KISS và YAGNY Nụ cười và nước mắt câu chuyện Chuẩn hóa và Phi Chuẩn
Bài đăng này đã không được cập nhật trong 3 năm
Chắc hẳn rất nhiều người biết về nguyên tắc KISS (Keep It Simple, Stupid) và YAGNY (You Aren't Gonna Need It). Hàm ý của nó trong tiếng Việt nôm na là "giết gà mà dùng dao mổ trâu". Nói chung nguyên tắc này rất quan trọng nhưng cũng hay bị vi phạm, vì DEV thường thích nguy hiểm và làm những cái mới, những mô hình mới ngầu lòi mà hậu quả thì chưa thử sao mà biết được, còn thử rồi thì ối giời ơi. Hệ thống vừa nát vừa khắm, vừa phức tạp và chứa đầy công nghệ thời thượng nhất, để giải quyết vấn đề đơn giản nhất theo cách phức tạp nhất và phần mềm nhiều lỗi nhất, khó bảo trì nhất.
Hôm nay tôi nói về vấn đề tôi đã gặp phải, cũng tương đối nhiều lần vấn đề chuẩn hóa (Normalization) và phi chuẩn hóa (Denormalization). Tôi sẽ giải thích ngắn gọn một chút về hai cái này
Đầu tiên chuẩn hóa là gì?
 Nhìn như hình trên bạn thấy. Chuẩn hóa là tách dữ liệu có thể lưu riêng ra một bảng riêng.
Ưu điểm:
Nhìn như hình trên bạn thấy. Chuẩn hóa là tách dữ liệu có thể lưu riêng ra một bảng riêng.
Ưu điểm:
- Dữ liệu lưu riêng tránh trùng lặp
- Tiết kiệm dung lượng
- Khi cần cập nhật chỉ cần cập nhật một bản ghi, ví dụ bạn cập nhật khu vực của manager A. Bạn chỉ cần cập nhật một bản ghi trên bảng Manager các bảng khác không phải chỉnh sử gì. Nhược điểm:
- Khi cần join dữ liệu lớn, sẽ có hành hưởng hiệu năng (Mọi người cần nhớ là join lớn nhé.)
Vậy phi chuẩn là gì?
 Nhìn hình trên ta sẽ thấy trong việc phi chuẩn thay vì tách riêng bảng ra, ta lưu luôn tên quản lý, khu vực, và sector vào cùng một bảng nhân viên luôn. Nhìn thì sung sướng đúng không? Lúc truy vấn đơn giản không cần join hay làm gì cả.
Ưu điểm:
Nhìn hình trên ta sẽ thấy trong việc phi chuẩn thay vì tách riêng bảng ra, ta lưu luôn tên quản lý, khu vực, và sector vào cùng một bảng nhân viên luôn. Nhìn thì sung sướng đúng không? Lúc truy vấn đơn giản không cần join hay làm gì cả.
Ưu điểm:
- Truy vấn nhanh, không cần join hay làm gì cả Nhược điểm: Tuy rằng như vậy nhưng nó có một số nhược điểm, chính là không có những ưu điểm của việc chuẩn hóa.
- Nếu dữ liệu hay phải thay đổi, đó sẽ là ác mộng, điều gì sẽ xảy ra nếu như đổi tên của người quản lý (thường thì ít nhưng mình vì dụ thế) mà người này đang quản lý hàng nghìn người. (lúc này sẽ phải cập nhật hàng nghìn bản ghi)
- Nếu người quản lý đó nghỉ việc, và thay thế bởi người khác (cái này thì hay xảy ra này) Các bạn sẽ phải cập nhật lại bao nhiêu?
- Nói chung việc chỉnh sửa dữ liệu sẽ tốn kém, nếu dữ liệu ghi nhiều thì việc phi chuẩn này sẽ gặp vấn đề.
Lý thuyết thế thôi tôi sẽ đi vào câu chuyện thực tế nhé
Câu chuyện 1: Chuyện cơ cấu tổ chức. Chúng ta đều biết cơ cấu tổ chức là phần quan trọng trong doanh nghiệp, nó có mặt ở khắp nơi và thực tế thì nó cũng ít khi thay đổi nên việc phi chuẩn lưu dư thừa tên cơ cấu ở các bảng là chấp nhận được. Vậy tại sao tôi lại nói ở đây? Bởi vì. Đợi bài sau nhé!... Đấy là người ta sẽ nói thế còn tôi thì xin mô tả như sau. Giả sử cơ cấu tổ chức của bạn được lưu như sau.
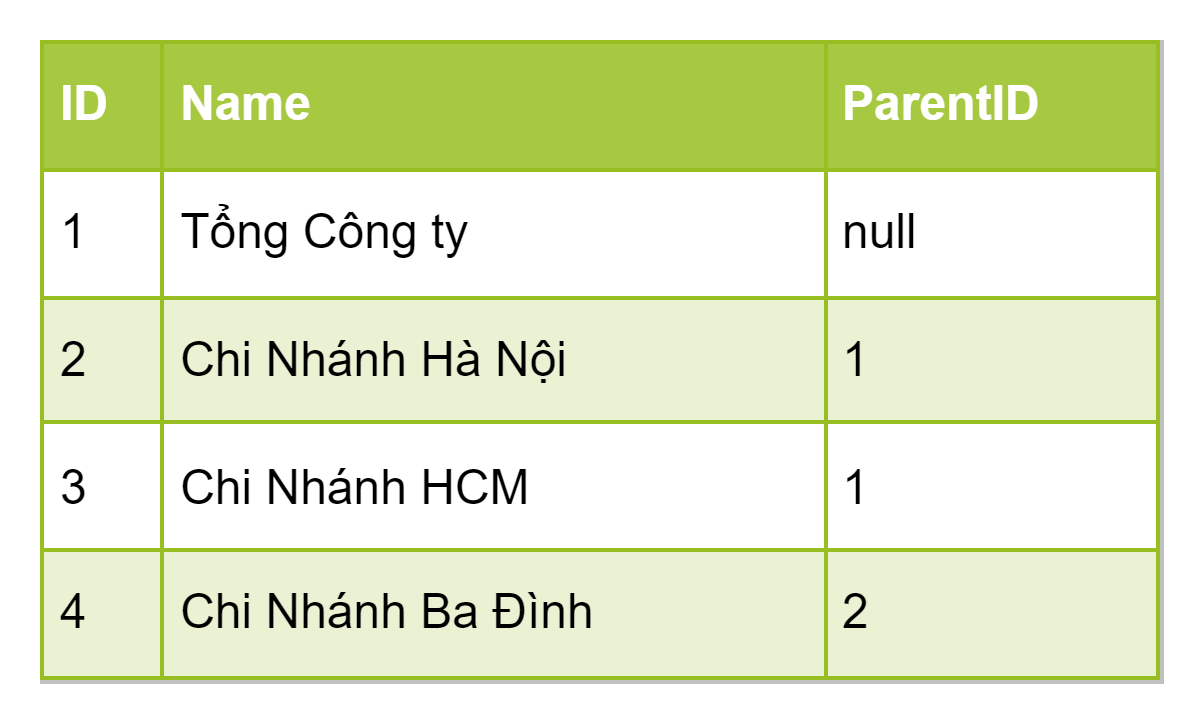
Với mô hình trong bảng lưu cha con dựa vào parentID, tuy nhiên mô hình này có một nhược điểm, là để tìm cha hay con thì phải đệ quy ảnh hưởng không tốt tới hiệu năng. Nên team DEV đã sử dụng mô hình PATH ENUMARATION để tăng tốc độ truy vấn. Về các pattern với tree trong database các bạn có thể tham khảo tại đây Với phần PATH ENUMATATION vui lòng xem từ trang 55 còn với kiểu Tree thì xem từ trang 48. Lúc này bảng như sau.
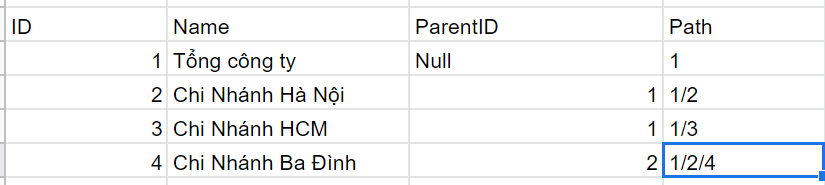
Lúc này giả sử muốn tìm tất cả các con, cháu hậu duệ của chi nhánh Hà Nội chỉ cần query.
SELECT *
FROM organization_unit
WHERE path LIKE '1/2%'
Như vậy là xong. Đúng là tiện đúng không. Nếu việc lưu riêng trường này ở trên bảng Organization_unit cũng không hại gì lắm. Tuy nhiên vì sợ JOIN quá mức. Dev team quyết định lưu luôn cả path trong các bảng cần dùng. Ví dụ bảng nhân viên được lưu như sau:

Như chúng ta thấy, việc lưu như trên nếu đổi tên cơ cấu, như Chi Nhánh Ba Đình chẳng hạn thì cũng không sao chỉ nhân viên ở chi nhánh Ba Đình bị cập nhật lại tên cơ cấu tổ chức. Nhưng còn path, trường này được cập nhật khi nào? Như slide thần thánh về Antipatern của SQL mình đã viết ở trên. Việc dùng path này sẽ phức tạp trong trường hợp bị thay đổi, nghĩa là việc cập nhật path khi có sự dịch chuyển cây như chuyển nhánh hoặc chuyển lên cấp chả hạn sẽ phải cập nhật là nhiều phần. Để code đơn giản hơn, team DEV quyết định mỗi khi có thay đổi trên cây cơ cấu (thêm, sửa, xóa) sẽ cập nhật lại toàn bộ trường path này cho cả bảng cơ cấu luôn. Và cập nhật trên tất cả các bảng có lưu trường path. Có thể thấy mỗi lần cập nhật cơ cấu tổ chức (dù chỉ một bản ghi) sẽ phải cập nhật toàn bộ các bảng lưu trường path này có nhiều bảng có hàng triệu bản ghi. Hậu quả database treo cứng, khách hàng la oai oái, còn tôi thì tê tái.
Câu chuyện 2: Chuyện lịch sử chỉnh sửa.
Theo nghiệp vụ mỗi một record sẽ lưu lịch sử chỉnh sửa của nó, theo như những ý tưởng về tốc độ của việc phi chuẩn, DEV team quyết định tạo ra một trường lưu lịch sử chỉnh sửa ngay trên bảng dữ liệu gốc như sau.

Lưu như vậy thì việc lấy lịch sử ra nhanh luôn khỏi phải bàn, việc lưu thì cứ thêm vào cuối, đằng nào cũng thế rồi cộng thêm vào. Đến một ngày đẹp trời, khoảng dưới 1000 năm sau gì đó. Tự nhiên báo lỗi dữ liệu bản ghi quá lớn, và trong màn hình danh sách để cho tiện, dev cũng tải luôn lịch sử về luôn trong khi lấy dữ liệu để theo khuyến cáo nữa là không nên chọc lên server nhiều lần. Qua nhiều thời gian tích lũy lại dữ liệu lịch sử trở thành siêu to khổng lồ, ảnh hưởng nghiêm trọng tới việc tải dữ liệu. Ngoài ra việc tìm kiếm ngày chỉnh sửa cũng khó khăn do lưu chung hết một chỗ không thể dùng câu select thông thường mà lấy được dữ liệu cần thiết, còn việc tải cả nghìn dòng lịch sử về thì vô nghĩa.
Sau đó dev team phải nén đau thương xây dựng sự nghiệp, tạo thêm một bảng lưu lịch sử theo chuẩn hóa, từ đó trở đi việc truy vấn nhanh hơn (ồ sao lưu chuẩn hóa lại nhanh hơn phi chuẩn). Dữ liệu có thể tải lên phân trang, màn hình danh sách không cần load lịch sử chạy mượt mà, việc thêm dữ liệu cũng đơn giản mà nhanh. Tra cứu dữ liệu cũng tiện theo năm tháng. Lúc xong tôi thấy nhẹ cả người. À mà có dự án khác cũng gặp vấn đề như vậy, còn đồng bộ lên Elastic Seach, nhưng lịch sử to quá treo cả quá trình đồng bộ (Nước mắt lại rơi)
Câu chuyện 3: Chuyện Master Detail.
Trước khi đi vào câu chuyện này tôi giải thích master detail là gì? Ví dụ như facebook thì post của bạn là master, còn các comment là detail. Theo mô hình chuẩn hóa thì bạn sẽ lưu comment ra bảng riêng là bảng comment, còn lưu post ra một bảng khác. Tuy nhiên cũng để tránh JOIN, sợ ảnh hưởng hiệu năng DEV team lại quyết định lưu luôn trong cùng một bảng. Và bài toán trở nên giống với lịch sử. Tuy nhiên có một điều đau thương hơn lịch sử chỉ là thêm vào sau, còn comment có thể chỉnh sửa (trong thực tế mà field khác nghiệp vụ phức tạp và chỉnh sửa nhiều) Và mỗi lần chỉnh sửa lại phải bóc cái cục dữ liệu đó ra, tìm chỗ cần sửa để sửa ( nghe thôi mà đã thấy tim đập chân run rồi). Nghĩa là sau đó việc sửa một comment chạy rất lâu, việc load dữ liệu cũng lâu vì lần nào cũng load hết comment. Chương trình lại chậm, khách hàng lại kêu. Và như các bạn biết đấy. Đơn giản thôi quay lại với những gì quen thuộc KISS à YAGNY lại mang lại nụ cười.
PS: Vậy việc JOIN có ảnh hưởng hiệu năng không? Mọi người thường sợ JOIN nhưng cần phải hiểu một điều, JOIN đáng sợ với dữ liệu lớn, nghĩa là việc JOIN hai bảng lớn với nhau có thể mang lại vấn đề. Tuy nhiên trong câu chuyện 2 và câu chuyện 3. Chúng ta đã xác định rõ bản ghi cần lấy ra. Nên lúc này bản ghi mang đi JOIN chỉ có 1 bản ghi, hơn nữa toàn là theo khóa chính và khóa ngoại (à chuyện khóa ngoại các bạn nhớ luôn phải có index nhé) nên không ảnh hưởng gì tới hiệu năng nhé! Còn việc phi chuẩn có tác dụng chính khi bạn muốn lấy về nhiều bản ghi hoặc điều kiện lấy không phải theo khóa chính và khóa ngoại mà thôi. Nếu truy vấn theo Key việc phi chuẩn là không cần thiết.
Ngoài lề chút mình có một số Job list bạn nào muốn tìm một công việc mới có thể tham khảo link đây nhé
Các bạn có thể Join hai group này để cùng xây dựng cộng đồng lập trình viên level quốc tế nhé
All rights reserved
