Kafka nó làm được những gì
Bài đăng này đã không được cập nhật trong 3 năm
Ở lời mở đầu của series bài viết này thì mình cũng đã giới thiệu qua về bài toán của LinkedIn và yêu cầu cụ thể rõ ràng 🙂
Và cũng như lần trước anh/em hãy chuẩn bị cho mình một ly trà ngồi xuống thưởng thức cho tỉnh táo và để thêm hiểu biết của mình về Apache Kafka nhé 😀
Để trả lời cho tiêu đề bài viết thì mình cùng tìm hiểu từ viên gạch đầu tiên xây dựng lên nó. Sau khi bắt tay vào làm và cho tới thời điểm hiện tại các ông thần trong đội ngũ phát triển Kafka đã xây lên "Architecture Style" cho nó như sau:
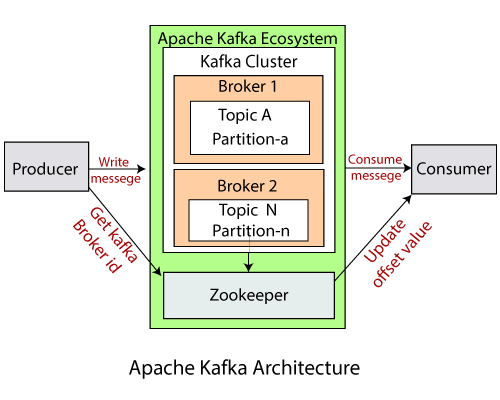
Kafka được thiết kế và triển khai theo mô hình phân tán gồm Servers và Clients tương tác với nhau thông qua giao thức TCP
Servers một hoặc nhiều máy tính cá nhân, máy ảo trong một hệ thống on-premise hoặc các máy chủ server cloud được cài Kafka gọi là Broker kết nối với nhau thành một cụm nên chúng ta gọi nó là Kafka Cluster và được quảng cáo như sau:
- High scalable (dễ dàng mở rộng) tức là anh em chỉ cần cài Kafka lên máy và cấu hình thêm nó vào cụm cluster là oke done.
- High reliable (Độ tin cậy cao): Mình tạm giải thích nó như sau một ngày không đẹp trời cho lắm ngoài biến thì bão cấp độ 11 12 sóng to gió lớn, trong nhà thì thì gió thổi lạnh buốt dev hoặc System Admin sau một ngày làm việc mệt mỏi trở về nhà chỉ muốn sớm được lên giường quấn chăn làm "ổ" cho mình ngủ vắt lưỡi thì song song với đó cá mập hoặc có con chuột nào đó ngứa răng nhảy vào cắn cái gì đó làm một server trong cụm Cluster lăn ra bất tỉnh, Alert thì bắn ầm ĩ trong sự vô vọng thì các máy khác trong cụm cluster đó sẽ tiếp quản công việc của máy server đã "quang tèo " và đảm bảo hoạt động liên tục mà không bị mất mát dữ liệu .
- High durable (Dữ liệu có độ tin cậy cao): Event được lưu trữ xuống ổ cứng với thời gian bạn mong muốn.
- High performance (thông lượng cao): Broker có thể xử lý hàng TB data mà không gặp nhiều vấn đề về performance (yeah tuyệt vời ông mặt trời)
(Đúng yêu cầu đề bài đặt ra 😀)
Client hiểu một cách đơn giản ở đây là các Application/ Service của bạn được viết bằng các ngôn ngữ như Java, Go, Python.... có sử dụng các thư viện(Open Source hoặc Có tính phí) được cộng đồng hoặc một tổ chức nào đó tạo ra để hỗ trợ kết nối và tương tác với các máy chủ Kafka trong cụm Cluster được nói đến ở trên.
Tương tác ở đây có thể là thực hiện produce, consume hoặc process stream event lên cụm Cluster Kafka
Và tới đây thì câu hỏi tiêu đề của bài viết cũng đã phần nào được trả lời 😂
Mình tóm tắt lại tổ hợp 3 chức năng chính như sau:
- Publish (ghi) và Subscribe (Đọc/nhận) event
- Xử lý các luồng sự kiện (process stream) khi có sự kiện xảy ra (khi có event được publish tới cụm Kafka).
- Lưu trữ sự kiện (Event) với thời gian bạn mong muốn.
Nghe có vẻ khá là khó hiểu 🤔nhưng không sao đó là cái tổng quan mình cùng đi chi tiết và cụ thể từng cái một.
Anh em đón đọc các bài cụ thể chi tiết của mình nhé.
Cảm ơn anh em rất nhiều.
All rights reserved
