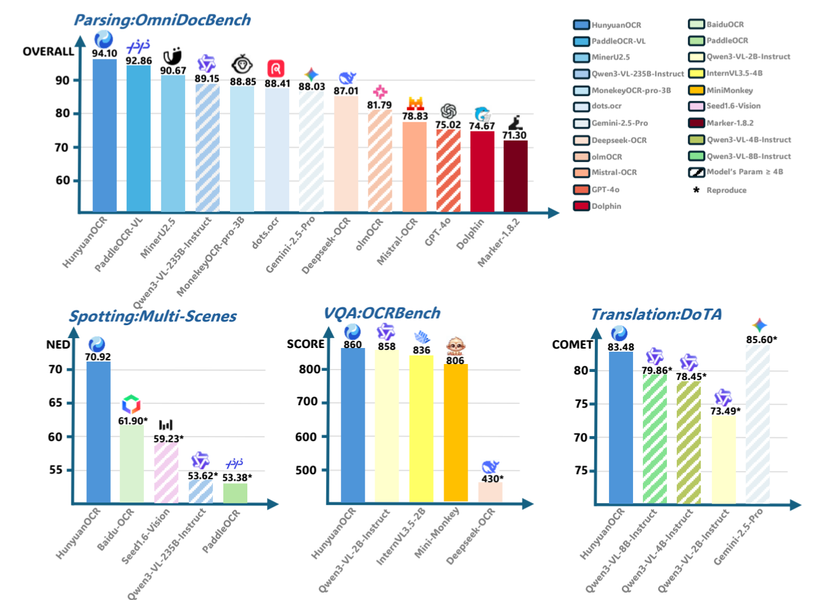
Kiến trúc mô hình Tencent HunyuanOCR
Thay vì sử dụng các pipeline truyền thống phức tạp, HunyuanOCR áp dụng kiến trúc end-to-end (với input là ảnh và ouput sẽ là text), giúp loại bỏ sự tích tụ sai số và giảm chi phí bảo trì. Mô hình đạt kết quả SOTA trong số các VLM dưới 3 tỷ tham số, thậm chí vượt qua các mô hình lớn hơn như Qwen3-VL-4B và các API thương mại trong nhiều kịch bản thực tế.
a. Tổng quan Kiến trúc Hệ thống
Kiến trúc của HunyuanOCR được xây dựng dựa trên triết lý "nhẹ nhưng mạnh", với mục tiêu giải quyết triệt để vấn đề tích tụ sai số (error propagation) thường gặp ở các hệ thống OCR truyền thống. Trong các hệ thống cũ, một sai sót nhỏ ở khâu phát hiện vùng văn bản (detection) có thể dẫn đến thất bại hoàn toàn ở khâu nhận dạng (recognition) và trích xuất thông tin (information extraction). HunyuanOCR loại bỏ rào cản này bằng cách sử dụng một mạng nơ-ron duy nhất xử lý trực tiếp từ hình ảnh sang văn bản cấu trúc.:
- Bộ mã hóa Thị giác Độ phân giải Gốc (Hunyuan-ViT): Dựa trên SigLIP-v2-400M, hỗ trợ độ phân giải đầu vào bất kỳ thông qua cơ chế phân mảnh thích ứng. Điều này bảo toàn tỷ lệ khung hình và chi tiết của các tài liệu dài hoặc bản quét chất lượng thấp.
- Bộ kết nối MLP Thích ứng: Đóng vai trò cầu nối, sử dụng các thao tác nén nội dung thích ứng để giảm độ dài chuỗi token thị giác mà vẫn giữ được thông tin ngữ nghĩa quan trọng từ các vùng dày đặc văn bản.
- Mô hình Ngôn ngữ Nhẹ (Hunyuan-0.5B): Sử dụng kiến trúc XD-RoPE để tích hợp thông tin văn bản 1D, bố cục trang 2D và thông tin không gian-thời gian 3D, cho phép xử lý các tài liệu phức tạp (như nhận dạng đa cột) và suy luận logic xuyên trang.

b. Kiến trúc Mô hình
HunyuanOCR gồm 3 thành phần chính được thiết kế để tối ưu hóa hiệu suất:
1. Native Resolution Visual Encoder (Hunyuan-ViT)
Đây là bộ phận chịu trách nhiệm "nhìn" và trích xuất đặc trưng từ ảnh.
- Nền tảng: Xây dựng trên model SigLIP-v2-400M (một bộ mã hóa hình ảnh tiên tiến nhất hiện nay).
- Cơ chế "Adaptive Patching" (Phân mảnh thích ứng):
- Giải thích: Thay vì ép mọi bức ảnh về hình vuông (làm méo chữ, mất nét), Hunyuan-ViT chia ảnh thành các mảnh (patches) dựa trên tỷ lệ khung hình gốc.
- Tác động: Điều này cực kỳ hữu ích cho các tài liệu dài (như sớ, hóa đơn dài) hoặc tài liệu cực rộng. Nó giữ cho chữ không bị biến dạng và không mất chi tiết.
- Global Attention (Chú ý toàn cục): Tất cả các mảnh ảnh sau khi chia được xử lý đồng thời bởi Vision Transformer. Model hiểu được mối quan hệ giữa một mảnh ở đầu trang và một mảnh ở cuối trang ngay lập tức.
2. Adaptive MLP Connector
Module này đóng vai trò cầu nối, chuyển đổi tín hiệu từ Vision model sang LLM decoder.
- Cơ chế "Learnable Pooling" (Gộp dữ liệu có thể học):
- Giải thích: Ảnh độ phân giải cao tạo ra hàng ngàn token (rất nặng cho bộ não LLM). MLP này thực hiện nén dữ liệu theo chiều không gian một cách thông minh.
- Tác động: Nó giảm bớt các vùng "thừa" như khoảng trắng,... và tập trung giữ lại các vùng "text-dense" (vùng dày đặc chữ).
- Kết quả: Tạo ra một bản tóm tắt thị giác cực kỳ tinh gọn nhưng giàu ngữ nghĩa để đẩy vào LLM, giúp tăng tốc độ xử lý mà không mất độ chính xác.
3. Lightweight Language Model (Hunyuan-0.5B)
- Lõi: Model ngôn ngữ Hunyuan 500 triệu tham số.
- XD-RoPE: Đây là điểm khác biệt lớn nhất. Trong khi các LLM khác dùng mã hóa vị trí 1D , HunyuanOCR dùng XD-RoPE để chia không gian thành 4 không gian độc lập: Văn bản (Text), Chiều cao (Height), Chiều rộng (Width), và Thời gian (Time).
- Giải thích: Nó nhúng tọa độ , và thứ tự thời gian vào từng token chữ
- Tác động: Giúp bộ não AI hiểu được cấu trúc 2D của trang giấy (cột trái, cột phải, bảng biểu) một cách tự nhiên như con người nhìn ảnh, thay vì coi nó như một chuỗi chữ dài dằng dặc.
📌 Cơ chế XD-RoPE Trong các mô hình RoPE tiêu chuẩn, vị trí chỉ được mã hóa theo dạng chuỗi 1D, điều này không đủ để mô tả mối quan hệ giữa các đoạn văn bản trong một trang giấy có nhiều cột hoặc bảng biểu. XD-RoPE phân rã thông tin vị trí thành bốn không gian con riêng biệt:
- Thứ tự văn bản 1D: Duy trì luồng đọc tuần tự của các từ.
- Chiều cao 2D: Xác định vị trí dọc của văn bản, giúp phân biệt giữa các dòng khác nhau.
- Chiều rộng 2D: Xác định vị trí ngang, cực kỳ quan trọng để duy trì cấu trúc cột trong các tài liệu phức tạp.
- Thứ tự thời gian: Được tối ưu hóa cho việc trích xuất phụ đề video, cho phép mô hình theo dõi sự xuất hiện của văn bản qua các khung hình. → Nhờ XD-RoPE, HunyuanOCR có khả năng "vẽ" lại các khung bao (bounding boxes) hoặc tạo ra các thẻ HTML/Markdown chính xác mà không cần một mô-đun phân tích bố cục (layout analysis) riêng biệt.
4. End-to-End Optimization
Khác hoàn toàn với các model như PaddleOCR (vốn cần chia ra model Layout riêng, model OCR riêng), HunyuanOCR là một khối thống nhất. Quá trình huấn luyện và suy luận diễn ra đồng thời trên một kiến trúc duy nhất (End-to-End paradigm).
- Tác động:
- Loại bỏ hoàn toàn "Error Propagation" (Lỗi dây chuyền): Trong các hệ thống cũ, nếu model Layout Analysis cắt sai một khối văn bản, model OCR phía sau sẽ đọc sai theo. HunyuanOCR tự mình nhìn và tự mình đọc, nên nó tự sửa lỗi cho chính mình trong quá trình suy luận.
- Giúp xử lý cực tốt các loại tài liệu có bố cục hỗn hợp (hình ảnh, bảng biểu, chữ đè lên nhau) mà không cần các bước hậu xử lý phức tạp.
c. Task Design
1. Spotting (Định vị và Nhận diện dòng chữ)
Đây là khả năng cơ bản nhất của OCR.
- Mục tiêu: Tìm ra vị trí (tọa độ) và nội dung của văn bản.
- Định dạng Output chuẩn hóa: Sử dụng cặp thẻ <ref> và <quad>.
- Ví dụ: <ref>Nội dung chữ</ref><quad>(x1,y1),(x2,y2)</quad>
- Chuẩn hóa tọa độ: Tất cả tọa độ được đưa về khoảng [0, 1000]. Điều này giúp model hoạt động ổn định bất kể ảnh đầu vào có độ phân giải lớn hay nhỏ.
2. Parsing (Phân tích cấu trúc tài liệu)
HunyuanOCR cực mạnh trong việc chuyển đổi hình ảnh thành mã máy tính có thể đọc được (Markdown/HTML/LaTeX).
- Phân tích chi tiết (Fine-Grained):
- Công thức: Trả về mã LaTeX.
- Bảng biểu: Trả về mã HTML (giữ nguyên cấu trúc hàng/cột).
- Biểu đồ: Trả về mã Mermaid cho lưu đồ (flowcharts) và Markdown cho các loại biểu đồ khác.
- Phân tích toàn diện (End-to-End):
- Quét toàn bộ trang giấy, tự động bỏ qua Header/Footer.
- Sắp xếp nội dung theo Thứ tự đọc (Reading Order).
- Hỗ trợ cả ảnh đời thực (biển báo, bao bì sản phẩm, giao diện UI).
3. IE & VQA (Trích xuất thông tin & Hỏi đáp thị giác)
Đây là phần thể hiện "trí thông minh" của bộ não LLM bên trong.
- Information Extraction (IE):
- Đa dạng tên miền Tối ưu hóa cho hơn 30 loại giấy tờ (CCCD, hộ chiếu, hóa đơn, biên lai...).
- Điều khiển bằng lệnh Bạn có thể yêu cầu trích xuất một trường cụ thể (ví dụ: "Số tiền là bao nhiêu?") hoặc trích xuất một danh sách các trường và trả về định dạng JSON.
- Phụ đề video Trích xuất phụ đề từ ảnh chụp màn hình video.
- Visual Question Answering (VQA
- Không chỉ đọc chữ, model có thể suy luận Ví dụ: Tính toán con số trên hóa đơn, hiểu mối quan hệ không gian ("Cái gì nằm bên trái cái gì?").
4. Text Image Translation (Dịch thuật hình ảnh)
Đây là khả năng hiếm có ở các model OCR thuần túy.
- Đa ngôn ngữ: Hỗ trợ hơn 14 ngôn ngữ (Pháp, Đức, Nhật, Hàn...) dịch sang tiếng Trung hoặc tiếng Anh.
- Dịch thuật giữ nguyên cấu trúc (Structured Translation):
- Không chỉ dịch chữ suông, model có thể dịch một trang tài liệu phức tạp mà vẫn giữ nguyên định dạng bảng (HTML) và công thức (LaTeX).
- Xử lý tốt cả ảnh chụp tự nhiên (biển báo, poster) và tài liệu quét (scanned documents).
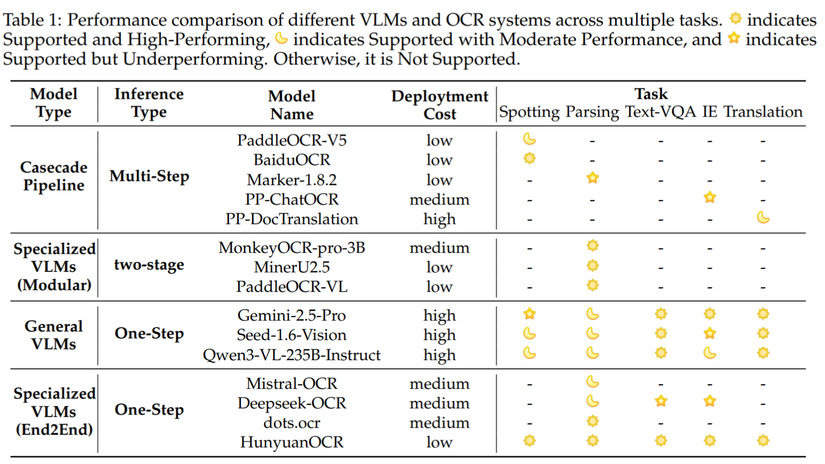
5. Bảng tổng hợp luồng Prompt (Câu lệnh) cho Docs:
| Nhiệm vụ | Prompt mẫu (Tiếng Anh) | Định dạng Output |
|---|---|---|
| Spotting | Detect and recognize text... | <ref>...<quad>... |
| Công thức | Identify the formula... | LaTeX |
| Bảng biểu | Parse the table into HTML | HTML |
| Biểu đồ | Parse the chart... | Mermaid / Markdown |
| Toàn bộ trang | Extract all information... | Markdown (cấu trúc hóa) |
| Trích xuất (IE) | Extract [key1, key2] in JSON | JSON |
| Dịch thuật | Extract all text and translate... | Văn bản dịch |
d. Luồng chi tiết
Bước 1: Tiếp nhận Đa dạng Đầu vào (Input)
Hệ thống chấp nhận 3 nhóm hình ảnh chính (phía dưới và giữa ảnh):
- Document & Charts: Tài liệu văn bản, biểu đồ, công thức toán học, bảng biểu phức tạp.
- Cards & Receipts: Các loại giấy tờ tùy thân (CCCD), hóa đơn, biên lai.
- Scene Text: Chữ trong điều kiện thực tế (biển hiệu, poster, chữ trên đường phố).
Bước 2: Mã hóa Thị giác (Vision Encoding)
Ảnh được đưa vào khối Native Resolution Visual Encoder (Hunyuan-ViT):
- How: Sử dụng kiến trúc ViT hỗ trợ độ phân giải gốc. Nó nhìn vào hình ảnh và trích xuất các đặc trưng chi tiết nhất (nét chữ, màu sắc, bố cục).
- Đặc điểm: Không làm méo ảnh, giữ nguyên tỷ lệ để không mất chi tiết của các chữ nhỏ.
Bước 3: Chuyển đổi và Nén thông tin (MLP Connector)
Dữ liệu từ "mắt nhìn" đi qua Adaptive MLP Connector:
- How: Nó biến các đặc trưng hình ảnh thành các Visual Tokens (ô màu cam).
- Vai trò: Đây là cầu nối giúp bộ não ngôn ngữ hiểu được hình ảnh. Nó nén dữ liệu để loại bỏ phần thừa, chỉ giữ lại các "tín hiệu thị giác" quan trọng nhất.
Bước 4: Kết hợp Chỉ thị (Instruction) & Suy luận (LLM Decoder)
Đây là giai đoạn "Não bộ" làm việc (Lightweight Language Model - Hunyuan-0.5B):
- Input song song: Model nhận cùng lúc Visual Tokens (từ ảnh) và Text Tokens (từ câu lệnh/prompt của người dùng - ô màu tím).
- How: Model 0.5B sử dụng cơ chế XD-RoPE để hiểu vị trí 2D của các khối văn bản trên ảnh.
- Reasoning: Nó không chỉ đọc chữ mà còn suy luận. Ví dụ: Nếu lệnh là "Hãy trích xuất JSON", nó sẽ tự tìm đúng thông tin để điền vào khóa (key) tương ứng.
Bước 5: Đầu ra đa nhiệm (Output Tokens)
Dựa trên câu lệnh, hệ thống sinh ra các Output Tokens ứng với 4 nhóm nhiệm vụ chính:
1. Spotting
- Prompt "Detect and recognize text..."
- Kết quả Trả về nội dung chữ kèm tọa độ trong thẻ <ref> và <quad>.
- Ví dụ trong ảnh: Chữ trên biển hiệu cổ được khoanh vùng tọa độ chính xác.
2. Parsing
- Prompt "Extract all information in markdown..."
- Kết quả Chuyển đổi tài liệu giấy thành Markdown, HTML (cho bảng), LaTeX (cho công thức).
- Ví dụ trong ảnh: Một trang đề thi phức tạp được dựng lại thành văn bản cấu trúc với công thức toán học hiển thị chuẩn xác.
3. IE/VQA
- Trích xuất thông tin (IE Chuyển hóa hóa đơn/biên lai thành file JSON.
- Hỏi đáp (VQA Trả lời các câu hỏi về biểu đồ hoặc nội dung ảnh (Ví dụ: "Nước nào có tỷ lệ cao nhất?" -> "Germany").
- Công thức Nhận diện và viết lại công thức toán học dưới dạng mã LaTeX.
4. Image Translation
- Prompt "Translate text in image to Chinese."
- Kết quả Nhận diện ngôn ngữ gốc (ví dụ: tiếng Indonesia) và dịch thẳng sang ngôn ngữ đích (tiếng Trung/Anh) trong khi vẫn hiểu ngữ cảnh của ảnh.
Kết luận
HunyuanOCR cho thấy xu hướng mới của OCR hiện đại: không chỉ dừng lại ở việc “đọc chữ”, mà còn có khả năng hiểu bố cục, trích xuất thông tin, chuyển đổi tài liệu sang Markdown/HTML/LaTeX và hỗ trợ nhiều tác vụ thị giác-ngôn ngữ trong cùng một mô hình end-to-end. Với kiến trúc gọn nhẹ nhưng được tối ưu tốt, HunyuanOCR là một hướng tiếp cận đáng chú ý cho các bài toán xử lý tài liệu thực tế, đặc biệt khi cần giảm độ phức tạp của pipeline OCR truyền thống và tăng khả năng xử lý các tài liệu có bố cục phức tạp.
Tài liệu tham khảo & Link đính kèm:
All rights reserved
