Kafka: Message Delivery Time
1. Mở đầu
Trong thiết kế kiến trúc, mình cực kì quan trọng các tham số ảnh hưởng đến "Message Delivery Time" của tất cả các công nghệ mà mình sử dụng như kafka, redis, hazelcast, oracle database,... Khi hiểu và sử dụng chuẩn sẽ rất dễ dàng trong việc tùy chỉnh để đáp ứng các bài toán khác nhau. Đây cũng là một trong các bước đầu tiên khi mà bắt tay vào việc tối ưu hoặc đánh giá công nghệ. Sau đây mình sẽ chia sẻ về các tham số có sự tác động trong kafka và một số case study thực tế mình đã tùy chỉnh để đem lại hiệu suất tốt hơn cho ứng dụng.
Trong Apache Kafka, thời gian gửi thông điệp là khoảng thời gian từ khi một producer gửi một thông điệp đến broker cho đến khi thông điệp đó được lưu trữ thành công. Để đạt được hiệu suất tối ưu, các tham số cấu hình liên quan đến thời gian gửi thông điệp cần được thiết lập đúng cách. Các tham số này kiểm soát thời gian mà producer chờ đợi phản hồi từ broker và thời gian mà broker cần để xử lý và lưu trữ thông điệp.
2. Một số các tham số quan trọng
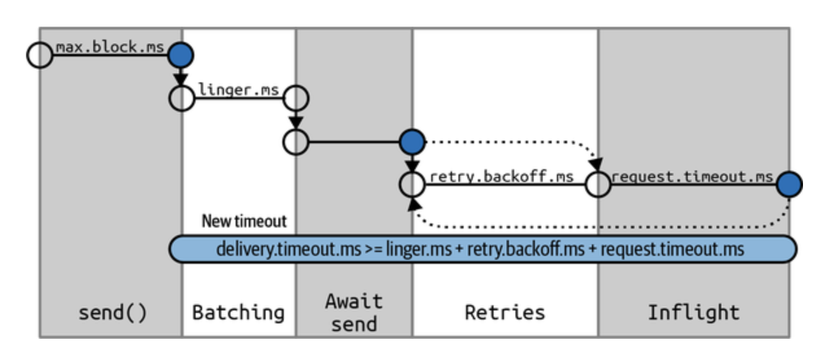
delivery.timeout.ms
Cấu hình này sẽ giới hạn thời gian từ lúc một bản ghi (record) sẵn sàng để gửi (khi send() trả về thành công và bản ghi được đặt vào trong một batch) cho đến khi broker phản hồi hoặc client từ bỏ, bao gồm cả thời gian dành cho các lần thử lại. Có thể thấy trong hình phía dưới, thời gian này nên lớn hơn linger.ms và request.timeout.ms. Nếu chúng ta cố gắng tạo một producer với cấu hình timeout không đồng nhất, bạn sẽ nhận được một exception. Các thông điệp (message) có thể được gửi thành công nhanh hơn nhiều so với delivery.timeout.ms, và thường thì sẽ như vậy. Nếu producer vượt quá delivery.timeout.ms trong khi đang thử gửi lại, callback sẽ được gọi với exception tương ứng với lỗi mà broker trả về trước khi thử lại. Nếu delivery.timeout.ms bị vượt quá trong khi batch bản ghi vẫn đang chờ gửi, callback sẽ được gọi với một TimeoutException.
max.block.ms
Cấu hình này kiểm soát thời gian tối đa mà producer có thể bị chặn (block) khi gọi send() và khi yêu cầu dữ liệu metadata thông qua partitionsFor(). Các phương thức này có thể bị chặn khi bộ đệm gửi của producer đầy hoặc khi metadata không có sẵn. Khi đạt đến giá trị của max.block.ms, một ngoại lệ timeout sẽ được ném ra.
linger.ms
Cấu hình này kiểm soát thời gian mà producer chờ đợi thêm các tin nhắn trước khi gửi batch hiện tại. KafkaProducer gửi một batch tin nhắn khi batch hiện tại đã đầy hoặc khi đạt đến giới hạn linger.ms. Mặc định, producer sẽ gửi tin nhắn ngay khi có một thread sẵn sàng để gửi chúng, ngay cả khi chỉ có một tin nhắn trong batch. Bằng cách thiết lập linger.ms lớn hơn 0, chúng ta yêu cầu producer chờ vài mili giây để thêm các thông điệp bổ sung vào batch trước khi gửi nó đến các broker. Điều này làm tăng độ trễ một chút và tăng đáng kể thông lượng—chi phí tính toán cho mỗi tin nhắn thấp hơn nhiều, và nếu bật nén, việc nén cũng sẽ hiệu quả hơn.
request.timeout.ms
Cấu hình này kiểm soát thời gian mà producer sẽ chờ đợi phản hồi từ server khi gửi dữ liệu. Lưu ý rằng đây là thời gian chờ đợi cho mỗi yêu cầu của producer trước khi từ bỏ; nó không bao gồm các lần thử lại, thời gian chờ trước khi gửi, và các yếu tố khác. Nếu thời gian chờ hết mà không nhận được phản hồi, producer sẽ hoặc thử gửi lại hoặc hoàn tất callback với một TimeoutException.
retry.backoff.ms
Khi producer nhận được thông báo lỗi từ server, lỗi đó có thể là tạm thời (ví dụ, thiếu leader cho một partition). Trong trường hợp này, giá trị của tham số retries sẽ kiểm soát số lần mà producer sẽ thử gửi lại tin nhắn trước khi từ bỏ và thông báo cho client về vấn đề. Mặc định, producer sẽ chờ 100 ms giữa các lần thử lại, nhưng chúng ta có thể điều chỉnh điều này bằng tham số retry.backoff.ms.
Mình không khuyến khích việc sử dụng các tham số này. Thay vào đó, hãy kiểm tra xem mất bao lâu để khôi phục từ một broker bị lỗi (tức là, bao lâu để tất cả các partition có leader mới), và thiết lập delivery.timeout.ms sao cho tổng thời gian dành cho việc thử lại sẽ lâu hơn thời gian cần thiết để cluster Kafka khôi phục từ lỗi—nếu không, producer sẽ từ bỏ quá sớm.
Không phải tất cả các lỗi đều được producer thử lại. Một số lỗi không phải là tạm thời và sẽ không gây ra việc thử lại (ví dụ, lỗi “thông điệp quá lớn”). Nói chung, vì producer xử lý việc thử lại cho chúng ta, nên không cần phải xử lý các lần thử lại trong logic ứng dụng của riêng bạn. Chúng ta nên tập trung vào việc xử lý các lỗi không thể thử lại hoặc các trường hợp mà các nỗ lực thử lại đã bị cạn kiệt.
3. Kết luận
Tùy chỉnh các tham số cấu hình này giúp tối ưu hóa thời gian gửi tin nhắn của Kafka. Điều quan trọng là phải cân bằng giữa độ trễ và hiệu suất gửi thông điệp để phù hợp với nhu cầu của ứng dụng. Việc theo dõi và điều chỉnh các tham số này theo yêu cầu thực tế của hệ thống có thể giúp giảm thiểu thời gian chờ đợi và nâng cao hiệu suất tổng thể.
Một số tình huống đã áp dụng trong thực tế của mình:
- Tùy chỉnh tham số acks trong việc mong muốn Kafka server phản hồi nhanh chóng. Cụ thể mình thường cấu hình acks=1
- Cấu hình
linger.ms, mục đích tối ưu về throughtput, mình có tănglinger.mstừ 10ms-100ms-Xms để đo đạc throughtput đến Kafka, đây là một cách để chúng ta kiểm chứng.
4. Thông tin kết nối
Nếu anh em muốn trao đổi thêm về bài viết, hãy kết nối với mình qua LinkedIn và Facebook:
- LinkedIn: https://www.linkedin.com/in/nguyentrungnam/
- Facebook: https://www.facebook.com/trungnam.nguyen.395/
Rất mong được kết nối và cùng thảo luận!
All rights reserved
