Kafka những khái niệm, thuật ngữ và giải thích bài bản
Bài đăng này đã không được cập nhật trong 3 năm
Xin chào anh em đã tới hoặc quay trở lại với Series vén màn sự thật về Apache Kafka của mình. Nếu có anh em nào lần đầu tới đây thì anh em có thể đọc từ đầu series từ đây link . (anh em đừng nghĩ link gì gì đó nhé 😆😆 )
Vẫn như mọi khi, anh em chuẩn bị cho mình một ly trà ngồi xuống thưởng thức và nạp thêm cho mình thêm kiến thức về công cụ rất hữu ích này nhé.
Bài viết này mình sẽ cung cấp các thông tin bổ sung cho 1 số thành phần của các khái niệm ở bài trước trong series này để anh em có thể vững niềm tin hơn trong việc triển khai 1 hệ thống Kafka cho mình và trong công việc.
1. Message Keys, Message Offsets and Serializer
Mỗi Event message bao gồm các thông tin đó là:
- 1 cặp
keyvàvaluelưu trữ dưới dạng binary có thể là null - (Định dạng message) trong kafka message có thể ở định dạng file nén như: gzip, none, snappy, lz4, zstd
- Header (Optional) bao gồm nhiều các cặp key và value
- Thông tin về Partition và Offset id (nhận sau khi message được bắn vào Topic)
- Timestamp do hệ thống hoặc user set
Lưu trữ message trong Kafka key == nullthì message sẽ được round-robin tới các partition trong 1 topic .key != nullthì tất cả các message chung 1 key sẽ được lưu trữ trong cùng 1 partition (như ở bài trước mình có đề cập tới) để xử lý việc này thì trước khi 1 message được quyết định đưa vào partition nào thì Producer đã có 1 Partitioner logic để xử lý và đưa ra quyết định.
Và để tăng tốc độ đọc của Kafka Broker thì khuyến khích ae nên Serialize Key và Value của message trước khi gửi. (Mặc dù Kafka cũng đã hỗ trợ các serializers cho các định dạng JSON và Protobuf)
2. Kafka Topic Replication.
Mình xin phép nhắc lại chỗ này 😄😄😄 .
Kafka đã được thiết kế với khả năng chịu lỗi trong thời gian hoạt động và đảm bảo dữ liệu chính xác là 1 trong số các chức năng cốt lõi . ở bài trước mình cũng đã có giải thích qua về vấn đề này nhưng hôm nay mình sẽ giải thích kỹ hơn.
Kafka Topic Replication ở đây có nghĩa là Kafka sẽ không chỉ lưu dữ liệu trên 1 Broker mà là trên nhiều Broker.
3. Kafka Topic Replication Factor
Có thể hiểu nôm na nó chính là thông số cấu hình số topic sẽ được tạo ra?
- Nếu = 1 có nghĩa là không có replication loại này ae chỉ nên cấu hình ở môi trường dev
- Hầu hết các chuyên gia khuyên nên để = 3 vì nó cung cấp được khả năng cân bằng giữa việc các broker bị
quang tèovà chi phí mà 1 broker cần để hoạt động.
4. Kafka Partitions Leader và Replicas
Trong 1 cụm Cluster Kafka sẽ luôn có 1 Kafka broker có nhiệm vụ là gửi và nhận message từ client nó được gọi là Leader Broker và các Topic nằm trên nó cũng chính là các Topic Leader. bất kỳ các broker nào được sao chép và lưu trữ data cho các partition thì được gọi là Replica. cũng do vậy mà các partition cũng có 1 leader và nhiều Replica.
Ví dụ hình dưới 1 cụm cluster gồm 3 broker và 2 eplication factor cho ae dễ hình dung :
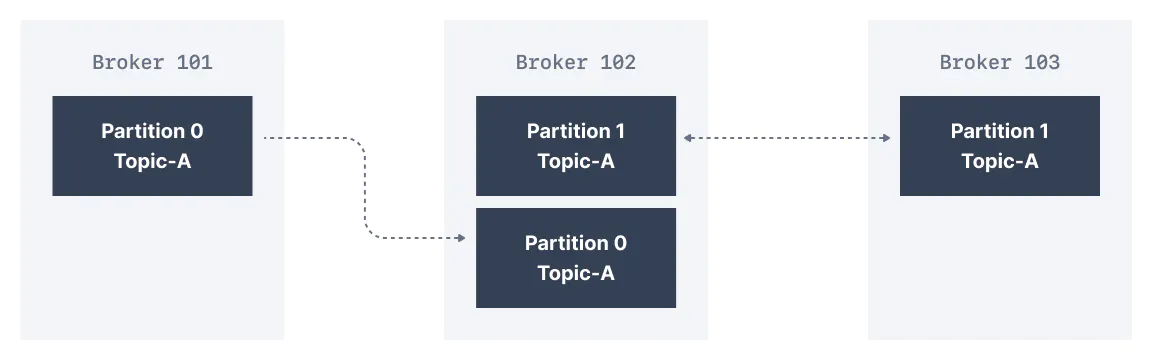
Khi mà message được ghi xuống Partition 0 của Topic-A trong Broker 101 (Leader) thì nó cũng được ghi xuống Broker 102 nó cũng có 1 Partition 0 đóng vai trò làm replica.
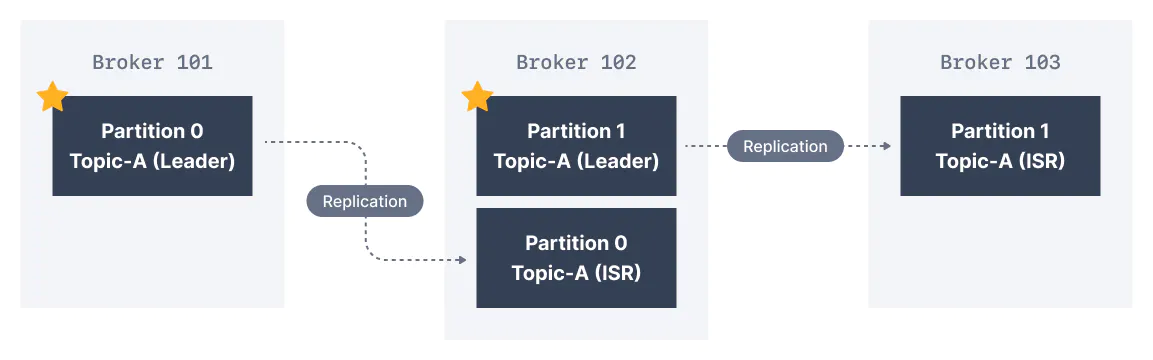
5. In-Sync Replicas (ISR).
Nó để ám chỉ rằng những Replica sẵn sàng được lên làm Leader Broker cho 1 partition. Bất kỳ những replica khác không sẵn sàng lên làm Leader thì gọi là out of sync.
Hình ảnh mô tả cho nó sẽ như sau:
6. Tiếp theo là Kafka Consumer và Kafka Consumers Group.
Như anh em đã biết được Consummers có thể consume message từ Kafka topics partitions và mình cũng đã đề cập tới có thể có nhiều consumer cùng consume cùng 1 Topic và cùng 1 Group id group.id thì chúng được gọi là là Consumer Group
Kafka consumers sẽ tự động sử dụng 1 GroupCoordinator và ConsumerCoordinator sẽ điều phối các comsumers to 1 partition và đảm bảo rằng việc cân bằng tải cho các consumes trong cùng một group.
Một lưu ý quan trọng mỗi Topic partition chỉ được điều phối trên 1 Consumer trong 1 Consumers Group nhưng mà 1 consume trong 1 group có thể consume vào nhiều partition khác nhau của 1 Topic và nó phải nằm trên Kafka Broker Leader (hay chính là Topic Leader).
Từ phiên bản Kafka 2.4 đã cho phép consumers đọc từ in-sync replicas, việc này cải thiện đáng kể về độ trễ (latency) và giảm chi phí networks trong trường hợp ae triển khai trên các server cloud.
Trường hợp anh em muốn tăng lưu lượng để đảm bảo xử lý được khối lượng công việc lớn thì anh em có thể tăng số partition và consume của Topic lên lưu ý là số Partition phải bằng số Consume nhé .
(Còn việc tăng partition và Topic lên bao nhiêu và giải thích thêm về lưu lượng từ bài trước mình sẽ đề cập tới trong các phần nâng cao ở phía sau, ae chờ nhé 😀😀😀😀)
7. Tiếp theo là Kafka Consumer Offsets
Trên mỗi máy cài Kafka (Broker) thì chúng có sử dụng cái gọi là topic consumer_offsets
ở bài trước ae cũng đã nghe qua cái Offset và hôm nay mình giải thích nó như sau: trong 1 Topic Kafka có các partition và những message có Offset ID đi kèm để biết comsume đã đọc tới vị trí nào thì consumer sẽ commit cái Offset Id đó vào consumer_offsets
ae cùng mình đi tìm hiểu tiếp về tầm quan trọng của consumer_offsets nhé:
Khi Kafka Client (application/service) của anh em đang consume vào partition của Topic ngon lành thì ko, một ngày đẹp trời thằng em trong team nó bảo "anh ơi, ới anh ơi " service của mình bị treo rồi hay sao ấy mà em tìm mãi không ra nguyên nhân hay mình restart lại nhé.
Phận ông anh đứng trên cũng băn khoăn cân đo đong đếm lắm mới cho thằng em nó dùng restart thần trưởng
- sau khi restart kafka client tiếp tục consume vào Topic và dựa vào offset id trong consumer_offsetst để khởi động lại quá trình đọc và xử lý message.
- cũng trong một trường hợp khác khi add thêm 1 consume vào 1 consume group thì các comsumer khác trong cùng group sẽ xảy ra trạng thái rebalance (cần bằng lại) và consume offset sẽ được thông báo tới các consume khác.
Mặc địnhh thì Consumer sẽ auto commit offsets (thuộc tính config enable.auto.commit=true ) và mỗi (auto.commit.interval.ms mặc định là 5 seconds) sau khi hàm .poll() được gọi .
Tùy từng bài toán mà ae có thể cấu hình enable.auto.commit= là true hoặc false cho hiệu quả:
có 3 hình thức commit offset như sau:
- Commit ngay sau khi nhận được message, với cách này thì trong TH mà đầu consume xử lý bị lỗi thì message đó coi như mất không thể đọc lại (At most once)
- Commit sau khi message đã được xử lý thành công nếu message xử lý bị lỗi sẽ được đọc lại do vậy có thể có thể dẫn đến việc bị duplicate message (At least once)
- kiểu này chỉ dành riêng cho việc từ Kafka Topic này sang Kafka Topic khác sử dụng transactions API. (Exactly once)
Khi triển khai thì các chuyên gia khuyến và cũng được nhiều sử dụng rộng rãi nhất là at least once.
8. Kế đến là Kafka producers acks setting
Kafka producer chỉ ghi data xuống duy nhất Leader Broker cho 1 partition và các producer cũng phải có một mức độ xác nhận nhất định acks để chỉ định message phải được ghi vào một số lượng tối thiểu các Replica thì message mới được coi là ghi nhận thành công.
Các thông số giá trị mặc định như sau:
- Kafka < V3.0, acks = 1
- Kafka >V3.0, acks=all
Các chế độ acks của Kafka Producer
- acks = 0 Producer chỉ gửi message thì nó coi đó là thành công và không quan tâm tới việc các Broker có nhận được message hoặc có chấp nhận message không.
Với TH này thì khi mà broker treo hoặc "mất mạng" hoặc có exception trong quá trình xử lý thì message sẽ bị mất nhưng đổi lại thì nó cóthroughputcao nhất. - acks = 1 Producer gửi message đi và nó coi là thành công khi mà nhận được sự xác nhận từ broker leader là đã xử lý message thành công nếu không nhận được phản hồi thành công thì producer sẽ retry lại request.
nhưng các broker replica không được đảm bảo là nó đã nhận được message đồng bộ (ISR) từ broker leader, và nếu ISR có vấn đề thì sẽ ghi nhận việc bị mất message . - acks = all Producer gửi message đi và đảm bảo rằng broker leader đã xử lý thành công message và quá trình đồng bộ (ISR) giữa các broker replica thành công.
Quá trình ISR giữa các broker replica và broker leader diễn ra như sau: Lead của các repica broker sẽ đi check thông số tối thiểu broker replica nhận message ae cấu hình bởimin.insync.replicasvà request sẽ được lưu trữ tạm tại vùng nhớ đệm và leader sẽ đảm bảo rằng các replica đã tạo được bản sao của message và sẽ phản hồi lại kết quả.
min.insync.replicastheo tài liệu thì anh em có thể cấu hình trên cả topic và kafka broker.
9. Cuối cùng là Kafka Topic Durability & Availability
2 khái niệm này bổ sung một cách chi tiết hơn cho High durable được Kafka quảng cáo , để giải thích thì mình sẽ lấy ví dụ như sau:
- Durability có thể hiểu là khi Kafka topic replicator factor = 3 thì ae có thể được phép có 2 brokers có thể bị mất mát dữ liệu. (nôm na chung lại là khi có N replicator thì Kafka cho phép N - 1 broker có thể bị mất dữ liệu và dữ liệu đó vẫn có khả năng khôi phục )
- Availablity
- chiều đọc : khi topic trên broker có 1 partition được tạo ra và đã được ISR với leader thì topic đó có thể sẵn sàng cho các consumers đọc message.
- chiều ghi với config acks = 0 và acks = 1 khi topic có 1 partition được tạo ra và ISR với topic leader thì nó sẵn sàng để producer có thể ghi message với ack = all thì tương tự như việc durability
replication.factor=Nvàmin.insync.replicas=Mvà khi có M broker phải được ISR với leader thì topic mới có thể ghi nhận message là thành công.
Tới đây thì anh chắc đã có kiến thức tổng quát và chi tiết (vừa phải) về Kafka và có thể tự mình cấu hình lên 1 cụm Kafka cho mình rồi.
Series này vẫn chưa hết, mời anh em tiếp tục đón đọc các bài viết tiếp theo của mình nhé.
Xin trân thành cảm ơn!
All rights reserved
