Lần đầu tiên Crawl dữ liệu của tôi như thế nào?
Bài đăng này đã không được cập nhật trong 4 năm
Dữ liệu là một phần vô cùng quan trọng trong bất kì ứng dụng hay trang web nào. Đặc biệt với một ứng dụng hay trang web mới, việc có một khối dữ liệu kha khá khi mà số lượng người dùng chưa lớn là vô cùng nan giản. Ngoài kia có rất nhiều trang web đã chạy trước đó có dữ liệu mà chúng ta có thể custom nó để biến nó thành dữ liệu cho mình. Vậy làm sao có thể lấy được những dữ liệu này? Có ai nghĩ rằng chúng ta sẽ bật trang web của họ lên rồi coppy dữ liệu về không nhỉ? Crawl bằng cơm có vẻ khó khăn khi chúng ta không có nhiều thời gian, kiên nhẫn để coppy đống dữ liệu đó về. Câu trả lời đó là: Chúng ta sẽ viết một đoạn code nho nhỏ, request lên trang web có sẵn để lẩy lại những dữ liệu cần thiết về.
1. Tại sao chúng ta có thể crawl dữ liệu được từ các trang web khác?
Như chúng ta, những developer web vẫn luôn biết, tất cả page trong một web luôn có cấu trúc nhất định, cái khác nhau chỉ có thể là dữ liệu của chúng khác nhau.
Mình có một page như sau:
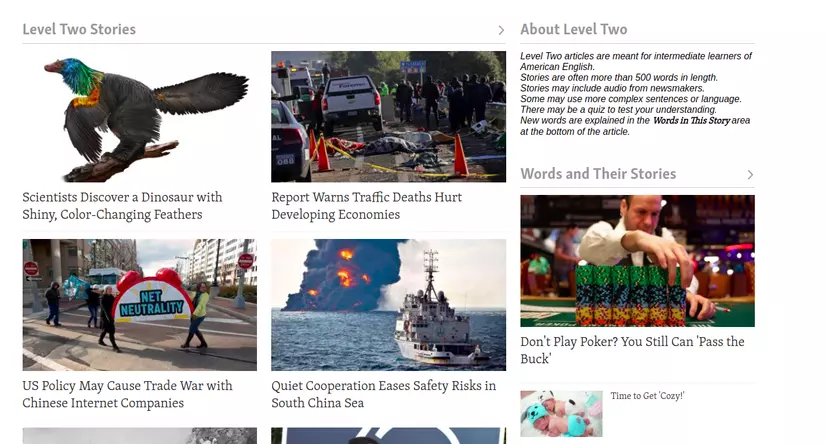 Khi inspec lên các bạn sẽ nhìn thấy các element sau:
Khi inspec lên các bạn sẽ nhìn thấy các element sau:
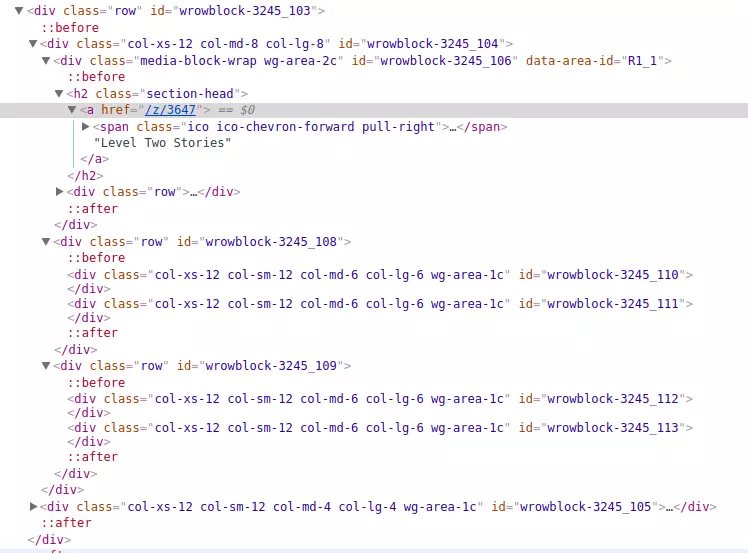 Trên cùng 1 trang web như vậy, mình có page 2:
Trên cùng 1 trang web như vậy, mình có page 2:
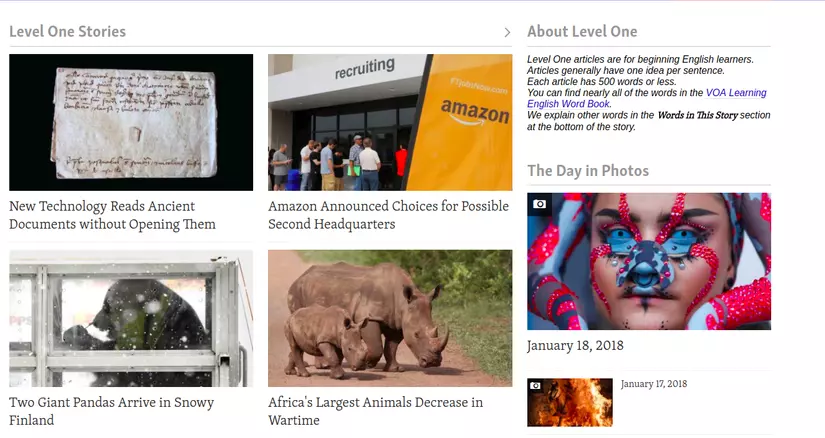 Và khi inspec lên thì chúng ta có thể thấy:
Và khi inspec lên thì chúng ta có thể thấy:
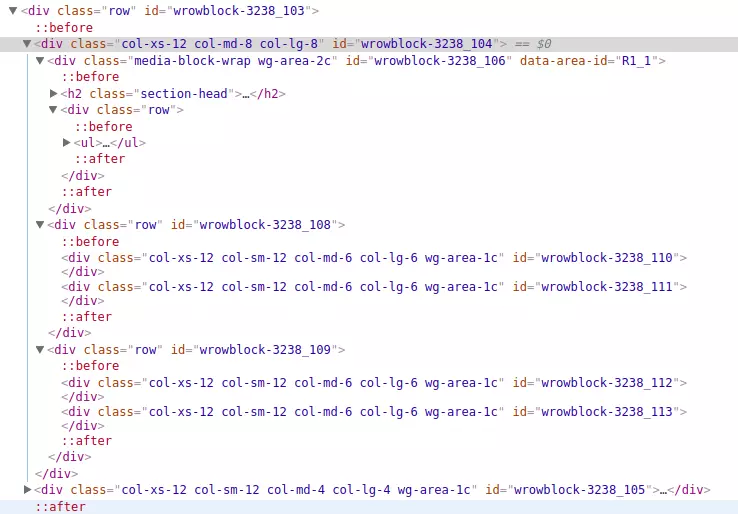
Các bạn có thể thấy hai element trên hai trang này giống hệt nhau (ngoại trừ phần dữ liệu). Vì thế, chúng ta hoàn toàn có thể dựa vào các element này để chúng ta có thể lấy dữ liệu trong đó!
2. Làm như thế nào để crawl được?
Để có thể crawl được dữ liệu, chúng ta cần quan tâm đến yếu tố đầu tiên, đó là: Trang web bạn muốn crawl có bị chặn request hay không?
Nếu như bạn nhìn thấy trong Header của Response trả về có dạng như sau:
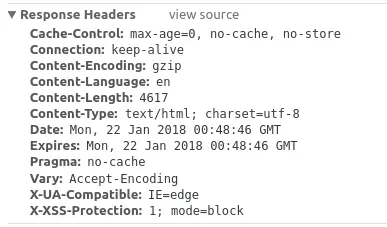 Các bạn có thể thấy
Các bạn có thể thấy
X-XSS-Protection:1; mode=block
Nghĩa là trang web này đang được protect, vì vậy khi các bạn request sẽ không thể lấy được dữ liệu mình cần. Vì vậy, hãy tránh những trang web được bảo vệ như vậy ra nhé!
Điều thứ hai cần lưu ý khi chúng ta crawl dữ liệu đó là: Trang web bạn muốn crawl có cấu trúc có ổn định hay không? Tại sao chúng ta cần quan tâm đến cấu trúc của trang web? Một trang web nếu có cấu trúc ổn định thì chúng ta sẽ dễ dàng lấy data hơn là một trang web cấu trúc mỗi trang một định dạng khác nhau bởi vì khi chúng ta crawl sẽ dựa chủ yếu dựa trên các element để lấy được data.
3. Sau khi crawl xong, nên làm như thế nào?
Sau khi crawl xong, để chúng ta có thể sử dụng một cách tổt nhất thì chúng ta nên đẩy những dữ liệu của chúng ta vào các object hoặc sang json. Mỗi khi lấy dữ liệu, chúng ta nên thêm từng dữ liệu vào từng object để chúng ta tránh trường hợp khi chúng ta crawl được dữ liệu nhiều rồi nhưng lại có lỗi xảy ra khiến code của chúng ta bị crash khiến mọi dữ liệu đã craw được bị mất hết.
Dữ liệu được lưu dưới dạng json khiến chúng ta sẽ dễ dàng đẩy vào database một cách dễ dàng.
4. Example
Chúng ta sẽ cùng thử với một trang sau: http://www.manythings.org/voa/scripts/ Lần này, mình sử dụng Java để crawl dữ liệu với cách thủ công nhất chỉ có thể áp dụng được cho một trang suy nhất bằng cách sử dụng duyệt từng element, trong bài viết tiếp theo mình sẽ hướng dẫn các bạn cách tốt hơn là: X-Path
Để chuẩn bị cho crawl dữ liệu, chúng ta cần một package để connect tạo request lên trang. Ở đây, mình sử dụng JSOUP
Document doc = Jsoup.connect(url).data("query", "Java").userAgent("Chrome").cookie("auth", "token").timeout(5000).post();
Ý tưởng
Ý tưởng của cách này đó là: Chúng ta duyệt các element để lấy được các link, từ các link chúng ta sẽ lấy được thông tin của trong từng bài cụ thể. Thực hiện Bước 1: Gửi http request lên trang để lấy về trang dạng document Bước 2: Từ trang đã lấy được về, trích xuất ra những link có đưuọc để vào detail của thông tin cần lấy Bước 3: Lấy data dựa trên DOM vừa tìm được
Kiểm tra element của trang:
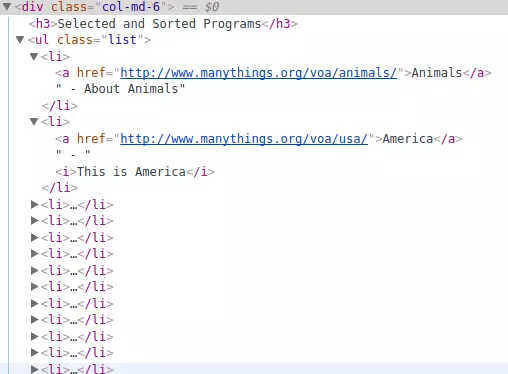
Chúng ta có thể thấy được dữ liệu chúng ta cần nằm trong thẻ <li> chứa trong thẻ <ul> có class="list", vì thế chúng ta có thể bắt đầu lấy dữ liệu từ thẻ <ul> đó. Tuy nhiên các bạn có thể nhìn thấy 2 thẻ <ul> có class="list"
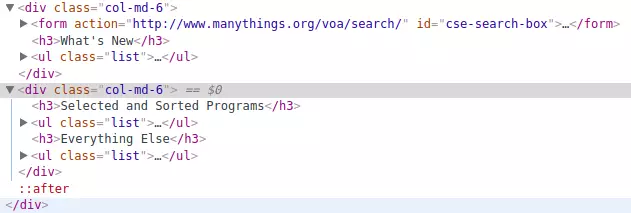
Vì dữ liệu chúng ta cần nằm trong <ul> thứ 2 nên chúng ta cần lấy get ra element thứ 2.
Elements elements = doc.getElementsByClass("list").get(1).children();
Sau lệnh này chúng ta sẽ lấy được các element trong <ul>.
Thực hiện tương tự, chúng ta nhảy vào từng element chúng ta sẽ lấy được các link thông qua thẻ a và attribute href để có thể lấy được hết tất cả các data trong tất cả các link vừa nhận được.
for (Element e : elements) {
Elements list_a = e.getElementsByTag("a");
for (Element a : list_a) {
String href_a = a.attr("href");
//Check tương tự dựa theo link để nhảy vào từng link này chúng ta sẽ xem xét tiếp element để xem chúng ta đã nhận được data mong muốn hay chưa
.
.
.
.
}
}
Như mình có nói, chúng ta nên lưu dữ liệu nhận được vào Object và đẩy object ra JSON. Trong trường hợp này chúng ta có thể sử dụng package GSON để đổi dữ liệu dạng Object sang dạng JSON bằng một câu lệnh đơn giản:
new Gson().toJson(models)
Trang này của chúng ta có cấu trúc không giống nhau lắm nên ý tưởng của chúng ta nên đổi lại ý tưởng ban đầu: Lấy hết tất cả các link cho đến khi không còn link nào nữa và lấy dữ liệu về.
Cách này vô cùng THỦ CÔNG, và chỉ hơn cách crawl bằng cơm một chút. Mình sẽ hướng dẫn các bạn trong bài viết tiếp theo, hãy chờ nhé!!!
All rights reserved
