Khám Phá Kiến Trúc Kafka: Nền Tảng Cho Xử Lý Dữ Liệu Thời Gian Thực
Trong thế giới công nghệ ngày nay, xử lý dữ liệu theo thời gian thực là một yêu cầu quan trọng. Apache Kafka, một nền tảng xử lý dữ liệu phân tán, đã trở thành công cụ chủ chốt cho việc truyền tải và xử lý luồng dữ liệu lớn. Với khả năng mở rộng, độ tin cậy và hiệu suất cao, Kafka giúp các doanh nghiệp thu thập, quản lý và phân tích dữ liệu một cách hiệu quả.
1. Một số case study mình đã sử dụng Kafka
Trong lĩnh vực chứng khoán, trái phiếu
- Lệnh điều kiện (Stream tín hiệu giá thị trường)
- Hệ thống notification (Tạo nhiều luồng stream channel phục vụ hàng triệu message notification, email, sms)
- Đồng bộ dữ liệu giữa cache datasource và persistence datasource
- Đồng bộ thông tin tài sản
- Robo trader trái phiếu doanh nghiệp
- Bảng giá V.v…. Trong lĩnh vực thương mại điện tử:
- Quản lí kho
- ETL dữ liệu data warehouse V.v….
Trải qua nhiều dự kiến trúc hệ thống từ đơn giản đến phức tạp, có những hệ thống tải lớn, đòi hỏi tính nhất quán cao. Việc sử dụng Kafka đem lại sự tin tưởng và độ tin cậy rất cao và là một thành phần không thể thiếu trong khác kiến trúc mình thiết kế và triển khai.
Trong quá trình triển khai có rất nhiều điều thú vị mình sẽ chia sẻ dần qua các bài viết, từ việc cách sử dụng, lưu ý các config từ Kafka client cho đến Kafka server để phù hợp với những bài toán khác nhau.
Bài viết này mình sẽ tóm tắt lại kiến trúc của Kafka để giúp anh em có thể hệ thống lại các thành phần chủ yếu của Kafka:
2. Tổng quan kiến trúc
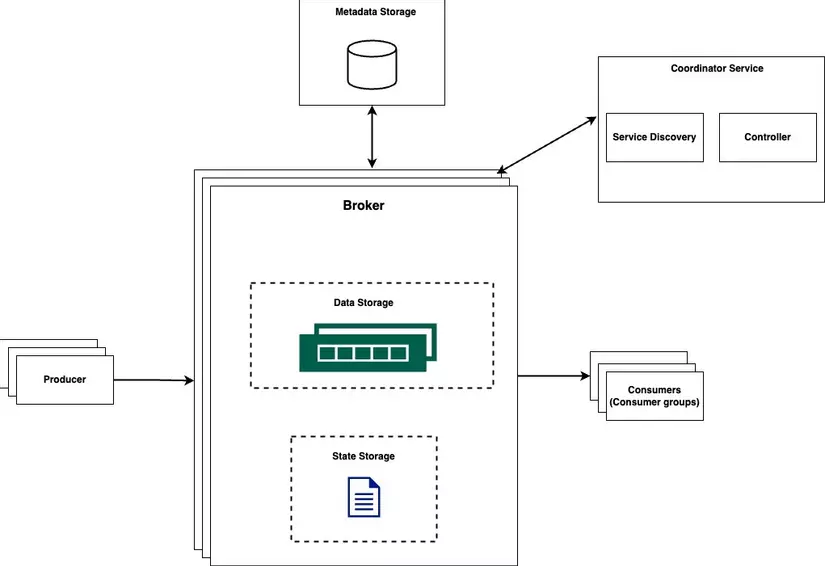
Kafka clients:
- Producer: đẩy thông điệp (message) vào các chủ đề (cụ thể) cụ thể.
- Consumer group: đăng ký vào các chủ đề và tiêu thụ thông điệp. Kafka servers:
- Core Service và Lưu trữ
- Broker: chứa nhiều phân vùng (partitions). Một phân vùng chứa một tập hợp các thông điệp của một chủ đề.
- Lưu trữ (storage): Data storage: thông điệp được lưu trữ trong các phân vùng. State storage: trạng thái của consumer được quản lý bởi state storage. Metadata storage: cấu hình và thuộc tính của các chủ đề được lưu trữ trong metadata storage.
- Coordination Service: Service discovery: xác định các broker đang hoạt động. Leader election: một trong các broker được chọn làm “active controller” hoạt động. Chỉ có một controller hoạt động trong cụm. Controller hoạt động chịu trách nhiệm phân phối các phân vùng. Apache Zookeeper hoặc etcd thường được sử dụng để bầu chọn "active controller".
3. Thông tin kết nối
Nếu anh em muốn trao đổi thêm về bài viết, hãy kết nối với mình qua LinkedIn và Facebook:
- LinkedIn: https://www.linkedin.com/in/nguyentrungnam/
- Facebook: https://www.facebook.com/trungnam.nguyen.395/
Rất mong được kết nối và cùng thảo luận!
All rights reserved
