Khai phá dữ liệu và lớp bài toán khai thác các tập phổ biến (P2).
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Ở bài viết lần trước Khai phá dữ liệu và lớp bài toán khai thác các tập phổ biến mình đã trình bày cho các bạn về định nghĩa, ứng dụng của việc khai thác các tập phổ biến từ cơ sở dữ liệu giao dịch trong thực tế, đồng thời giới thiệu về thuật toán Apriori - thuật toán đầu tiên, cũng là thuật toán kinh điển nhất giúp đặt nền móng phát triển cho lớp bài toán này. Trong bài viết lần này mình sẽ giới thiệu cho các bạn về hai vấn đề: "Thuật toán FP-Growth" và "So sánh ưu nhược điểm của thuật toán FP-growth và Apriori".
Đặt vấn đề
Vấn đề cốt lõi của thuật toán Apriori
- Sử dụng tập phổ biến thứ k-1 để xây dựng tập ứng viên k.
- Quét toàn bộ cơ sở dữ liệu giao dịch, khớp mẫu để đếm tần suất xuất hiện từng tập ứng viên được sinh ra.
Hạn chế
Số lượng khổng lồ các tập ứng viên được sinh ra:
- tập phổ biến 1-itemsets sẽ sinh ra tập ứng viên 2-itemsets.
- Để khai thác được một tập phổ biến có 100 phần tử, ví dụ cần tạo ra - xấp xỉ tập ứng viên.
Phải quét cơ sở dữ liệu rất nhiều lần: Cần hoặc lần quét, với là chiều dài hay số phần tử của tập phổ biến dài nhất.
Câu hỏi đặt ra là vậy có cách nào để có thể khai thác được các tập phổ biến mà không cần phải sinh ra các tập ứng viên không? Câu trả lời là "Có" và đây chính là lí do thuật toán FP-Growth ra đời! 
Thuật toán FP-Growth
Nén một cơ sở dữ liệu lớn vào một cấu trúc cây phổ biến (ở đây là FP-tree)
- Cô đọng (các thông tin chính) nhưng vẫn đủ để khai thác các tập phổ biến
- Tránh được vấn đề "tốn kém" do phải duyệt cơ sở dữ liệu nhiều lần.
Phát triển một phương pháp khai thác tập phổ biến dựa trên cây FP-tree hiệu quả
- Phương pháp chia để trí: phân tách các nhiệm vụ khai thác thành vấn đề nhỏ hơn.
- Tránh được bước sinh ra các tập ứng viên: chỉ kiểm tra cơ sở dữ liệu phụ.
Ý tưởng
- Nén cơ sở dữ liệu vào cây FP-tree, chỉ giữ lại thông tin liên kết (kết hợp) của các hạng mục (tập phổ biến).
- Chia cơ sở dữ liệu nén thành các cơ sở dữ liệu có điều kiện, mỗi cơ sở dư liệu được chia ra ứng với một hạng mục phổ biến và ta sẽ khai thác các cơ sở dữ liệu này một cách độc lập.
Tính chất
Thuật toán FP -Growth được xây dựng dựa trên hai tính chất cốt lõi:
- Hai giao dịch có chứa cùng một số các mục, thì đường đi của chúng sẽ có phần (đoạn) chung.
- Càng nhiều các đường đi có phần tử chung, thì việc biểu diễn bằng FP-Tree sẽ càng gọn.
Các bước thực hiện
Bước 1 - Nén cơ sở dữ liệu giao dịch gốc vào cây FP-tree
- Quét cơ sở dữ liệu một lần, tìm các tập phổ biến 1-itemsets (chỉ có một hạng mục hay phần tử).
- Sắp xếp các tập phổ biến tìm được theo thứ tự giảm dần của độ phổ biến (tần số).

- Quét lại cơ sở dữ liệu lần 2, xây dựng một cây FP-tree bắt đầu với hạng mục phổ biến nhất trong mỗi giao dịch.

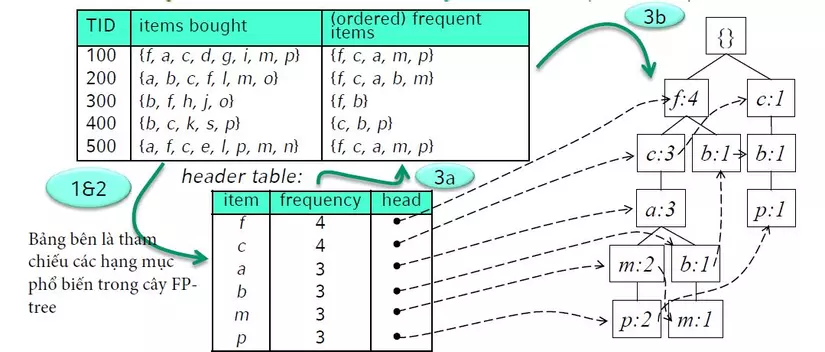
Bước 2 - Các bước chính để khai thác các tập phổ biến trên cây FP- tree - cây FP -tree có điều kiện
-
Duyệt từng hạng mục phổ biến (1-itemsets) theo thứ tự tăng dần của tần số (p, m, b, a, c, f). Với mỗi hạng mục, xây dựng cơ sở mẫu điều kiện và các cây FP-tree có điều kiện tương ứng của nó:
-
Bắt đầu với hạng mục p, cơ sở mẫu điều kiện của nó là tất cả các đường đi tiền tố của cây FP-Tree khi duyệt từ nút gốc {} đến nút p, các đường đi này chính là fcam:2 và cb:1 ( trong đó số theo sau là số lần xuất hiện của nút p tương ứng với mỗi tiền tố đó).
-
Xây dựng cây FP-Tree có điều kiện từ mẫu trên bằng cách trộn tất cả các đường đi và giữ lại các nút có tần số do :
fcam:2 và cb:1 trộn lại thành f:2, c:3, a:2, m:2, b:1; chỉ có c:3 là thoả mãn điều kiện.Do đó, các mẫu phổ biến chứa p là: p, cp.
Làm tương tự cho các hạng mục còn lại, ta thu được bảng dưới đây.
Item Cơ sở mẫu điều kiện FP-Tree điều kiện Các mẫu phổ biến p {fcam:2, cb:1} {c:3}-p p, cp m {fca:2, fcab:1} {f:3, c:3, a:3}-m m, fm, cm, am, fcm, cam, fam, fcam b {fca:1, f:1, c:1} ∅ b a {fc:3} {f:3, c:3}-a a, fa, ca, fca c {f:3} {f:3}-c c, fc f ∅ ∅ f
So sánh hai thuật toán Apriori và FP-Growth
Hai thuật toán trên sẽ được so sánh dựa trên 6 tiêu chí: kỹ thuật, chiến lược tìm kiếm, việc sử dụng bộ nhớ, số lần quét cơ sở dữ liệu, thời gian thực hiện và hiệu quả các thuật toán trên các bộ dữ liệu khác nhau
- Kĩ thuật: Thuật toán Apriori sử dụng hai tính chất của Apriori để thực hiện quá trình kết hợp sinh ra các tập ứng viên và loại bỏ các tập ứng viên không phù hợp, xây dựng dần các tập phổ biến từ dưới lên. Thuật toán FP Growth xây dựng cây FP- tree rồi từ đó xây dựng cơ sở mẫu điều kiện (conditional pattern-base) và các FP-tree có điều kiên (condition FP-tree) thỏa mãn độ hỗ trợ tối thiểu minSup.
- Chiến lược tìm kiếm: Apriori sử dụng chiến lược tìm kiếm theo chiều sâu còn FP Growth sử dụng chiến lược chia để trị.
- Sử dụng bộ nhớ: Thuật toán Apriori đòi hỏi không gian bộ nhớ lớn khi xử lý số lượng các tập ứng cử viên candidate itemsets được tạo ra. Thuật toán FP Growth đòi hỏi ít bộ nhớ hơn do cấu trúc cây nhỏ gọn của nó và khai phá các tập phổ biến frequent itemsets mà không phải thông qua quá trình sinh tập ứng cử viên candidate itemsets.
- Số lần quét cơ sở dữ liệu: Thuật toán Apriori thực hiện nhiều lần quét để có thể tạo ra các tập ứng viên candidate itemsets. Thuật toán FP Growth chỉ cần quét cơ sở dữ liệu đúng hai lần.
- Thời gian thực hiện: Trong Apriori, thời gian thực hiện thuật toán bị lãng phí nhiều ở quá trình mỗi lần sinh ra các tập ứng viên. Với đặc thù của chiến lược sử dụng trong FP Growth đã nêu ở trên, nó yêu cầu ít thời gian thực hiện hơn so với giải thuật Apriori.
- Hiệu quả trên các bộ dữ liệu: Apriori làm việc tốt với cơ sở dữ liệu lớn. FP-Growth làm việc tốt với các cơ sở dữ liệu nhỏ và các tập phổ biến sinh ra không quá dài (độ dài lớn nhất của một tập frequent itemset không quá lớn).
Tài liệu tham khảo
- KAVITHA, M.; SELVI, ST Tamil. Comparative Study on Apriori Algorithm and Fp Growth Algorithm with Pros and Cons. International Journal of Computer Science Trends and Technology (I JCS T)–Volume, 2016, 4.
- Ludwig-Maximilians-Universität München Institut für Informatik Lehrstuhl für Datenbanksysteme und Data Mining Oettingenstraße 67 80538 München, Germany: https://www.dbs.ifi.lmu.de/Lehre/KDD/SS16/skript/3_FrequentItemsetMining.pdf
- https://nhannguyen95.github.io/bai-tap-khai-pha-tap-pho-bien-bang-thuat-toan-fp-growth/
All rights reserved
