Làm thế nào để xây dựng một pipeline phân tích xử lý Big Data (Part 1)
Bài đăng này đã không được cập nhật trong 4 năm
Mục tiêu
Trong thời đại của IoT (Internet of Things) khối lượng dữ liệu sẵn có tăng với tốc độ chóng mặt dẫn tới nhu cầu cấp thiết của một hệ thống phân tích hiệu quả. Ngoài ra, sự đa dạng của các dữ liệu tới từ nhiều nguồn và nhiều định dạng khác nhau, chẳng hạn như các cảm biến, bản ghi, dữ liệu có cấu trúc từ một RDBMS... và cần có một pipepline phân tích hiệu quả mà có thể trả về các dữ liệu có giá trị giúp cho các bài toán kinh tế. Bài viết này tìm hiểu cách tạo ra một pipeline như vậy với các công nghệ tiên tiến nhất hiện nay.
Background
Khoảng thời gian trước đây lưu trữ dữ liệu lớn vô cùng tốn kém do thiếu các công nghệ có thể xử lý một cách hiệu quả. Câu chuyện đã khác ở hiện tại khi chi phí lưu trữ trở nên rẻ hơn rất nhiều với sự xuất hiện của nhiều công nghệ mới. Một số cột mốc quan trọng đầu tiên hướng tới xử lý Big Data có thể kể tới đó là vào năm 2003 khi Google công bố GFS (Google File System) và các bài báo về Mapreduce. Doug Cutting cũng bắt đầu việt một hệ thống Big Data dựa trên các khái niệm và cho ra đời Hadoop, một trong những hệ thống Big Data thông dụng nhất hiện nay.
Một hệ thống phân tích hiệu quả cần phải có khả năng giữ lại các dữ liệu, xử lý dữ liệu, khai thác các tri thức, cung cấp thông tin trong một khoảng thời gian chấp nhận được (không phải là quá trễ để có thể đáp ứng các yêu cầu nghiệp vụ) cũng như đủ linh hoạt để xử lý muôn vàn các trường hợp sử dụng.
Tất cả các hệ thống nêu trên đều đòi hỏi một pipeline phân tích bao gồm các thành phần như sau:
Các thành phần của pipeline phân tích
Các thành phần chính của một pipeline phân tích:
- Hệ thống nhắn tin (messaging system)
- Phân phối các message tới các node khác nhau để xử lý
- Xử lý phân tích, bóc tách các suy luận nội suy từ dữ liệu. Bao gồm các ứng dụng học máy trên dữ liệu.
- Hệ thống lưu trữ dữ liệu (data storage system) lưu lại các kết quả và thông tin có liên quan.
- Các giao diện (interface), công cụ trực quan (visual tools), cảnh báo, etc.
Các thông số quan trọng của hệ thống
Các hệ thống phân tích nên đáp ứng:
- Xử lý được lượng lớn và đa dạng của dữ liệu, i.e Big Data. Hệ thống có thể đáp ứng xử lý cho hàng triệu message đến từ một lượng lớn không ngừng tăng các thiết bị.
- Độ trễ thấp: Thời gian đáp ứng phản hồi tốt (gần như là thời gian thực). Có rất nhiều các trường hợp sử dụng sẽ đòi hỏi một thời gian đáp ứng hiệu quả, dựa vào đó các thực thể quan trọng có thể được thông báo về các event sắp xảy ra hoặc trường hợp thất bại (failure).
- Khả năng mở rộng: Mở rộng trên một tập nhiều thông số khác nhau, chẳng hạn như số lượng các thiết bị tham gia (hàng trăm nghìn), message (hàng triệu mỗi phút), lưu trữ (nhiều terabytes)
- Sự đa dạng: Phục vụ không giới hạn các trường hợp sử dụng, bao gồm cả những trường hợp không biết trước. Khi các nghiệp vụ và trường hợp sử dụng thay đổi, hệ thống cần phải có khả năng cung cấp các tinh chỉnh phù hợp.
- Sự linh hoạt: đủ linh hoạt để tự điều chỉnh thích hợp với các trường hợp sử dụng mới. Có thể kết hợp với các phân tích mang tính chất phát đoán.
- Tiết kiệm: có chi phí hiệu quả, lợi ích đem lại của việc xây dựng một hệ thống như vậy phải lớn hơn chi phí bỏ ra.
Hệ thống
Một hệ thống phân tích hiệu quả cần phải có một số khả năng quan trọng để đáp ứng các nhu cầu nghiệp vụ. Ngoài ra, nền tảng công nghệ không nên bị giới hạn trong ngữ cảnh của chi phí và sử dụng. Các tính năng mà chúng ta đang tìm kiếm để có được:
- Xử lý số lượng dữ liệu lớn (high volume of data): - Sử dụng một big data framework tương tự như Hadoop để giữ lại dữ liệu.
- Xử lý dữ liệu theo thời gian thực (real-time data processing): Sử dụng đồng thời Kafka và Spark cho giải pháp streaming.
- Học dự đoán (predictive learning) - Có rất nhiều giải thuật học máy được hỗ trợ bởi Spark MLLib hay Hadoop Mahount library.
- Lưu trữ các kết quả và dữ liệu. Một hệ thống NoSQL như MongoDB có thể là một lựa chọn tốt vì nó cung cấp sự linh hoạt trong cách thức lưu trữ dữ liệu dạng JSON trong schema. Pipeline mà chúng ta đang xây dựng sẽ bao gồm các dữ liệu do máy tính tạo ra, do đó MongoDB là một ứng cử viên hữu ích.
- Báo cáo kết quả - Có thể sử dụng Tableau hoặc Qlikview hoặc các công cụ mã nguồn mở như Jasper hoặc Brit. Chúng đều cung cấp giao diện người sử dụng giúp quản lý thông tin, lịch sử báo cáo tốt hơn.
- Cảnh báo (alert) - Có thể dử dụng Twilio để gửi đi các tin nhắn văn bản, ngoài ra cũng có thể sử dụng phương thức gửi cảnh báo thông qua email.
Biểu đồ dưới đây thể hiện pipeline phân tích bên trong phối cảnh IoT:
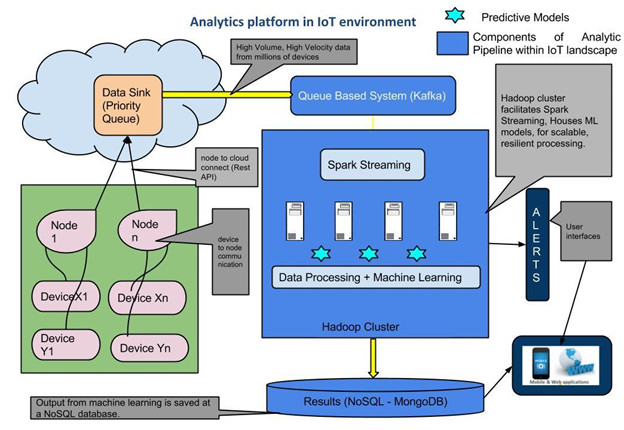
Technology stack
Các công nghệ sau đây được ưu tiên lựa chọn cho việc xây dựng pipeline phân tích. Ngoài ra để giải quyết cho nhu cầu kinh doanh, lựa chọn công nghệ bị ảnh hưởng bởi hai tham số: sử dụng và chi phí nhập (cost of entry). Hadoop là framework Big Data phổ dụng nhất tuy nhiên gần đây Spark cũng được cộng đồng sử dụng và phổ biến đáng kể. Với khả năng tích hợp các khía cạnh khách nhau của rất nhiều các giải pháp Big Data như Streaming và xây dựng mô hình dự đoán (predictive model) Spark đã trở thành một lựa chọn sáng giá.
- Hệ quản trị dữ liệu phân tán Hadoop (Hadoop distributed file system)
- Spark Streaming
- Spark MLLib
- Kafka
- MongoDB (hoặc Cassandra)
- Visualization tool như Tableau, Qlikview, D3.js, etc.
Đa số các công nghệ nêu trên đều đã được tích hợp sẵn trong dịch vụ cloud bởi các nhà cung cấp lớn như Microsoft, IBM, Amazon ... Những giải pháp này đem tới cho họ nhiều lợi ích riêng, chẳng hạn như có thể thử nghiệm nhanh chóng một giải pháp nào đó hoặc xây dựng PoCs. Tuy nhiên, mọi thứ đang trong quá trình phát triển và đôi khi lựa chọn về công nghệ lại bị giới hạn từ phía nhà cung cấp platform. Trong khi chờ đợi nhà cung cấp cải thiện, đa dạng cũng như ổn định hóa các dịch vụ trên, chúng ta có thể tự nghiên cứu và xây dựng một pipeline phân tích đơn giản, linh hoạt và dễ kiểm soát của chính mình ở môi trường local.
Đặc tả chi tiết của Pipeline phân tích
Messaging System
Từ góc độ một hệ thống phân tích, Apache Kafka có thể được sử dụng như điểm nhập vào (entry point). Apache Kafka với các tính năng hỗ trợ thông lượng lớn (high-throughput), phân tán (distributed) và cơ chế publish-suscribe của một messaging system rất phù hợp với các kịch bản dữ liệu lớn có thể mở rộng khi cần thiết. Để giải quyết bài toán xử lý thời gian thực, Kafka được sử dụng chung một cặp với Spark streaming, bản thân Spark cung cấp giải pháp tính toán nhanh chóng và khả năng mở rộng do sử dụng kiến trúc bộ nhớ nhanh hơn đáng kể so với kiến trúc map reduce của Hadoop.
Kafka cung cấp hai cơ chế: Producer và Listener, API ghi dữ liệu vào producer (thông qua Priority Queue), sau đó một Spark listener đăng ký lắng nghe từ Kafka sẽ nhận được dữ liệu từ stream. Thông qua sử dụng cơ chế này, Kafka đảm bảo được lượng lớn dữ liệu có thể xử lý một cách tuần tự với tần số cao và Spark streaming có thể phân phát cũng như xử lý ở rất nhiều node của Hadoop cluster. Do đó khi dữ liệu tăng lên chúng ta chỉ cần tăng thêm số node (nếu cần) là có thể đáp ứng được việc tiếp tục xử lý.
Một ưu điểm khác từ việc sử dụng Kafka đó là mỗi queue có thể mapping với một số kịch bản sử dụng khác nhau. Người thiết kế có thể thiết kế các queue tách biệt, đảm bảo cho quá trình xử lý logic là tối thiểu. Chúng ta không cần thiết phải viết code để lý cho những trường hợp, ngoại lệ mà không bao giờ xuất hiện trong queue.
Data ingestion
Một khi dữ liệu đã sẵn sàng ở messaging system, chúng ta cần một cơ chế đảm bảo cho dữ liệu tới với số lượng và vận tốc lớn có thể được xử lý hiệu quả đáp ứng được các nhu cầu nghiệp vụ. Điều này có thể đạt được bằng cách sử dụng các API streaming của hệ sinh thái Big Data. Spark Streaming có thể được sử dụng ở đây để đảm bảo rằng các message nhận được sẽ trải ra trên cluster và xử lý hiệu quả. Một ưu điểm khác đáng chú ý của việc này đó là chúng ta có thể cấu hình một cửa sổ thời gian xử lý nếu cần. Giả sử chúng ta muốn xử lý dữ liệu mỗi 30 giây hoặc mỗi 5 phút, điều này không bị phụ thuộc vào hệ thống mà vào trường hợp sử dụng.
Xử lý lỗi (error handling)
Dữ liệu tới các node khác nhau có thể không phù hợp với các tham số cần thiết. Trong tình huống này, nếu có lỗi phát sinh trong quá trình xử lý của một message, message đó cần phải được log lại vào file và phân tích sau đó.
Xử lý phân tích
Đây là giai đoạn mà quả trình xử lý dữ liệu thực sự được thực hiện. Ở đây, dựa trên các thuộc tính của dữ liệu (metadata), các mô hình phân tích được áp dụng. Ví dụ, nếu chương trình nghe được một message về tài chính, nó sẽ biết rằng cần phải áp dụng một cơ chế phát hiện gian lận. Phát hiện gian lận này sau đó có thể được áp dụng bằng phương tiện của một mô hình dự đoán. Ví dụ, giải sử rằng chúng ta đang phát triển một giải thuật K-means mà các trường hợp gian lận được đặt cờ off, khi mô hình này được tạo ra, các thông số khác nhau của nó sẽ được đưa vào hệ thống trước.
Sự linh hoạt để xử lý các định dạng dữ liệu khác nhau có sẵn thông qua định dạng JSON và chiết xuất thông tin cần thiết từ các dữ liệu có sẵn. Ví dụ, nếu mô hình học máy của chúng ta được dự đoán dựa vào hai tham số pred1 và pred2, chương trình ở cấp độ spark streaming chỉ có thể đọc các biến cần thiết và truyền lại cho mô hình học máy. Khi mô hình thay đổi, chương trình điều chỉnh lại các biến trong thời gian chạy, do đó cung cấp sự linh hoạt. Sự độc lập định dạng từ các thiết bị được thực hiện ở cấp độ Data Sink, nơi chương trình có thể dịch (nếu cần) một văn bản hoặc CSV qua thể hiện bằng JSON. Bằng cách này, đảm bảo rằng một định dạng sai sẽ bị bắt ở giai đoạn trước đó, chứ không gây ra failure của chương trình ở giai đoạn sau. Điều này cũng bao hàm một số bảo mật cơ bản và tính linh hoạt, như các message sẽ không được truyền trực tiếp tới cấp độ thiết bị.
Bây giờ, khi message được xử lý, các thông số được đọc, khai thác của các biến được thực hiện, mô hình thích hợp được tải, và các dữ liệu được đưa vào mô hình. Dựa trên các kết quả có sẵn, các xử lý khác (cũng có thể cấu hình được) có thể được thực hiện ở các lớp tiếp theo.
Các công nghệ được lựa chọn ở đây là thư viện MLLib Spark. Các thuật toán học máy phổ biến khác nhau như Decision tree, Random forest, K-means, vv đã có sẵn, và chúng có thể được sử dụng để xây dựng các mô hình khác nhau. Hơn nữa, MLLib liên tục được phát triển, vì vậy chúng ta có thể mong đợi nó trưởng thành hơn theo thời gian. Ở đây, không chỉ mô hình dự đoán có thể được sử dụng, mà còn là một cơ chế dựa trên luật có thể được phát triển cho mục đích giám sát.
Lưu trữ các kết quả
Sau khi quá trình xử lý phân tích được thực hiện, các kết quả sẽ cần phải được xử lý. Dựa trên output, chúng có thể được gửi tới user trong thời gian thực thông qua cảnh báo hoặc cũng có thể được lưu lại xem sau. Để đảm bảo cho dung lượng và vận tốc lưu lớn, NoSQL database với cách thức lưu dữ liệu dưới định dạng JSON như MongoDB hoặc Cassandra sẽ là lựa chọn tốt nhất. Các cảnh báo thời gian thực có thể được cấu hình cũng như lập trình để gửi đi các tin nhắn văn bản, sử dụng các dịch vụ như Twilio. Với nguồn lưu trữ dứ liệu này, chúng ta có thể đáp ứng rất nhiều giao diện sử dụng tùy vào nhu cầu của người sử dụng, ví dụ như báo cáo sử dụng Tableau, hoặc xem trên các thiết bị di dộng, etc.
Bảo mật, tin cậy và có thể mở rộng
Khi thiết kế một hệ thống phân tích, tất cả các yếu tố trên cần được xem xét. Sự lựa chọn của các công nghệ như Hadoop, Spark, và Kafka đã đặt ra những khía cạnh này. Dịch vụ bảo mật Kerberos-based có thể được cấu hình trên các cụm Hadoop, do đó đảm bảo cho hệ thống. Các thành phần khác như Kafka và Spark chạy trên một cụm Hadoop, do đó họ cũng được bao phủ bởi các tính năng an ninh của Hadoop. Khi những công cụ được thiết kế để xử lý dữ liệu lớn, sao chép dữ liệu và độ tin cậy được cung cấp bởi các cơ sở hạ tầng, do đó cho phép các kỹ sư tập trung vào việc xây dựng các đề xuất phục vụ cho nghiệp vụ. Ví dụ, nếu khối lượng dữ liệu tăng lên, chúng ta có thể thêm các node vào cluster. Cơ chế lưu trữ cơ bản đảm bảo tải trọng phân bố đều, và một khuôn khổ phân phối được tính toán sao cho đảm bảo tất cả các node được sử dụng. Những công nghệ này cũng sử dụng một cơ chế fail-safe nên khi một node fail, hệ thống đảm bảo rằng các tính toán sẽ được submit lại.
Kết luận
Như là một xu thế tất yếu, việc xây dựng một pipeline phân tích là cấp thiết cho các tổ chức/cá nhân muốn thu được nhiều giá trị hơn từ dữ liệu. Đây là một công việc phức tạp, đòi hỏi sự linh hoạt trên một quy mô chưa tùng có, không phải chỉ để xử lý lượng lớn dữ liệu mà còn phải đáp ứng ở một vận tốc vô cùng cao.
Với sự sẵn có của các công nghệ, điều đó không còn là một khái niệm xa lạ mà dần trở thành thực tế, sự linh hoạt có thể được mở rộng tiếp tục thông qua các dịch vụ cloud tích hợp sẵn học máy như Azure ML, Yhat, etc.
Bài viết tiếp theo
In action với hướng dẫn cài đặt môi trường Cassandra, Kafka, Storm, Spark và viết chương trình kết nối các thành phần trong pipline với nhau. Các bạn quan tâm có thể xem source code ở project của mình: project kafka-storm-cassandra-elasticsearch
Nguồn tham khảo bài viết
All rights reserved
