Làm thế nào để xây dựng một pipeline phân tích xử lý Big Data (Part 2)
Bài đăng này đã không được cập nhật trong 4 năm
Như đã giới thiệu ở bài viết trước về sự cần thiết cũng như các thành phần cơ bản cấu thành nên một hệ thống phân tích dữ liệu lớn (pipeline Big Data processing). Tiếp theo chủ đề này, bài viết dưới đây sẽ hướng dẫn cụ thể về cách thức setup các dịch vụ:
- Cassandra (NoSQL database, main storage)
- Apache Kafka (Messaging system)
- Apache Storm (Broker, message delivery system, data processing)
- ElasticSearch (2nd storage, indexing & searching)
Tiếp sau đấy là ví dụ về việc kết nối các thành phần trên thành một pipeline (code mô tả sử dụng ngôn ngữ Java, Python)
Hướng dẫn setup các dịch vụ
Giả định về môi trường thiết lập cài đặt ở đây là Centos 7, sử dụng các command yum install. Trong trường hợp bạn sử dụng Ubuntu (từ bản 14.04 trở lên) có thể làm tương tự với cú pháp apt-get install.
Tất cả các dịch vụ dưới đây đều chạy trên môi trường java (1.7 hoặc 1.8) do đó bạn cần đảm bảo cài đặt và thiết lập jdk ở máy trước khi bắt đầu, xem thêm ở đây
- Cassandra
Cài đặt apache-cassandra-3.6
$ mkdir /opt/apache-cassandra-3.6
$ wget http://archive.apache.org/dist/cassandra/3.6/apache-cassandra-3.6-bin.tar.gz
$ tar -xvzf apache-cassandra-3.6-bin.tar.gz
Add to system variable $PATH
$ vim ~/.bashrc
export CASSANDRA_HOME=/opt/apache-cassandra-3.6
export PATH=$PATH:$CASSANDRA_HOME/bin
Tạo user cassandra
$ useradd cassandra
$ passwd cassandra
Enable remote access, chỉnh sửa file cacssandra.yaml
$ vim /opt/apache-cassandra-3.6/conf/cassandra.yaml
start_rpc: true
rpc_address: 0.0.0.0
broadcast_rpc_address: 1.2.3.4
Open port 9042 cho phép access từ outside
$ yum install firewalld
$ systemctl start firewalld
$ firewall-cmd --zone=public --add-port=9042/tcp --permanent
$ firewall-cmd --reload
Kiểm tra xem port 9042 đã được mở thành công hay chưa
$ lsof -i | grep 9042
Cấp phát memlock unlimited
$ vi /etc/security/limits.d/cassandra.conf
<cassandra_user> - memlock unlimited
<cassandra_user> - nofile 100000
<cassandra_user> - nproc 32768
<cassandra_user> - as unlimited
$ vi /etc/sysctl.conf
vm.max_map_count = 1048575
Để apply các thay đổi vừa thực hiện, chạy command
$ sudo sysctl -p
Cassandra hoạt động dựa trên Ring topology, để hệ thống chạy ổn định và đạt được hiệu suất tốt chúng ta sẽ setup theo mô hình 1 master và 3 slave. Thực hiện 3 node slave tương tự như trên, sau đấy sửa config trong file cassandra.yaml như dươi đây:
Ở master node, giả sử IP address local là: 10.0.1.109
seeds: 10.0.1.109
listen_address: 10.0.1.109
broadcast_address:
broadcast_rpc_address: 10.0.1.109
auto_bootstrap: false
Ở 3 node slave
seeds: 10.0.1.109
listen_address: (new node internal ip)
broadcast_address:
broadcast_rpc_address: (new node internal ip)
Khởi động cassandra ở node master và các node slave
$ su cassandra
$ cassandra
- Apache Kafka
Cài đặt apache kafka 2.11, download ở đây
$ cd /opt
$ tar xvzf kafka_2.11-0.8.2.2.tgz
$ useradd kafka
$ chown -R kafka. /opt/kafka_2.11-0.8.2.2
$ ln -s /opt/kafka_2.11-0.8.2.2 /opt/kafka
$ chown -h kafka. /opt/kafka
Tạo các file cấu hình services Tạo file kafka.service
$ vi /etc/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker)
Documentation=http://kafka.apache.org/documentation.html
Requires=network.target remote-fs.target
After=network.target remote-fs.target kafka-zookeeper.service
[Service]
Type=simple
User=kafka
Group=kafka
Environment=JAVA_HOME=/opt/mesosphere/active/java/usr/java
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
[Install]
WantedBy=multi-user.target
Tạo file kafka-zookeeper.service
$ vi /etc/systemd/system/kafka-zookeeper.service
[Unit]
Description=Apache Zookeeper server (Kafka)
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
Group=kafka
Environment=JAVA_HOME=/opt/mesosphere/active/java/usr/java
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
[Install]
WantedBy=multi-user.target
Khởi chạy các dịch vụ
$ systemctl daemon-reload
$ systemctl start kafka-zookeeper.service
$ systemctl status kafka-zookeeper.service
$ systemctl start kafka.service
$ systemctl status kafka.service
Nếu các lệnh trên chạy ok, thực hiện enable service
$ systemctl enable kafka-zookeeper.service
$ systemctl enable kafka.service
Enable outside access bằng cách mở các cổng 2181, 9092
$ firewall-cmd --permanent --add-port=2181/tcp
$ firewall-cmd --permanent --add-port=9092/tcp
$ firewall-cmd --reload
- Apache Storm
Download zookeeper version 3.4.6 từ đây
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir data
Tạo file config zoo.cfg
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2
Start zookeeper server
$ bin/zkServer.sh start
Để start CLI sử dụng command
$ bin/zkCli.sh
Download apache storm 0.9.5 từ đây
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir data
Sửa file cài dặtđặt conf/storm.yaml
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
Khởi chạy các dịch vụ của storm
$ bin/storm nimbus
$ bin/storm supervisor
$ bin/storm ui
Sau khi hoàn tất các bước cài đặt bạn có thể truy cập storm thông qua giao diện web: http://localhost:8080
- ElasticSearch
Thực hiện cài elasticsearch version 2.x
$ sudo rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
$ echo '[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
' | sudo tee /etc/yum.repos.d/elasticsearch.repo
$ sudo yum -y install elasticsearch
Sửa file cấu hình elasticsearch.yml
$ sudo vi /etc/elasticsearch/elasticsearch.yml
network.host: [10.0.1.109, _local_]
cluster.name: production
node.name: ${HOSTNAME}
discovery.zen.ping.unicast.hosts: ["10.0.0.1", "10.0.0.2", "10.0.0.3"]
bootstrap.mlockall: true
node.master: true
node.data: false
Cấu hình memory cấp phát
$ sudo vi /etc/sysconfig/elasticsearch
ES_HEAP_SIZE=2g
MAX_LOCKED_MEMORY=unlimited
$ sudo vi /usr/lib/systemd/system/elasticsearch.service
LimitMEMLOCK=infinity
Khởi chạy elasticsearch service
$ sudo systemctl start elasticsearch
$ sudo systemctl enable elasticsearch
Cài đặt tương tự cho 3 node slave 10.0.0.1, 10.0.0.2, 10.0.0.3 để lưu trữ data
$ sudo vi /etc/elasticsearch/elasticsearch.yml
node.master: false
node.data: true
Bài toán ví dụ
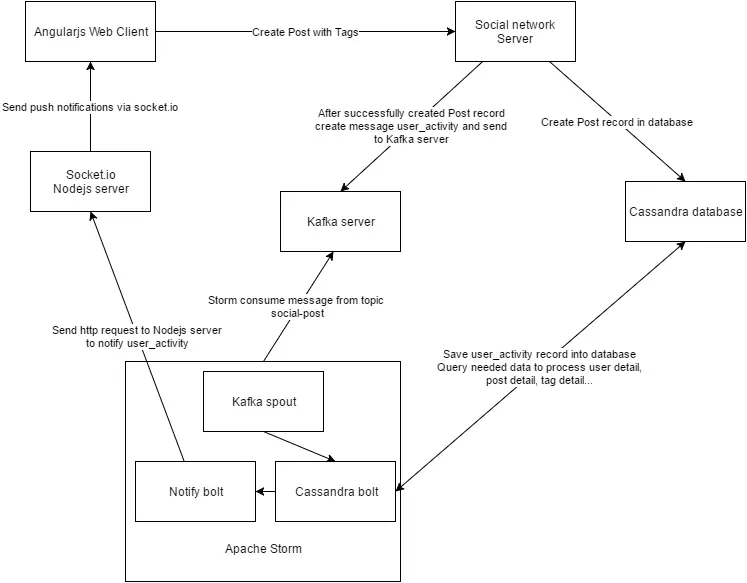
Giả định cần xây dựng mô hình giải quyết cho bài toán phân tích, lưu trữ các post của người dùng từ một social network sau đấy push cho các follower của user đó.
Mô hình giải quyết chúng ta sẽ xây dựng như sau:
Đầu tiên tạo keyspace social-network, table post, user_activity trong Cassandra sử dụng CQL
CREATE KEYSPACE IF NOT EXISTS social-network WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 3 } AND DURABLE_WRITES = true;
use social-network;
create table if not exists post (
post_id uuid,
author_id uuid,
date_created timestamp,
date_updated timestamp,
content text,
images set<uuid>,
videos set<uuid>,
location frozen<location>,
publicity text,
primary key(author_id, date_created, post_id)
)with clustering order by(date_created desc, post_id asc);
create table if not exists user_activity(
user_id uuid,
activity_id uuid,
activity_type text,
interaction_date text,
interaction_time timeuuid,
data text,
primary key((user_id, interaction_date), interaction_time)
);
Create index social-network, type post với analyzer & tokenizer sử dụng ngram trên server elasticsearch
POST "http://10.0.1.109:9200/social-network"
Body
{
"settings": {
"analysis": {
"filter": {
"edgeNGram_filter": {
"min_gram": "2",
"side": "front",
"type": "edgeNGram",
"max_gram": "20"
}
},
"analyzer": {
"edge_nGram_analyzer": {
"filter": [
"lowercase",
"asciifolding",
"edgeNGram_filter"
],
"type": "custom",
"tokenizer": "edge_ngram_tokenizer"
},
"whitespace_analyzer": {
"filter": [
"lowercase",
"asciifolding"
],
"type": "custom",
"tokenizer": "whitespace"
}
},
"tokenizer": {
"edge_ngram_tokenizer": {
"token_chars": [
"letter",
"digit"
],
"min_gram": "2",
"type": "edgeNGram",
"max_gram": "10"
}
}
}
},
"mappings": {
"post": {
"_all": {
"analyzer": "edge_nGram_analyzer",
"search_analyzer": "whitespace_analyzer"
},
"properties": {
"author_id": {
"type": "string"
},
"content": {
"type": "string",
"analyzer": "edge_nGram_analyzer",
"search_analyzer": "whitespace_analyzer"
},
"created_date": {
"type": "date",
"format": "yyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"post_id": {
"type": "string"
}
}
}
}
}
Theo mô hình đề xuất dữ liệu sẽ đi theo flow: user sử dụng social-network tạo post, post sẽ được đẩy tới kafka và lữu trữ trong topic social-post. Server storm được xây dựng gồm có kafka-spout subscribe topic social-post, 3 bolt chính được xây dựng: cassandra-writer-bolt để xử lý post và lưu lại user_activity trong cassandra database, notify_bolt để đẩy các push-notification tới NodeJS socket server, elasticsearch-bolt để nạp các post sang server elasticsearch phục vụ cho việc indexing, tìm kiếm.
Các thư viện chính được sử dụng
org.apache.storm/storm-core/1.0.1
com.datastax.cassandra/cassandra-driver-core/3.0.0
org.apache.kafka/kafka-clients/0.10.0.0
org.apache.storm/storm-kafka/1.0.1
org.apache.kafka/kafka_2.11/0.10.0.0
Cài đặt các class thiết lập kết nối tới các dịch vụ
class CassandraConnection
{
// ------------------------------ FIELDS ------------------------------
private final Cluster cluster;
private final Session session;
private final int maxRequestPerConnection = 128;
private final int maxConnectionLocalPerHost = 8;
private final int maxConnectionRemotePerHost = 2;
private final int coreConnectionLocalPerHost = 2;
private final int coreConnectionRemotePerHost = 1;
// --------------------------- CONSTRUCTORS ---------------------------
public CassandraConnection(String node, String keyspace, String username, String password)
{
PoolingOptions pools = new PoolingOptions();
pools.setMaxRequestsPerConnection(HostDistance.LOCAL, maxRequestPerConnection);
pools.setCoreConnectionsPerHost(HostDistance.LOCAL, coreConnectionLocalPerHost);
pools.setMaxConnectionsPerHost(HostDistance.LOCAL, maxConnectionLocalPerHost);
pools.setCoreConnectionsPerHost(HostDistance.REMOTE, coreConnectionRemotePerHost);
pools.setMaxConnectionsPerHost(HostDistance.REMOTE, maxConnectionRemotePerHost);
cluster = Cluster.builder()
.addContactPoint(node)
.withPoolingOptions(pools)
.withCredentials(username, password)
.withSocketOptions(new SocketOptions().setTcpNoDelay(true))
.build();
session = cluster.connect(keyspace);
}
// --------------------- GETTER / SETTER METHODS ---------------------
public Session getSession()
{
return this.session;
}
// -------------------------- OTHER METHODS --------------------------
public void close()
{
session.close();
cluster.close();
}
}
Cài đặt class CassandraWriterBolt, các post lấy từ kafka-spout sau khi được phân tích ở đây sẽ tiếp tục được đẩy vào (emit) tuple để sử dụng tiếp ở các bolt khác
class CassandraWriterBolt extends BaseRichBolt
{
// ------------------------------ FIELDS ------------------------------
private static final Logger LOG = LoggerFactory.getLogger(CassandraWriterBolt.class);
private final static String USERNAME = "cassandra";
private final static String PASSWORD = "cassandra";
private final static String HOST = "10.0.1.109";
private final static String KEYSPACE = "social-network";
private Session session;
private OutputCollector collector;
// --------------------- Interface IBolt ---------------------
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector)
{
this.collector = outputCollector;
}
public void execute(Tuple tuple)
{
try
{
CassandraConnection connection = new CassandraConnection(HOST, KEYSPACE, USERNAME, PASSWORD);
session = connection.getSession();
LOG.info("content " + tuple.getString(0));
UserActivity userActivity = new UserActivity(new Gson().fromJson(tuple.getString(0), Post.class));
boundCQLStatement(tuple, userActivity);
connection.close();
}
catch (Throwable t)
{
collector.reportError(t);
collector.fail(tuple);
LOG.error("tuple data error " + t.toString());
}
}
// --------------------- Interface IComponent ---------------------
public void declareOutputFields(OutputFieldsDeclarer declarer)
{
declarer.declare(new Fields("name", "post_id", "author_id", "content", "channel_ids", "published_time"));
}
// -------------------------- OTHER METHODS --------------------------
private void boundCQLStatement(Tuple input, UserActivity userActivity)
{
session.execute("use social-network;");
PreparedStatement statement = session.prepare(
"INSERT INTO user_activity " +
"(user_id, interaction_date, interaction_time, activity_id, activity_type, data) " +
"VALUES (?, ?, ?, ?, ?, ?);");
BoundStatement boundStatement = new BoundStatement(statement);
session.execute(boundStatement.bind(
userActivity.getUserId(),
userActivity.getInteractionDate(),
UUIDs.startOf(userActivity.getInteractionTime()),
userActivity.getActivityId(),
userActivity.getActivityType(),
userActivity.getData()));
Set<String> userIdSet = new HashSet<>();
final Pattern pattern = Pattern.compile("(?:\\s|\\A)[@]+([A-Za-z0-9-_]+)");
final Matcher matcher = pattern.matcher(userActivity.getData());
while (matcher.find())
{
userIdSet.add(matcher.group(1));
}
String name = "";
PreparedStatement selectStatement = session.prepare("select user_id, first_name, last_name from user where user_id = ?;");
BoundStatement bst = new BoundStatement(selectStatement);
ResultSet results = session.execute(bst.bind(userActivity.getUserId()));
for (Row row : results)
{
name = row.getString("first_name") + StringUtils.SPACE + row.getString("last_name");
break;
}
collector.emit(input, new Values(name, userActivity.getActivityId().toString(), userActivity.getUserId().toString(), userActivity.getData(),
!userIdSet.isEmpty() ? StringUtils.join(userIdSet, ",") : "", userActivity.getInteractionTime().toString()));
collector.ack(input);
}
}
Tương tự cài đặt các lớp NotifyBolt sử dụng data từ tuple do CassandraWriterBolt emit ở trên, tiếp tục tạo HTTP request đẩy sang NodeJS socket server và push tới các subscriber, ElasticSearchBolt đẩy data sang tạo post ở server elasticsearch
class NotifyBolt extends BaseRichBolt
{
//.............
public void execute(Tuple tuple)
{
HttpPost request = new HttpPost("http://10.0.1.109:8080/send-push");
request.addHeader("Content-Type", "application/x-www-form-urlencoded");
// Request parameters and other properties.
List<NameValuePair> params = new ArrayList<>();
params.add(new BasicNameValuePair("name", tuple.getStringByField("name")));
params.add(new BasicNameValuePair("post_id", tuple.getStringByField("post_id")));
params.add(new BasicNameValuePair("channel_ids", tuple.getStringByField("channel_ids")));
params.add(new BasicNameValuePair("published_time", tuple.getStringByField("published_time")));
try
{
request.setEntity(new UrlEncodedFormEntity(params, "UTF-8"));
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
HttpClientBuilder bld = HttpClientBuilder.create();
HttpClient client = bld.build();
try
{
HttpResponse response = client.execute(request);
HttpEntity entity = response.getEntity();
collector.ack(tuple);
}
catch (IOException e)
{
e.printStackTrace();
}
}
//...
}
class ElasticSearchBolt extends BaseRichBolt
{
//-----
public void execute(Tuple tuple)
{
String postId = tuple.getStringByField("post_id");
HttpPost request = new HttpPost("http://10.0.1.109:9200/social-network/post/" + postId);
request.addHeader("Content-Type", "application/json;charset=UTF-8");
try
{
StringEntity entity = new StringEntity("{\n" +
" \"post_id\": \"" + tuple.getStringByField("post_id") + "\",\n" +
" \"author_id\": \"" + tuple.getStringByField("author_id") + "\",\n" +
" \"created_date\": \"" + tuple.getStringByField("published_time") + "\",\n" +
" \"content\": \"" + JSONObject.escape(tuple.getStringByField("content")) + "\"\n" +
"}", "UTF-8");
request.setEntity(entity);
}
catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
HttpClientBuilder bld = HttpClientBuilder.create();
HttpClient client = bld.build();
try
{
HttpResponse response = client.execute(request);
HttpEntity entity = response.getEntity();
collector.ack(tuple);
}
catch (IOException e)
{
e.printStackTrace();
}
}
// ----------
}
Cuối cùng là bước tạo topology để ghép nối các thành phần chúng ta đã xây dựng ở trên lại với nhau, topology này sẽ được đóng gói lại thành gói jar và deploy ở server storm
public class KafkaSpoutTopology
{
// ------------------------------ FIELDS ------------------------------
private final static String KAFKA_HOST = "10.0.1.109:2181";
private final static String NIMBUS_HOST = "10.0.1.109";
private final static String KAFKA_TOPIC = "social-post";
private final BrokerHosts brokerHosts;
// --------------------------- CONSTRUCTORS ---------------------------
private KafkaSpoutTopology(String kafkaZookeeper)
{
brokerHosts = new ZkHosts(kafkaZookeeper);
}
// --------------------------- main() method ---------------------------
public static void main(String[] args) throws Exception
{
KafkaSpoutTopology kafkaSpoutTopology = new KafkaSpoutTopology(KAFKA_HOST);
Config config = new Config();
config.put(Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS, 30);
StormTopology stormTopology = kafkaSpoutTopology.buildTopology();
if (args != null && args.length > 0)
{
String name = args[0];
config.put(Config.NIMBUS_HOST, NIMBUS_HOST); //YOUR NIMBUS'S IP
config.put(Config.NIMBUS_THRIFT_PORT, 6627); //int is expected here
config.setNumWorkers(20);
config.setMaxSpoutPending(5000);
StormSubmitter.submitTopology(name, config, stormTopology);
}
else
{
config.setNumWorkers(2);
config.setMaxTaskParallelism(Runtime.getRuntime().availableProcessors());
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("kafka-storm-cassandra", config, stormTopology);
}
}
private StormTopology buildTopology()
{
SpoutConfig kafkaConfig = new SpoutConfig(brokerHosts, KAFKA_TOPIC, "/opt/zookeeper-3.4.8/data", "storm-integration");
kafkaConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new KafkaSpout(kafkaConfig), 10);
builder.setBolt("write-to-cassandra", new CassandraWriterBolt()).shuffleGrouping("words");
builder.setBolt("notify", new NotifyBolt()).shuffleGrouping("write-to-cassandra");
builder.setBolt("write-to-elasticsearch", new ElasticSearchBolt()).shuffleGrouping("write-to-cassandra");
return builder.createTopology();
}
}
Sử dụng command dưới đây để chạy topology trên ở distributed mode trên server storm
$ storm jar kafka-storm-cassandra (tên của topology)
Giờ thì bạn có thể lấy cho mình 1 tách cafe và ngồi thử nghiệm pipeline vừa tự build, have fun 
TL;DR
Trong 2 post vừa rồi mình đã chia sẻ về cách thức phân tích, xây dựng một pipeline cho việc xử lý big data. Tất nhiên usecase giả định ở đây rất đơn giản, trong thực tế sẽ còn nhiều trường hợp phức tạp hơn đòi hỏi sự tham gia của các mô hình học máy hỗ trợ cũng như các giải thuật tối ưu hơn. Hy vọng bài viết sẽ giúp ích được các bạn trong giai đoạn làm quen với chủ đề rất thú vị này.
Tham khảo chi tiết về các hướng dẫn cài đặt, các bạn có thể xem thêm ở:
https://www.tutorialspoint.com/index.htm
Project về tích hợp các dịch vụ trong bài viết mình public ở:
All rights reserved
