Kafka là gì?
Bài đăng này đã không được cập nhật trong 7 năm

Apache Kafka® là một nền tảng stream dữ liệu phân tán.
Ngoài lề một chút, mình giải thích qua về một số keyword:
- stream data: dòng dữ liệu, hãy tưởng tượng dữ liệu là nước trong 1 con suối.
- Data Pipeline: dùng để thiết lập kênh liên lạc giữa 2 hệ thống hoặc dịch vụ.
Một stream platform sẽ có 3 khả năng chính:
- Publish và subscribe vào các stream của các bản ghi, tương tự như một hàng chờ tin nhắn.
- Các stream của các bản ghi được lưu trữ bằng phương pháp chịu lỗi cao cũng như khả năng chịu tải.
- Xử lý các stream của các bản ghi mỗi khi có bản ghi mới.
Kafka thường được sử dụng cho 2 mục đích chính sau:
- Xây dựng các pipeline stream dữ liệu theo thời gian thực để nhận dữ liệu giữa các hệ thống hoặc ứng dụng một cách đáng tin cậy.
- Xây dựng các ứng dụng stream theo thời gian thực để biến đổi hoặc ánh xạ đến các stream của dữ liệu.
Để khái quát được các tính năng của kafka, bạn có thể xem ảnh dưới.
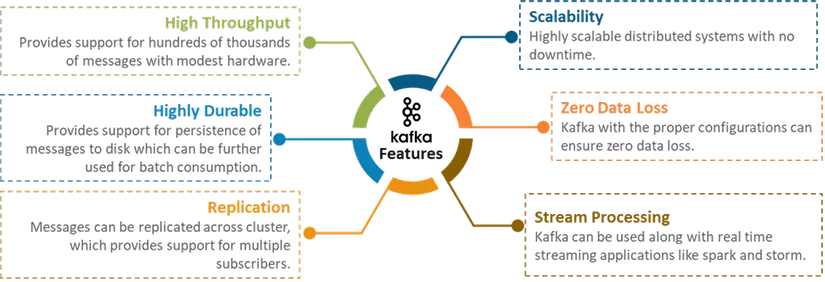
Tại sao Apache Kafka được sử dụng?
Kafka là dự án mã nguồn mở, đã được đóng gói hoàn chỉnh, khả năng chịu lỗi cao và là hệ thống nhắn tin nhanh. Vì tính đáng tin cậy của nó, kafka đang dần được thay thế cho hệ thống nhắn tin truyền thống. Nó được sử dụng cho các hệ thống nhắn tin thông thường trong các ngữ cảnh khác nhau. Đây là hệ quả khi khả năng mở rộng ngang và chuyển giao dữ liệu đáng tin cậy là những yêu cầu quan trọng nhất. Một vài use case cho kafka:
- Website Activity Monitoring: theo dõi hoạt động của website
- Stream Processing: xử lý stream
- Log Aggregation: tổng hợp log
- Metrics Collection: thu thập dữ liệu
Để rõ hơn về lợi ích của kafka, hãy tưởng tượng một hệ thống thương mại điện tử có nhiều máy chủ thực hiện các công việc khác nhau, tất cả các máy chủ này đều muốn giao tiếp với database server, vì vậy chúng ta sẽ có nhiều data pipeline kết nối các server khác đến database server này, hình ảnh minh họa như sau:
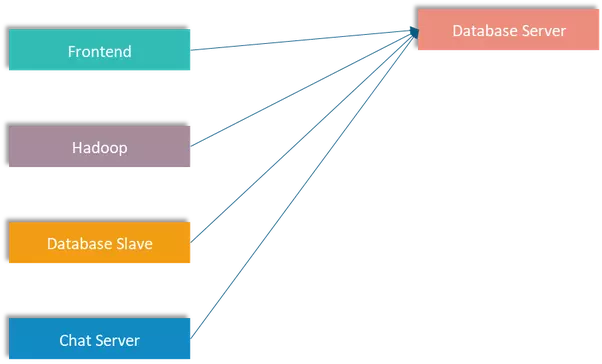
Nhưng trong thực tế, hệ thống thương mại điện tử sẽ còn phải kết nối đến một vài server khác nữa như là
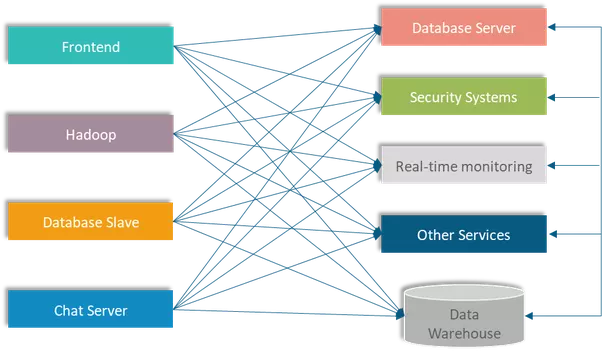
Như bạn thấy ở ảnh trên, data pipeline đang trở nên phức tạp theo sự gia tăng của số lượng hệ thống. Để giải quyết vấn đề này thì kafka ra đời. Kafka tách rời các data pipeline giữa các hệ thống để làm cho việc communicate giữa các hệ thống trở nên đơn giản hơn và dễ quản lý hơn.
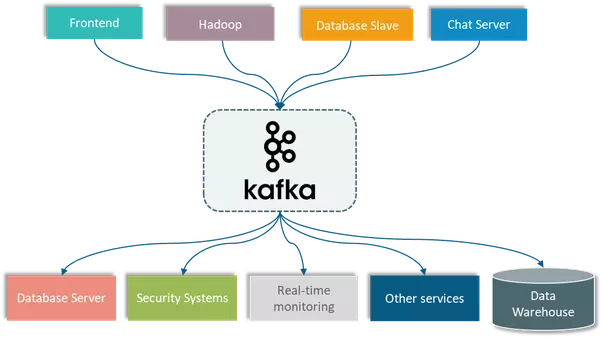
Cấu trúc của Apache Kafka
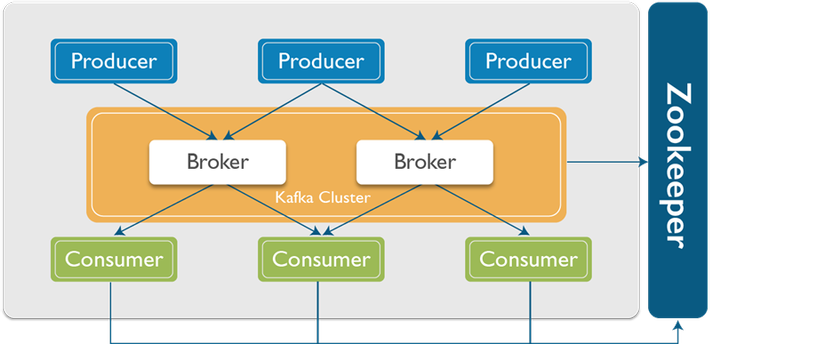 Một mô hình cấu trúc kafka đơn giản
Một mô hình cấu trúc kafka đơn giản
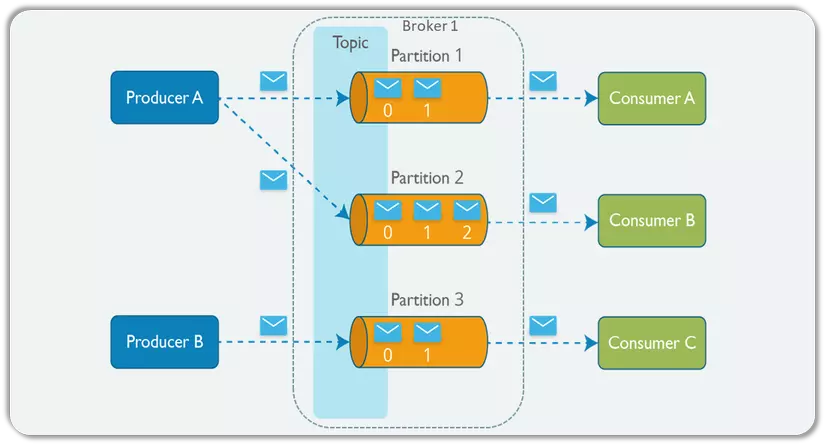 Một mô hình cấu trúc kafka chi tiết
Một mô hình cấu trúc kafka chi tiết
Như bạn thấy ở 2 ảnh trên, cấu trúc của kafka bao gồm các thành phần chính sau:
-
Producer: Một producer có thể là bất kì ứng dụng nào có chức năng publish message vào một topic.
-
Messages: Messages đơn thuần là byte array và developer có thể sử dụng chúng để lưu bất kì object với bất kì format nào - thông thường là String, JSON và Avro
-
Topic: Một topic là một category hoặc feed name nơi mà record được publish.
-
Partitions: Các topic được chia nhỏ vào các đoạn khác nhau, các đoạn này được gọi là partition
-
Consumer: Một consumer có thể là bất kì ứng dụng nào có chức năng subscribe vào một topic và tiêu thụ các tin nhắn.
-
Broker: Kafka cluster là một set các server, mỗi một set này được gọi là 1 broker
-
Zookeeper: được dùng để quản lý và bố trí các broker.
Kết
Bài viết này chỉ giới thiệu về kafka chứ không đào sâu vào cách hoạt động hoặc cách implement kafka. Để sử dụng kafka, bạn đọc có thể tải kafka ở đây và làm theo hướng dẫn.
All rights reserved
