
Kafka là gì? Tại sao nó lại phổ biến đến vậy?
Bài đăng này đã không được cập nhật trong 2 năm

Kafka là gì?
Apache Kafka là một nền tảng xử lý dữ liệu phân tán được tối ưu hóa để thu nạp và xử lý dữ liệu truyền phát (streaming) theo thời gian thực (real-time). Ban đầu được phát triển bởi LinkedIn sau đó trở thành mã nguồn mở vào năm 2011 dưới sự quản lý của Apache Software Foundation. Dữ liệu truyền phát (streaming data) là dữ liệu được tạo ra liên tục từ hàng nghìn nguồn dữ liệu khác nhau, các nguồn dữ liệu này thường gửi các bản ghi liên tục đồng thời. Nền tảng truyền phát (streaming platform) cần phải xử lý được luồng dữ liệu liên tục này và xử lý chúng theo trình tự và tăng dần. Và Kafka được tạo ra để giải quyết vấn đề xử lý một lượng lớn dữ liệu với độ trễ thấp.
Kafka cung cấp 3 chức năng chính cho người dùng:
- Publish và subscribe các streams of records.
- Lưu trữ các streams of records theo thứ tự một cách hiệu quả
- Hỗ trợ xử lý streams of records theo thời gian thực (real-time)
Kafka chủ yếu được sử dụng để xây dựng các streaming data pipelines thời gian thực và các ứng dụng thích ứng với data streams. Kafka kết hợp messaging(truyền dữ liệu), storage (lưu trữ), và stream processing nhằm hỗ trợ hoạt động lưu trữ và phân tích dữ liệu lịch sử lẫn dữ liệu thời gian thực.
Ngày nay, Kafka đã phát triển và trở thành một trong những nền tảng xử lý dữ liệu phân tán phổ biến và được sử dụng rộng rãi nhất. Nó có khả năng xử lý hàng tỷ bản ghi mỗi ngày với đỗ trễ thấp. Các tổ chức lớn như Uber, Netflix, ... dựa vào Kafka để phân tích hoạt động của người dùng theo thời gian thực, phân tích dữ liệu về khách hàng.
Cấu trúc
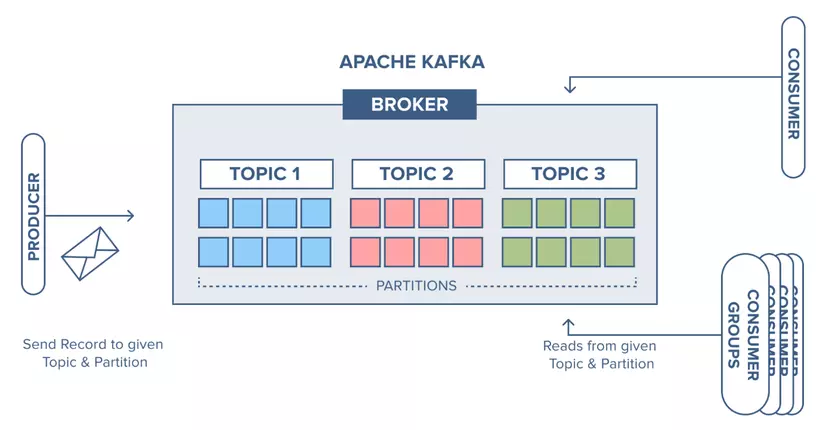
Về cơ bản Kafka có 4 thành phần chính như sau:
- Producer: Là thành phần gửi dữ liệu vào các topic của Kafka. Các producer có thể gửi dữ liệu vào đồng thời và bất đồng bộ, đảm bảo tằng dữ liệu được gửi vào hệ thống một cách nhanh chóng và hiệu quả
- Consumer: Là thành phần nhận dữ liệu từ các topic của Kafka. Các consumer có thể đăng ký vào các topic cụ thể và đọc dữ liệu theo thứ tự hoặc theo nhu cầu riêng.
- Broker: Là các máy chủ trong Kafka cluster chịu trách nhiệm lưu trữ và quản lý các bản ghi dữ liệu. Mỗi broker có thể quản lý một hoặc nhiều topic và phần dữ liệu (partition) liên quan. Các cụm broker làm việc cùng nhau để đảm bảo tính sẵn sàng và khả năng mở rộng của hệ thống.
- Zookeeper: Là một dịch vụ quản lý và điều phối các node Kafka, giúp duy trì thông tin cấu hình và trạng thái của Kafka cluster. Zookeeper đảm bảo rằng các broker có thể giao tiếp với nhau một cách hiệu quả và quản lý việc phân phối dữ liệu.
Ứng dụng
Messaging
Kafka là một sự lựa chọn hiệu quả để thay thế các message broker truyền thống. So với hầu hết các hệ thống messaging, Kafka có thông lượng tốt hơn, phân vùng, sao chép và có khả năng chịu lỗi tốt hơn vì có cách tính năng được tích hợp sẵn, điều này làm cho Kafka trở thành một giải pháp tối ưu cho các ứng dụng xử lý messaging quy mô lớn.
Website Activity Tracking
Kafka được dùng để theo dõi hoạt động của người dùng trên các website theo thời gian thực. Các hoạt động như lượt xem trang, tìm kiếm, và các hành động khác của người dùng(như click, ...) được đưa lên các topic và có thể được sử dụng cho các mục đích xử lý thời gian thực, giám sát, và tải vào các hệ thống lưu trữ dữ liệu như Hadoop để xử lý và báo cáo ngoại tuyến.
Metrics
Kafka thường được sử dụng cho các pipeline dữ liệu giám sát hoạt động. Nó giúp tổng hợp thống kê từ các ứng dụng phân tán để tạo ra các luồng dữ liệu hoạt động tập trung.
Log Aggregation
Kafka cũng là một giải pháp thay thế cho hệ thống tổng hợp log truyền thống. Nó cho phép thu thập các file log vật lý từ các server và đưa chúng vào một nơi tập trung để xử lý. Kafka cung cấp một cách trừu tượng hơn về dữ liệu log như stream of messages, giúp giảm độ trễ và hỗ trợ tốt hơn cho nhiều nguồn dữ liệu và tiêu thụ dữ liệu phân tán.
Stream Processing
Nhiều người dùng Kafka để xử lý dữ liệu theo giai đoạn, nơi dữ liệu được tiêu thụ từ các topic (dữ liệu thô) và sau đó được tổng hợp hoặc biến đổi thành các topic Kafka mới để tiếp tục xử lý. Điều này tạo ra một đồ thị luồng dữ liệu thời gian thực từ các topic riêng lẻ.
Event Sourcing
Kafka hỗ trợ thiết kế ứng dụng theo kiểu event sourcing, nơi các thay đổi trạng thái được ghi lại như một chuỗi các bản ghi có thứ tự thời gian. Kafka rất phù hợp để làm backend cho các ứng dụng xây dựng theo cách này nhờ vào khả năng lưu trữ log dữ liệu lớn.
Commit Log
Kafka có thể hoạt động như một loại commit-log bên ngoài cho một hệ thống phân tán. Log giúp sao chép dữ liệu giữa các node và hoạt động như một cơ chế đồng bộ lại cho các node bị lỗi để khôi phục dữ liệu của chúng. Tính năng nén log trong Kafka hỗ trợ mạnh mẽ cho các trường hợp này.
Kết bài
Apache Kafka là một công cụ mạnh mẽ và linh hoạt cho việc xử lý dòng dữ liệu theo thời gian thực. Với khả năng mở rộng, độ tin cậy cao và khả năng tích hợp linh hoạt, Kafka đã trở thành một phần quan trọng trong hệ sinh thái dữ liệu của nhiều doanh nghiệp. Hy vọng qua bài viết này các bạn có thể nắm được cái nhìn cơ bản về Kafka và áp dụng Kafka vào các ứng dụng thực tế để có thể mang lại nhiều lợi ích và giúp tối ưu hóa quy trình xử lý dữ liệu của ứng dụng.
All rights reserved
