Linux capacity planning
Bài đăng này đã không được cập nhật trong 6 năm
Dạo đầu =))
Tình hình Cô Vy ngày càng phức tạp , khiến cuộc sống của chúng ta đảo lộn, nhưng không thể vì thế mà bạn nên buông thả hay phó mặc mọi thứ Sau sóng gió, có người trở nên rệu rã và mãi không thể quay trở về vị trí ban đầu, nhưng cũng sẽ có người lột xác thành một con người khác: tươi trẻ, giàu năng lượng, sáng tạo và máu chiến hơn . Quyết thắng vượt qua mùa dịch nào!
Quay lại chủ đề chính hôm nay liên quan đến Capacity Planning . Có rất nhiều thành phần trong một hệ điều hành Linux có thể gây ảnh hưởng tới hiệu năng của hệ thống. Việc chủ động giám sát các (monitoring) components, sẽ là cách duy nhất để bảo vệ hệ thống của bạn . Tôi sẽ đề cập tới các công cụ và tiện ích giúp bạn có thể giám sát hệ thống dễ dàng.
1. CPU Monitoring
điều quan trọng không chỉ là việc xác định CPU(s) có bị overloaded (quá tải) hay không, mà còn là nguyên nhân gây ra sự quá tải đó. Ví dụ đó là user process hay system process? Hay nếu làm việc trong môi trường máy ảo, nguyên nhân có phải là do hypervisor? Việc xác định được câu trả lời cho những câu hỏi tương tự đã đề cập sẽ giúp bạn khắc phục các vấn đề về system performance.
1.1. Basic CPU Load Information
uptime, cho chúng ta biết hệ thống đã chạy bao lâu. và cho chúng ta một cái nhìn nhanh về số lượng người dùng trên hệ thống, và tải trung bình (load average) vào thời điểm 1, 5 và 15 phút gần nhất.
root@techzones:~# uptime
06:39:36 up 214 days, 21:35, 1 user, load average: 0.00, 0.01, 0.00
Khái niệm load average dễ gây nhầm lẫn cho người quản trị , giá trị này được thiết kế để mô tả CPU load.
Với một hệ thống single CPU . Ví dụ:
* load average=0.50⇒load average=0.50⇒ 50% CPU được sử dụng trong khoảng. thời gian đó.
* load average=1.50⇒load average=1.50⇒ CPU bị overtasked, các process requests bị kẹt ở queue vì CPU đang bận handling process khác.
Với một hệ thống từ 2 CPUs . Ví dụ:
* load average=0.50⇒load average=0.50⇒ 25% CPUs được sử dụng trong khoảng thời gian đó.
* load average=1.50⇒load average=1.50⇒ 75% CPUs được sử dụng trong khoảng thời gian đó.
1.2. Detailed CPU Load Information
Một công cụ hữu ích khác để monitoring CPU là iostat. Công cụ này còn được sử dụng để monitoring disk I/O

Phần đầu tiên trong output cung cấp thông tin tóm lược về hệ thống bao gồm:
Kernel verion: 4.4.16-1.el7.elrepo.x86_64
Hostname: techzones
Date of report: 21/03/2020
Kernel type: x86_64
Number of CPUs: 24 CPU
Phần kế tiếp là report về các số liệu thống kê liên quan tới CPUs.
%user – Giá trị này biểu diễn phần trăm CPU được sử dụng khi ứng dụng được chạy ở mức user-level (các processes chạy bởi tài khoản user bình thường)
%nice – Các câu lệnh thường xuyên được người dùng chạy bằng nice command để thay đổi ưu tiên proccess CPU
%system – Giá trị này biểu diễn phần trăm CPU được sử dụng bởi các processes của kernel.
%iowait – Giá trị này biểu diễn phần trăm CPU được sử dụng khi CPU đang chờ hoạt động disk I/O hoàn thành trước khi chuyển qua hành động kế tiếp.
%steal – Giá trị này chỉ gắn liền với virtual CPUs. Trong một vài trường hợp, virtual CPU phải chờ hypervisor xử lý các requests từ virtual CPUs khác. Giá trị này chỉ ra phần trăm thời gian chờ hypervisor xử lý virtual CPU’s request.
%idle – Giá trị này biểu diễn phần trăm thời gian CPU không xử lý bất kỳ request nào ? ngồi chơi không 😀
mình sẽ lấy 1 ví dụ khác về iostat với giá trị iowait cao :

Ở ví dụ này, output của %iowait có giá trị cao hơn mức thông thường. Nếu xảy ra các vấn đề làm cho tiến trình xử lý, service phản hồi chậm, thì đây cũng là một giá trị đáng xem xét
Trong vận hành thì iostat có 2 option rất thường sử dụng .
iterval: Thời gian chờ (đơn vị: giây (s)) giữa những lần chạy lệnh iostat.
count: Số lần cần report.
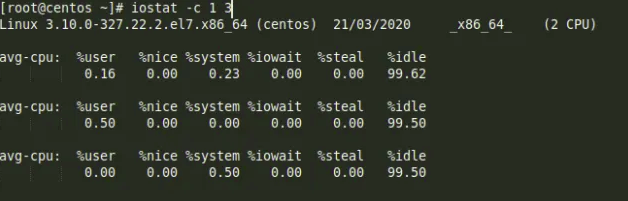
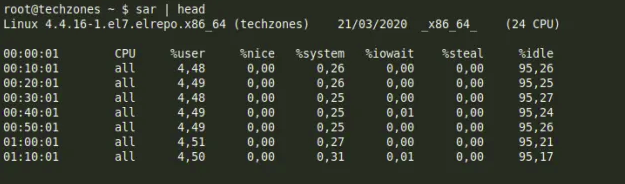
Ngoài iostat thì chúng ta cũng có 1 command khách đó sar. Tuy nhiên câu lệnh sar hiển thị các thông tin theo khoảng thời gian 10 phút một.
2. Memory Monitoring
Một hệ thống được trang bị CPU tốc độ cao vẫn có thể trở nên trì trệ nếu như gặp vấn đề về bộ nhớ. lưu ý một điều: khi bạn giám sát lượng bộ nhớ sử dụng, bạn cần nhìn vào cả RAM và Swap space.
2.1. Basic Memory Usage Information
khi nói về Memory thì tôi nghĩ nay đến Free đầu tiên .

-
Mem: Dòng này mô tả về RAM
-
Swap: Dòng này mô tả về Virtual Memory
Các thông số còn lại :
total — Giá trị này biểu diễn tổng dung lượng bộ nhớ của hệ thống.
used — Dung lượng bộ nhớ hiện đang được sử dụng
free — Dung lượng bộ nhớ còn trống.
shared — Giá trị này biểu diễn dung lượng bộ nhớ được sử dụng bởi tmpfs. tmpfs là một filesystem thường xuyên hiện hữu trên hard disk
buff/cache — Buffer hoặc Cache là các vị trí lưu trữ tạm thời.
available — Giá trị này biểu diễn bao nhiêu dung lượng bộ nhớ trống cho một tiến trình mới (new processes).
Mặc định, các giá trị hiển thị với đơn vị là kilobytes . Tuy nhiên bạn có thể hiển thị chính xác giá trị hơn với option -b/–bytes, hoặc hiển thị theo megabytes -m/–mega, hoặc gigabytes -g/–giga
2.1. Detailed Memory Usage Information
đó chính là vmstat
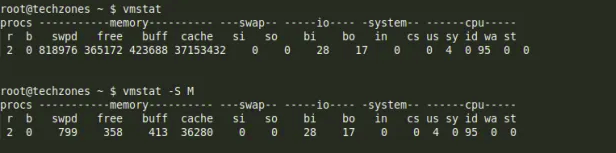
Procs
-
r: Số process đang chạy hoặc chờ chạy.
-
b: Số process trong trạng thái uninterruptible sleep.
Memory
-
swpd: Dung lượng virtual memory đã sử dụng.
-
free: Dung lượng memory trống.
-
buff: Dung lượng memory được sử dụng làm buffer.
-
cache: Dung lượng memory được sử dụng làm cache.
IO
-
bi: Block nhận từ block device (blocks/s).
-
bo: Block gửi block device (blocks/s).
System
-
in: Số interupt trên giây. Bao gồm cả clock interrupt.
-
cs: Số lượng context switch trên giây.
CPU Tỷ lệ phần trăm của tổng thời gian CPU.
-
us: Thời gian sử dụng cho việc chạy ngoài Kernel-code (bao gồm cả user time và nice time).
-
sy: Thời gian sử dụng để chạy Kernel-code.
-
id: Idle time. Phiên bản Linux 2.5.41 trở về trước bao gồm cả thời gian chời IO.
-
wa: Thời gian chờ IO. Phiên bản Linux 2.5.41 trở về trước hiển thị 0.
-
st: Thời gian bị lấy từ một máy ảo. Phiên bản Linux 2.6.11 trở về trước, không được xác định.
3. Disk I/O Monitoring
để monitoring disk I/O ta có thể sử dụng command iostat, với -d option
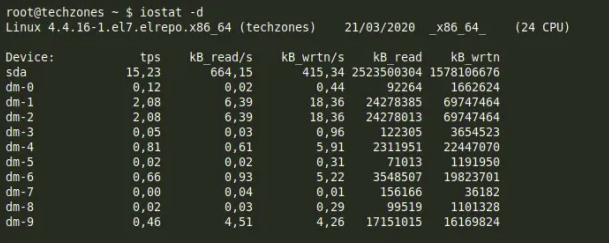
sda — 1st SATA drive.
dm-0 — 1st LVM logical volume.
dm-9 — 2nd LVM logical volume.
Nếu bạn còn chưa hiểu các mô tả trong output của command iostat thì hãy xem giải thích dưới đây nhé
tps — Giá trị transfer/s cho mỗi device.
kB_read/s — Số kilobytes/s đọc từ device.
kB_wrtn/s — Số kilobytes/s ghi vào device.
kB_read — Số kilobytes đọc từ device.
kB_wrtn — Số kilobytes ghi vào device.
Listing Open Files
Dưới đây là một số tuyệt kỹ khi dùng lsof
Hiển thị các nodes của các processes đang chạy trên cổng network được chỉ định. Ví dụ với cổng SSH: lsof -i TCP:22
Liệt kê các nodes của processes liên quan tới IPv4: lsof -i 4 Liệt kê các command mở kết nối mạng: lsof -i
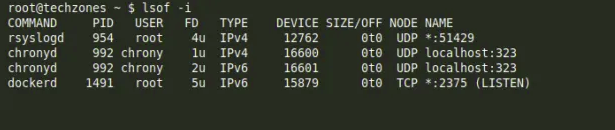
Loại trừ các nodes thuộc về user đã chỉ định : lsof -p 100

Hiển thị output của tất cả các file trong một thư mục. Ví dụ /usr/bin: lsof +d /usr/bin
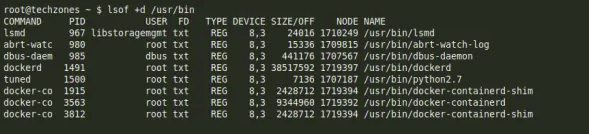
4. Network I/O Monitoring
Và để hiển thị chi tiết thông tin về network I/O hơn ta lại dùng câu lệnh netstat
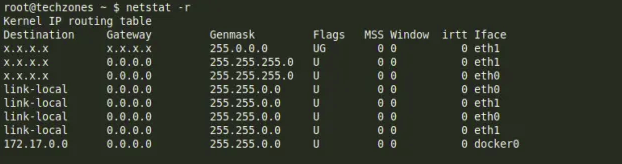
đây không phải là một phương pháp giám sát mạng mà chỉ cung cấp cho chúng ta các thông tin hữu ích về route.
Dưới đây là một số tuyệt kỹ khi dùng netstat
-l — Hiển thị network sockets đang trong trạng thái lắng nghe.
-lt — Hiển thị TCP sockets đang trong trạng thái lắng nghe.
-lu — Hiển thị UDP sockets đang trong trạng thái lắng nghe.
-p — Hiển thị program name và PID trong output.
-n — Tăng tốc câu lệnh netstat, giảm trễ khi DNS chưa respond.
-c — Update output realtime.
5. Additional Monitoring Tools
Để hiển thị các thông tin cơ bản của hệ thống như running time, average system load, số lượng process đang chạy, CPU statistics, thông tin memory, … Ta dùng lệnh top
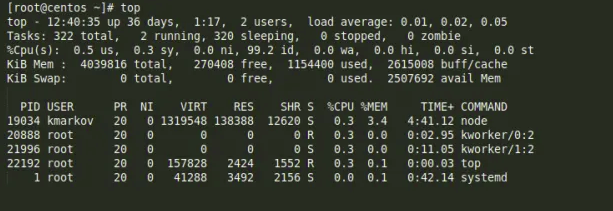
6. Summary
Việc monitoring system là không thể thiếu và rất quan trọng khi bạn triển khai hệ thống trên staging cũng như production. Bài viết này chỉ giới thiệu các câu lệnh và khái niệm cơ bản, khi deploy và vận hành hệ thống trên môi trường end-user bạn sẽ còn gặp rất nhiều vấn đề phức tạp, Ngoài ra sử dụng các hệ thống monitoring tự động Check_mk / Zabbix / Prometheus sẽ tiết kiệm chi phí về nhân lực và hạ tầng hơn rất nhiều.
Nguồn : Techzones.me
All rights reserved
