Kiến trúc web hiện đại
Bài đăng này đã không được cập nhật trong 8 năm
Tìm hiểu về kiến trúc web.
Trước đây một website đơn giản được tạo ra chỉ người dùng truy cập và sẽ trả về một trang html gồm text và hình ảnh cho người dùng, sau đó sẽ được hiển thị lên web browser. Những website này đơn giản chỉ cần một web application được lưu trữ trên một server, cùng với đó là một địa chỉ ip để người dùng truy cập vào, nó rất đơn giản. Tuy nhiên với các website như hiện này các tính năng, các thành phần của nó cũng phức tạp hơn nhiều đòi hỏi cần có một kiến trúc chung đế áp dụng chung qua đó các web developer có thể hình dung được sự vận hành của web application. Dưới đây là hình ảnh của kiến trúc các ứng dụng web ngày nay:
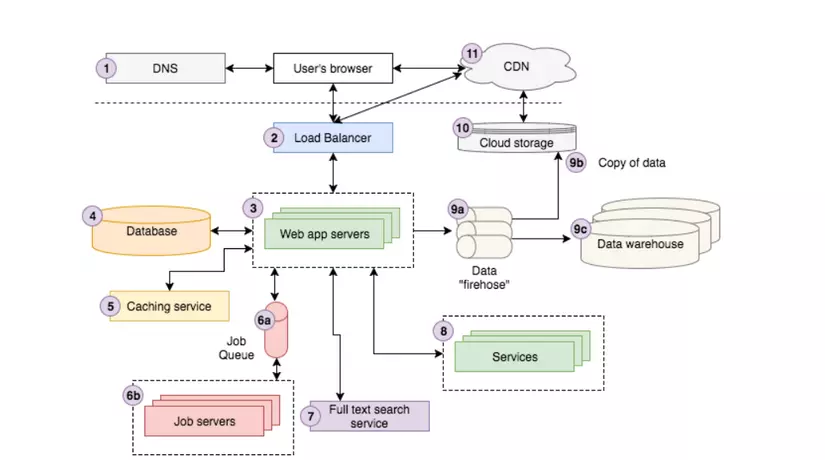
Như ta thấy một ứng dụng web hiện đại có kiến trúc bao gồm rất nhiều thành phần. Ta sẽ đi qua và giải thích rõ cho từng thành phần của nó.
DNS
DNS là viết tắt của "Domain Name Server" nó là công nghệ nền tảng tạo nên mạng lưới các trang web, internet hiện nay. Về cơ bản DNS cung cấp một cặp key/value để tra cứu giữa tên miền (ví dụ google.com) với một địa chỉ IP (ví dụ 85.129.83.120), cái mà yêu cầu khi máy tính chúng ta muốn gửi request tới một server nào đó. Với người dùng khi truy cập thì ta chỉ cần tên miền của trang web, tuy nhiên để máy tính và mạng internet có thể hiểu và đưa ta đến đúng địa chỉ của tên miền đó thì ta cần địa chỉ ip. Ta có thể coi DNS tương tự như một cái danh bạ số điện thoại, tên miền và địa chỉ ip sẽ như tên một người trong danh bạ và số điện thoại của họ, khi ta tìm số điện thoại của một ai đó trong danh bạ nó sẽ tương tự như việc máy tính của chúng ta tìm địa chỉ ip của một tên miền thông qua DNS.
Load balancer
Có 2 khái niệm ta cần biết khi mở rộng (scaling) ứng dụng web là:
- Mở rộng theo chiều ngang: nghĩa là chúng ta mở rộng bằng việc thêm nhiều máy móc vào bể tài nguyên đang sử dụng.
- Mở rộng theo chiều dọc: nghĩa là chúng ta mở rộng bằng việc thêm các thành phần giúp tài nguyên có sẵn mạnh hơn (như Ram, Cpu).
Trong phát triển web ta thường sử dụng mở rộng theo chiều ngang hơn, vì một cách đơn giản là nếu một trong số các tài nguyên có vấn đề như: một server bị chết, đường mạng bị chập chờ hoặc có sở dữ liệu bị mất kết nối thì việc mỗi thành phần có nhiều hơn một server cho phép ứng dụng của chúng ta vẫn có thể tiếp tục chạy. Thứ hai là việc mở rộng theo chiều ngang cho phép chúng ta tối giản một vài phần của backend (ví dụ web server, database, các service ...) bằng việc chạy mỗi thành phần trên mỗi server khác nhau mà không nhét chúng vào chúng. Cuối cùng là việc không có một máy tính nào trên thế giới lớn để chúng ta luôn luôn thêm cpu hoặc ram vào chúng, do đó đến một mức tói hạn mà mở rộng theo chiều dọc không thể làm được nữa thì ta cần đến mở rộng theo chiều ngang.
Trở lại với load balance, chúng là công nghệ mà giúp cho mở rộng theo chiều ngang hoạt động được. Nó phần bổ các request, và chuyển chúng tới các server được clone của nhau và gửi trả response của server về cho người dùng. Vì các server xử lý request là như nhau cho nên nhiệm vụ của load balance chỉ là phân bố các request tới các server để các server không bị quá tải.
Web application servers
Có lẽ đây là thành phần quen thuộc nhất đối với web developer. Chúng chứa code logic mà chúng ta tạo nên, thực hiện các code đó tùy thuộc vào request của người dùng, xử lý các request của người dùng và gửi lại html(ngoài ra có thể là json, file ...) cho browser của người dùng. Ngoài ra web app server còn giao tiếp với một vài cơ sở hạ tầng phía sau như databases, tầng caching, job queues, search services, các microservices, data/logging queues... Các web app trên các web app server thường được cài đặt bằng một ngôn ngữ lập trình tùy thuộc vào developer như: PHP, Ruby, Java, C#, Scala..., và thường đi kèm cùng các framework hướng MVC như Laravel, Ruby on rails. Ngoài ra ta cũng có thể sử dụng các nền tảng như: Nodejs cùng Express ...
Database servers
Tất cả các web app hiện nay đều sử dụng một hoặc nhiều database để lưu trữ thông tin. Database cung cấp cách mà ta định nghĩa cấu trúc dữ liệu, thêm dữ liệu mới, tìm kiếm dữ liệu, cập nhật hoặc xóa dữ liệu, thực hiện các tính toán trên dữ liệu nếu cần thiết. Có rất nhiều kiểu cũng như loại cơ sở dữ liệu và chúng đề dựa trên hai cộng nghệ chính về cớ sở dữ liệu:
- SQL: sử dụng cho các cơ sở dữ liệu quan hệ, sql dùng để tạo, truy vấn, cập nhật thêm sửa xóa dữ liệu
- NoSQL: là công nghệ giúp lưu trữ dữ liệu lớn, không chỉ là các dữ liệu quan hệ và còn là các dữ liệu phi quan hệ.
Caching service
Caching service cung cấp một cách để lưu dữ liệu dưới dạng một cặp key/value để giúp cho việc lưu trữ và tìm kiếm thông tin với thời gian O(1). Các ứng dụng thường sử dụng caching service để lưu các kết quả tính toán phức tạp và tốn thời gian, vì vậy có thể lấy lại các kết quả đó mà không mất công tính toán lại. Một ứng dụng có thể cache kết quả từ truy vấn cơ sở dữ liệu, kết quả từ việc gọi một service ngoài, html cho một url ... Có một số ví dụ như sau:
- Google thường cache các kết quả tìm kiếm của các từ thông dụng thay vì tính toán lại mỗi lần tìm kiếm.
- Facebook cache dữ liệu khi ta log in như: dữ liệu các bài post, danh sách bạn bè ...
Có 2 server thông dụng cho caching đó là Redis và Memcache.
Job queue và servers
Hầu hết các web application đều cần thực hiện các công việc bất đồng bộ và chạy ngầm mà không trả về response cho request của người dùng. Ví dụ như việc Google thu thập và đánh index của các trang web trên mạng internet để trả về kết quả tìm kiếm của người dùng, việc này không được thực hiện ngay khi ta tìm kiếm mà thay vào đó Google thu thập các website một cách bất đồng bộ và việc đánh index cũng diến ra tương tự.
Trong khi có nhiều kiến trúc khác nhau để thực hiện các công việc bất đồng bộ thì một trong số cách ta có thể sử dụng là job queue. Nó sẽ gồm 2 thành phần một là kiểu queue áp dụng để lưu các job là lấy các job ra để chạy, hai là một server để chạy các job trong queue.
Job queue sẽ lưu trữ một list job cần phải chạy bất đồng bộ. Một queue đơn giản nhất là FIFO (first in first out) tức các job được lưu trữ theo kiểu job nào vào queue trước sẽ được thực hiện trước. Tuy nhiên để tăng tính linh hoạt cho queue người ta sẽ sử dụng thêm tham số độ ưu tiên của các job, như vậy các job sẽ được lưu vào queue một cách tuần tự nhưng khi thực hiện job thì job nào có độ ưu tiên cao hơn sẽ thực hiện trước. Khi ứng dụng cần một job được chạy hoặc theo lịch đề ra hoặc do người dùng chỉ thị thì ứng dụng sẽ đây job đó vào queue.
Job server xử lý các job. Chúng dự vào job queue để xác định có job nào cần thực hiện hay không, nếu có chúng sẽ đưa job đó ra khỏi queue vào thực hiện.
Full-text search service.
Full-text search service là công nghệ cho phép các web app cung cấp tìm kiếm tất cả các kết quả liên quan đến input mà người dùng nhập vào. Full-text search service dựa vào index ngược để tìm kiếm các tài liệu có chứa từ khóa tìm kiếm.
Trong khi các cơ sở dữ liệu hiện nay có hỗ trợ full-text search, tuy nhiên việc chạy tách biệt việc tìm kiếm full-text là cần thiết để giảm thiểu việc tính toán lưu trữ index ngược cho server, cũng như sẽ được cung cấp công cụ cho việc query dễ dàng hơn. Một số nền tảng Full-text search service hiện nay là ElasticSearch, Sphinx.
Các dịch vụ
Khi ứng dụng của chúng ta đạt đến một độ lớn nào đó thì sẽ có một số tính năng cần được tách ra một cách độc lập như một ứng dụng, tuy nhiên chúng sẽ hỗ trợ cho ứng dụng chính của chúng ta nên được gọi là các services. Các service này sẽ chỉ có phạm vi hoạt động là trong ứng dụng, nó cũng có thể tương tác được với các service khác.
Dữ liệu
Ngày này việc lưu lại mọi dữ liệu phát sinh trong quá trình sử dụng web app, từ đó khai thác thêm các thông tin từ các dữ liệu đó vô cùng quan trọng. Hầu hết các ứng dụng hiện nay đều dựa vào data pipeline (đường ống dữ liệu) để thu thập, lưu trữ, và phân tích dữ liệu. Một data pipeline thường bao gồm 3 giai đoạn:
- Ứng dụng sẽ gửi dữ liệu thường là các sự kiện phát sinh trong quá trình người dùng tương tác với ứng dụng, tới một bộ phận chịu trách nhiệm lưu trữ và xử lý dữ liệu. Dữ liệu sau khi xử lý sẽ được chuyển tới một bộ phận khác. 2 công nghệ hiện nay được cung cấp bởi AWS cho công việc này là Kinesis và Kafka.
- Dữ liệu gốc cùng với dữ liệu đã qua xử lý sau đó được lưu vào cloud storage.
- Sau đó khi cần phân tích dữ liệu gốc và dữ liệu đã qua xử lý sẽ được load và kho dữ liệu.
Cloud storage
Đây là nền tảng giúp ta lưu trữ, truy cập và chia sẻ dữ liệu dễ dàng thông qua internet. Cloud storage giúp chúng ta lưu trữ và truy cập bất cứ cái gì mà chúng ta có thể lưu ở hệ thống file local với lợi ích là ta có thể tương tác được với Cloud storage bằng RESTful API thông qua HTTP. Một trong nhưng Cloud storage nổi tiếng hiện nay là S3 của Amazon.
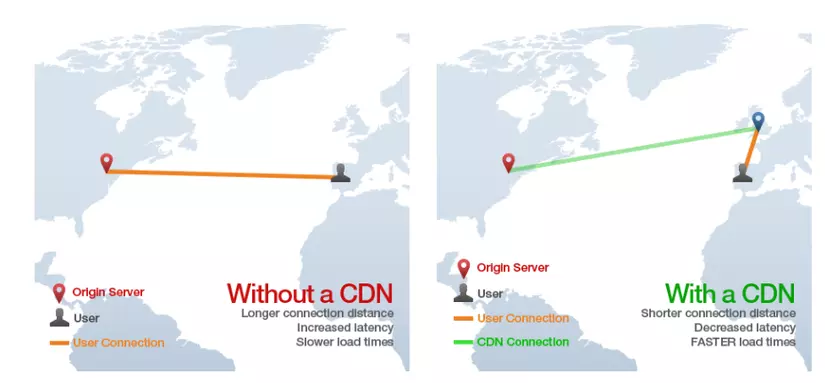
CDN
CND là viết tắt của "Content Delivery Network" là công nghệ cung cấp một cách để phục vụ các tài nguyên như html tĩnh, css, javascript và ảnh thông qua các trang web một cách nhanh chóng và hiệu quả hơn là được lấy từ server gốc. Nó làm việc bằng cách phân tán tài nguyên cho các server khác trên toàn thế giới, khi đó người dùng cuối sẽ tải các tài nguyên từ các server kia thay cho server gốc của các tài nguyên đó. Hình dưới minh họa lợi ích của việc sử dụng CDN:
Tài liệu tham khảo
1.) https://engineering.videoblocks.com/web-architecture-101-a3224e126947
All rights reserved
