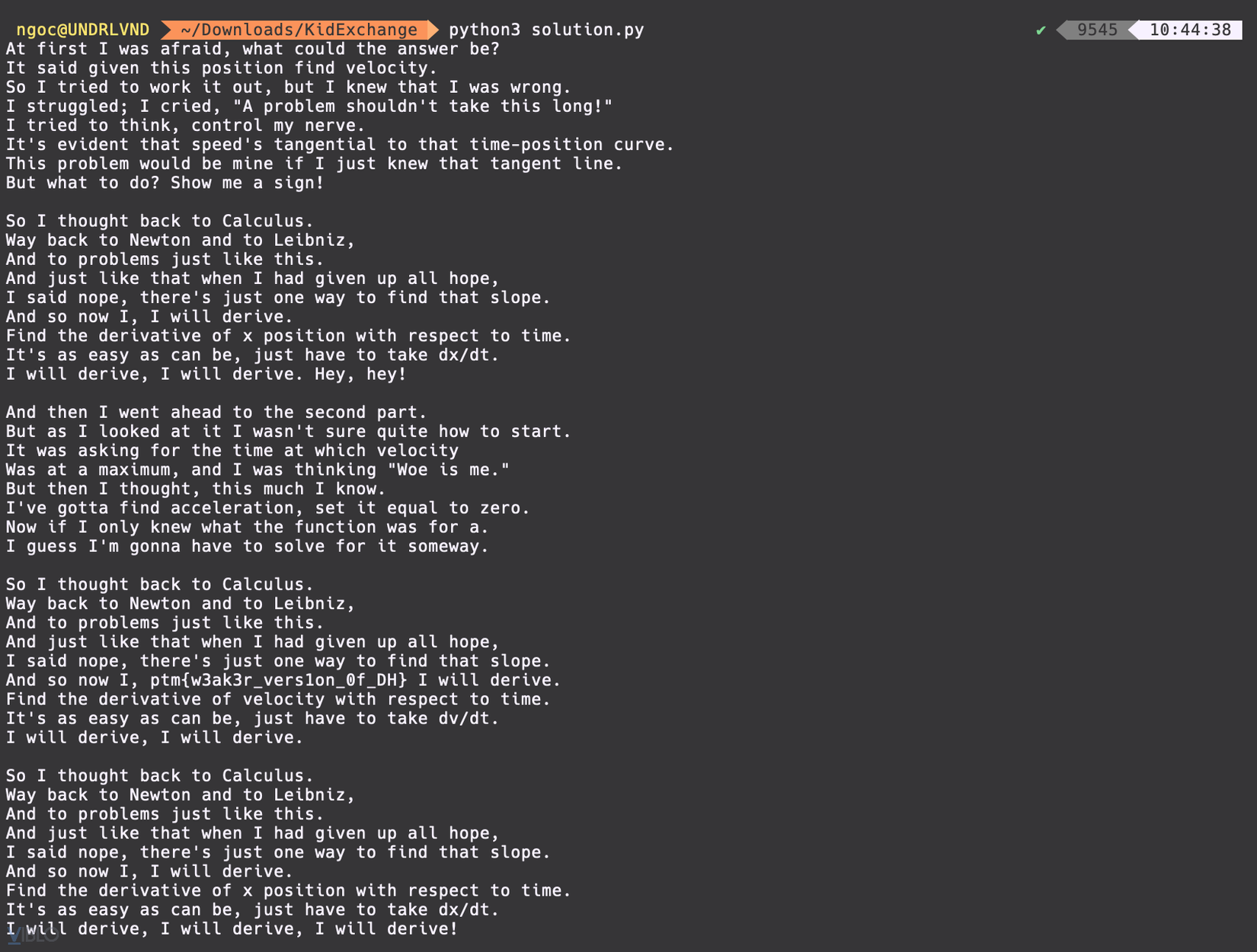
Oke ra được công thức key đối xứng rồi, nhưng toàn giá trị bí mật thì làm sao bây giờ? Để ý phương trình , ta có:
Giờ thì toàn giá trị public rồi, còn chờ gì nữa mà không lấy các giá trị , , , , và ciphertext từ trong network traffic capture file capture.pcapng để ăn điểm nào:
mod = 2 ** 128
pub1 = (p1 ** 2 + 4 * p1 * p2) % mod
pub2 = (p3 ** 2 + 4 * p3 * p4) % mod
k = pow(3, pub1 * pub2, mod)
key = int.to_bytes(k, 16, 'big')
from Crypto.Cipher import AES
cipher = AES.new(key, AES.MODE_ECB)
print(cipher.decrypt(flag).decode())
Và lấy flag thôi!
Cryptogolf (1&2)
Thực ra bài này là 1 đề chia 2 flag, với yêu cầu số query cần sử dụng cho Lv. 2 thấp hơn nhiều so với Lv. 1. Trước khi có hint đó thì mình giải được với 30 queries rồi nên ¯\_(ツ)_/¯
Đề bài
After the golf.so challenge at PlaidCTF and the golf category at DEFCON CTF Quals, here we are with our very own golf challenge!
nc challs.m0lecon.it 11000
Note: this challenge has two flags, check CryptoGolf 2.0 if you recovered the second one
Hint: the limits for the two flags are 128 and 45 requests.
Author: @mr96
Source files: https://github.com/ngoctnq-1957/m0lecon-2017-crypto-source/tree/master/cryptogolf
Tìm hiểu
Bài này thực ra khá là lằng nhằng nên chúng ta sẽ tìm hiểu từng hàm một nhé!
- Bắt đầu là hàm padding:
def pad(s):
m = 192 - len(s)
return s + hex(m%16)[2:]*m
Thực ra hàm này không cần thiết: thay vì để server tự động pad, mình có thể chủ động pad theo ý mình, cho đủ 192 hex digits (96 bytes) là được (vì lúc đó sẽ không có block pad riêng ở cuối như PKCS#5/7). Tuy nhiên, cho đầy đủ mình sẽ giải thích: tương tự với PKCS#5/7, hàm sẽ tìm số ký tự cần pad, mod với 16 để giá trị vừa đủ trong 0-9A-F, và lấy đó làm ký tự ghi pad cuối chuỗi đến lúc đủ 192 chữ cái.
- Tiếp đến là hàm xáo trộn:
secret = numpy.random.permutation(128)
...
def apply_secret(c):
r = bin(c)[2:].rjust(128,'0')
return int(''.join([str(r[i]) for i in secret]), 2)
Tương tự với các hàm có xáo trộn như AES, hàm này, với một permutation có trước làm key bí mật, sẽ lấy vào 128-bit, và xáo các bit đó lên theo key. Nếu coi secret là một bảng lưu kết quả của permutation mapping , thì chuỗi kết quả ở vị trí sẽ có giá trị ở vị trí của chuỗi gốc.
Lưu ý: ký hiện sẽ được sử dụng ở phần dưới phần lời giải.
- Và cuối cùng là hàm mã hoá:
def encrypt(s):
s = pad(s)
to_encrypt = int(s, 16)
for _ in range(9):
x = apply_secret(to_encrypt >> 640)
to_encrypt = (((x^to_encrypt) & 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF) << 640) | (to_encrypt >> 128)
return hex(to_encrypt)[2:]
Đầu vào của hàm này sẽ được pad lên 192 hex digits, tương đương với 768 bits. Hãy để ý rằng & 0xFF...F sẽ chỉ lấy 128 bit cuối, và bitshift sang phải 640 bits cũng là bội số của 128. Từ đó, ta có thể chia đầu vào thành 6 đoạn 128-bit để phân tích: s = x0 x1 x2 x3 x4 x5.
Bước đầu tiên:
x = apply_secret(to_encrypt >> 640)
Sau khi dịch cả chuỗi sang phải bit thì chuỗi gốc chỉ còn , và kết quả trả về là , trong đó ở đây là apply_secret. Sở dĩ mình đổi tên như vậy là để nhắc lại các bạn rằng, cái hàm này xáo trộn thứ tự bit.
x^to_encrypt
Cái này XOR giữa chuỗi đầu vào x0 x1 x2 x3 x4 x5 và chuỗi sau permutation 00 00 00 00 x. Từ đó, đầu ra ta sẽ có là x0 x1 x2 x3 x4 (x5^x).
(x^to_encrypt) & 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF) << 640
Dùng AND mask lấy ra 128 bit cuối, rồi shift trái 640 bit cho đủ 768 bits. Từ đó, ta có đầu ra là (x5^x) 00 00 00 00 00.
((x^to_encrypt) & 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF) << 640) | (to_encrypt >> 128)
Shift trái chuỗi đầu vào 128 bit rồi OR với chỗ bit 0 của chuỗi chúng ta vừa có ở trên. Kết quả chúng ta thu được sẽ là x5^perm(x0) x0 x1 x2 x3 x4.
Cứ làm như vậy 9 lần là được nhé.
Biết vậy thì giờ decrypt thế nào?
Nếu chúng ta có permutation key (cụ thể là hàm apply_secret), thì decrypt khá là đơn giản. Bây giờ chuỗi đã encrypt của chúng ta (sau mỗi lần xào lên) là
x0' x1' x2' x3' x4' x5' = x5^perm(x0) x0 x1 x2 x3 x4
Từ đó, do XOR có tính chất tự huỷ, ta có
x5 = x5^perm(x0)^perm(x0) = x0'^perm(x1')
Và có được chuỗi gốc bằng cách
x0 x1 x2 x3 x4 x5 = x1' x2' x3' x4' x5' x0'^perm(x1')
Rồi cũng làm vậy 9 lần là ra được chuỗi gốc nhé.
Lời giải
Sau một hồi suy nghĩ các loại thử các block 00...0 (sẽ output toàn 0) hay 11...1 (sẽ output ra một chuỗi gồm các block toàn 0 hoặc toàn 1) thì mình cũng đưa ra một lời giải khá là cơ bản. Nếu chúng ta cần tìm ra được cái permutation , thì hãy để một block chỉ bao gồm một phần tử ở vị trí thôi. Từ đó, sau mỗi lần permute và xào lên, chúng ta sẽ có được vị trí mới của nó . Cứ như vậy, với mỗi một điểm bắt đầu, chúng ta sẽ tìm được một vòng tròn các vị trí bit đó sẽ đến cho đến lúc nó quay lại vị trí xuất phát. Về toán học, chúng ta đang cần tìm các additive subfield trong .
Cụ thể hơn, với một vị trí ban đầu bất kỳ, chúng ta cho , trong đó hàm trả về một số 128-bit với tất cả các bit bằng 0, ngoại trừ bit ở vị trí thứ bằng 1. Chúng ta chọn đầu vào cho encryption oracle như sau:
trong đó tương ứng với một block 128-bit toàn 0. Giờ với là block toàn 0 và chỉ có 1 bit 1 ở vị trí , tương ứng với vị trí , và cứ thế. Định nghĩa tổng quát hơn thì .
Từ đó sau 9 lần xào lên, chúng ta có
| Lần | Kết quả | Lần | Kết quả |
|---|---|---|---|
| 0 | 5 | ||
| 1 | 6 | ( | |
| 2 | 7 | ||
| 3 | 8 | ||
| 4 | 9 |
Để giải thích kết quả ở trên, ngoài phần shift tất cả sang phải, chúng ta cần nhìn qua cách ra được block đầu tiên mới. Nên nhớ rằng hàm apply_secret (hay mình còn gọi là perm) đưa bit 1 ở vị trí qua , nên perm() theo định nghĩa. Ngoài ra quan trọng hơn, ta cần để ý là perm()perm()perm(): hàm permutation xáo cả 2 chuỗi theo cùng một thứ tự, và XOR thì xử lý các bit cùng chỗ với nhau, nên chúng ta có thể thấy ở đây có tính chất phân phối. Từ đó, mình sẽ làm vài ví dụ tiêu biểu để chỉ ra chứng minh tại sao ra được bảng trên nhé (các trường hợp còn lại tương tự với các trường hợp mình sắp nêu sau đây).
- Lần 0 1:
- Lần 5 6:
- Lần 6 7:
Cụ thể là đặc biệt ở trường hợp cuối có XOR tự huỷ; và ở trường hợp gần cuối, chúng ta cần để ý rằng nếu chuỗi đầu ra không có bit nào 1 cả, đồng nghĩa với việc 2 phần tử XOR đó là giống nhau. Trong các trường hợp còn lại, nếu chỉ có một giá trị thì đó chính là vị trí của bit 1 trong block, và nếu là XOR của 2 thì vị trí của chúng sẽ là 1 trong 2 vị trí của bit 1 trong block.
Sau một hồi query, chúng ta sẽ có được những vị trí mà bit đã chạy qua: . Với các permutation cycle như vậy, chúng ta có thể lấy lại được mảng secret: phần này đơn giản và xin được để lại như một bài tập về nhà cho người đọc, cùng với đáp án ở dưới phần code.
Vậy thì chiến thuật query như thế nào để tối thiểu?
Tối thiểu thì thực ra mình cũng không chắc, nhưng đây là chiến thuật mình đã sử dụng để đạt được flag với 30 queries Giả sử lấy điểm đầu là , ta query với giá trị và có:

Do từ đây đã thấy lặp lại (nhìn và có giá trị 34), chúng ta có thể suy luận và điền tay chuỗi này rồi. Nếu , thì chuỗi này có độ dài 2, và cũng phải bằng 34; tuy nhiên điều đó không đúng. Vậy và , và chuỗi này có độ dài là 8. Tiếp theo, chúng ta có thể suy luận rằng . Từ đó, chỉ còn , và chúng ta có thể query thêm.
Đây là trường hợp đặc biệt khi chuỗi đó lặp lại ngay sau query đầu tiên. Ngoài ra, một trường hợp khác là khi các giá trị và trùng nhau, khiến tự huỷ lúc XOR:

Ta có thể thấy chuỗi đó lặp lại với độ dài là 6, và có thể điền các giá trị còn lại như sau:
Trong các trường hợp không đặc biệt, như ví dụ dưới đây khi , lợi nhất là chúng ta tiếp tục query vào (như code ở phần dưới sẽ là query(9):

Chú ý rằng khi ta query một nào đó thì kết quả đầu tiên chúng ta có chắc chắn là . Vì vậy, để lấy giá trị từ trở đi, chúng ta query giá trị của với query(4) (hiện tại thiếu ảnh minh hoạ cho trường hợp này[1]). Sau đó ta query vào :

Từ đó ta thấy ô 19 lại không được điền (vì như trên, đầu vào là thì chỉ có kết quả từ trở đi đến ). Từ đó ta lại query ô 15, và sẽ có giá trị đến ô . Trong đó, ô 20 nằm giữa cũng sẽ được xử lý, và từ đó ô 26 cũng xử lý theo (vì 20 và 26 có chung 2 khả năng, nếu biết được ô 20 là gì thì ô 26 là giá trị còn lại). Từ đó ta sẽ có kết quả sau khi query :

Và với tất cả các ô khác đã được xử lý thì ta lại query vào ô cuối cùng đã biết, đó là ô 27. Cứ như vậy, ta có trình tự như sau:
Trong đó, từ query thứ 3 trở đi, chúng ta lùi 3 bước để tiến 12 bước. Giải thích lại cụ thể với chuỗi :
- Sau khi query , ta không lấy được các giá trị từ (cho đến ). Vì vậy, để lấy các giá trị đó, ta cần query , nghĩa là lùi .
- Sau khi query , ta thấy tất cả các giá trị đã được điền, và ta điền giá trị cuối cùng đã được xác định. Khi chúng ta query , thì giá trị cuối cùng chúng ta có là ; nghĩa là lúc chúng ta query , chúng ta đã có được đến ô như trên ảnh. Do chúng ta đã lùi 3 ở bước trước, nên bây giờ chúng ta sẽ được tiến .
Làm vậy đến lúc bắt đầu thấy lặp lại thì chúng ta sửa tay các giá trị đầu tiên như các ví dụ ở trên cùng.
[1] Trong các trường hợp thiếu ảnh, hay ảnh không liên quan, vì đó là ảnh minh hoạ. Lúc mình query mình không giữ hết các output để viết writeup; tuy nhiên, tính chất đầu ra trong các trường hợp là giống nhau: chỉ có giá trị cụ thể tìm được là khác nhau, còn các vị trí tương quan không thay đổi.
Talk is cheap, show me the code!
Bài này thực ra mà tự động hoá thì cũng được, nhưng mình đã thủ công xử lý flag 🙃Bài này cho mình sử dụng một cryptographic oracle với tối thiểu số query, và chúng ta cần lấy ra permutation table để decode.
Đầu tiên, các bài sử dụng socket/netcat trong giải này đều yêu cầu proof-of-work phá một cái hash rác:
p = ''.join(random.choice('0123456789abcdef') for i in range(6))
print("Give me a string such that its sha256sum ends in {}.".format(p))
l = input().strip()
if hashlib.sha256(l.encode('ascii')).hexdigest()[-6:] != p:
print("Wrong PoW")
sys.exit(1)
Vậy chúng ta lập ra một rainbow table chứa hash và chuỗi tương ứng:
from string import printable
from hashlib import sha256
from tqdm.auto import tqdm
mapper = {}
for c1 in tqdm(printable):
c = c1
mapper[sha256(c.encode('ascii')).hexdigest()[-6:]] = c
for c2 in printable:
c = c1 + c2
mapper[sha256(c.encode('ascii')).hexdigest()[-6:]] = c
for c3 in printable:
c = c1 + c2 + c3
mapper[sha256(c.encode('ascii')).hexdigest()[-6:]] = c
for c4 in printable:
c = c1 + c2 + c3 + c4
mapper[sha256(c.encode('ascii')).hexdigest()[-6:]] = c
import pickle
with open('hashtable', 'wb') as dict_file:
pickle.dump(mapper, dict_file)
Cái dictionary này trên máy mình tạo ra mất ~7', dung lượng 500Mb, và load vào RAM mất tầm 15s. Tuy nhiên, chắc chắn trong lúc code sẽ có nhiều lần phải chạy lại do code sai (và mình thực tế mất cả buổi chiều set up cái server đó mới đebug được lỗi code), nên cứ lưu lại đi còn dùng nhiều lần 
import pickle
with open('hashtable', 'rb') as dict_file:
mapper = pickle.load(dict_file)
Thử đi thử lại, trong trường hợp xấu số server yêu cầu một hash nào mình không có :-s
from pwnlib.tubes.remote import remote
while True:
r = remote('challs.m0lecon.it', 11000)
print(r.recv(1024).decode().strip())
hash_ = inp_.strip('.').rsplit(' ', 1)[1]
r.sendline(mapper[hash_])
print(r.recv(1024).decode().strip())
try:
challenge = inp_.split('\n')[1]
break
except:
r.close()
print('Retrying...')
Sau đó thì challenge đã được mã hoá sẽ được lưu trong biến challenge. Đặt rolls là array chứa các giá trị của rolls[0], nếu chưa có giá trị nào, và một mảng nếu có nhiều hơn 1 giá trị có thể, chúng ta bắt đầu query.
rolls = [-1] * 128
def query(i: int):
'''
query the oracle with 0001000.
@param i: i-th iteration (same i in s_i of our previous notation).
'''
# choose the oracle (instead of the challenge)
r.sendline(str(1))
r.recv(1024).decode().strip()
# build and send the query
b = ['0'] * 128
b[idx] = '1'
r.sendline(hex(int(''.join(b), 2))[2:].rjust(32, '0') + '0' * (32 * 5))
# only get the first line, which is the query output; then pad it to get 192 hexdigits.
res = r.recv(1024).decode().strip().split('\n')[0].rjust(192, '0')
# divide them into 128-bit blocks
blocks = []
for i in range(6):
b = res[i * 32 : (i + 1) * 32]
b = bin(int(b, 16))[2:].rjust(128, '0')
blocks.append(b)
# consider the blocks as per analyzed above
assert blocks[0].count('1') == 1
s9 = blocks[0].index('1')
assert blocks[2].count('1') == 1
s7 = blocks[2].index('1')
assert blocks[4].count('1') == 1
s5 = blocks[4].index('1')
assert blocks[5].count('1') == 1
s4 = blocks[5].index('1')
# if you encounter these warnings, edit the `rolls` array by hand.
if not blocks[1].count('1') == 2:
print('warning: idx2+8 is empty.', idx + 2, 'and', idx + 8, 'overlap.')
idx28 = [i for i, x in enumerate(blocks[1]) if x == '1']
assert ((blocks[3].count('1') == 0) or (blocks[3].count('1') == 2 and blocks[3][val] == '1'))
if blocks[3].count('1') == 0:
print('warning:', idx+6, 'gives all 0. overlap with', idx, end='.\n')
s6 = sum([i for i, x in enumerate(blocks[3]) if x == '1']) - val
# and then update `rolls`, but only if it's not filled already.
rolls[idx] = val
if rolls[idx + 2] == -1:
rolls[idx + 2] = idx28
if rolls[idx + 8] == -1:
rolls[idx + 8] = idx28
if type(rolls[idx + 4]) is list or rolls[idx + 4] == -1:
rolls[idx + 4] = s4
if type(rolls[idx + 5]) is list or rolls[idx + 5] == -1:
rolls[idx + 5] = s5
if type(rolls[idx + 6]) is list or rolls[idx + 6] == -1:
rolls[idx + 6] = s6
if type(rolls[idx + 7]) is list or rolls[idx + 7] == -1:
rolls[idx + 7] = s7
if type(rolls[idx + 9]) is list or rolls[idx + 9] == -1:
rolls[idx + 9] = s9
# at the end, update all the [s2, s8] candidate lists:
# if, say s8 is determined, but s2 still isn't updated,
# then we update s2 from the candidate list to its result.
known_values = [i for i in rolls if type(i) is int and i != -1]
for i in range(128):
if type(rolls[i]) is list:
for val_ in known_values:
if val_ in rolls[i]:
val_ = sum(rolls[i]) - val_
if val_ not in known_values:
rolls[i] = val_
known_values.append(val_)
break
# do this twice if you feel like it, just in case the first run
# did not cache all the known_values.
Rồi query theo thứ tự đã phân tích ở trên. Chú ý: chỉ chạy đến khi nhìn thấy rolls bắt đầu loop lại — lúc đó chúng ta sẽ sửa tay để tiết kiệm query. Sau đó, chúng ta cắt rolls tại điểm lặp lại, và add nó vào danh sách các subfield/cycles:
# only run this once at the beginning, comment this out after the first cycle.
cycles = []
# find the end index before it loops over
for i in range(1, 128):
if rolls[i] == rolls[0]:
curr_len = i
break
# for it to actually loops over
cycles.append(rolls[0:curr_len + 1])
# find the index i to start next loop
print('start here:', min(set(range(128)) - set(sum(cycles, []))))
Sau tất cả thì chúng ta sẽ có các subfields trong của cái permutation. Từ đó, chúng ta xây dựng lại secret:
secret = [None] * 128
for cycle in cycles:
for i, j in zip(cycle[:-1], cycle[1:]):
secret[j] = i
Có permutation table rồi thì làm gì? Ta decrypt theo như đã giải thích ở phần trên.
def decrypt(s):
to_decrypt = int(s, 16)
for _ in range(9):
x = apply_secret((to_decrypt >> 512) & ((1 << 128) - 1)) ^ (to_decrypt >> 640)
to_decrypt = ((to_decrypt & ((1 << (128 * 5)) - 1)) << 128) | x
return binascii.unhexlify(hex(to_decrypt)[2:]).decode('ascii')
Submit và ăn điểm.
r.sendline(str(2))
r.recv(1024).decode().strip()
r.sendline(decrypt(challenge))
while True:
print(r.recv(1024).decode().strip())
Game là dễ.
Good job! You did it in 30 requests
Level 1 completed: ptm{sometimes_encryption_can_be_as_bad_as_decryption_ecdb556edcffd}
Level 2 completed: ptm{you_are_a_master_of_oracles_ecdcbceda557842aa}
Kết bài
Thức đến 2h sáng để chơi CTF và thức đến 6h sáng để viết bài writeup này thật là khó khăn với một tấm thân và tâm hồn già cỗi này.
All rights reserved
