Kafka là gì? Các thành phần chính có trong Kafka
Apache Kafka là một hệ thống nhắn tin theo mô hình publish-subscribe . Hệ thống nhắn tin cho phép bạn gửi tin nhắn giữa các tiến trình, ứng dụng và máy chủ. Nói một cách tổng quát, Apache Kafka là phần mềm nơi các chủ đề (một chủ đề có thể là một danh mục) có thể được định nghĩa và xử lý tiếp. Các ứng dụng có thể kết nối với hệ thống này và chuyển tin nhắn đến chủ đề. Một tin nhắn có thể bao gồm bất kỳ loại thông tin nào từ bất kỳ sự kiện nào trên blog của bạn hoặc có thể là một tin nhắn văn bản rất đơn giản có thể kích hoạt bất kỳ sự kiện nào khác.
Kafka là gì?
Kafka là một hệ thống nhắn tin mã nguồn mở được tạo ra bởi LinkedIn và sau đó được tặng cho Tổ chức Phần mềm Apache. Nó được xây dựng để xử lý lượng lớn dữ liệu trong thời gian thực, điều này khiến nó trở nên hoàn hảo để tạo ra các hệ thống phản hồi các sự kiện ngay khi chúng xảy ra. Kafka tổ chức dữ liệu thành các danh mục gọi là "chủ đề" (topics). Các nhà sản xuất (ứng dụng gửi dữ liệu) đưa thông điệp vào các chủ đề này, và người tiêu dùng (ứng dụng đọc dữ liệu) nhận chúng. Kafka đảm bảo hệ thống đáng tin cậy và có thể tiếp tục hoạt động ngay cả khi một số bộ phận bị lỗi.
Các thành phần cốt lõi của Apache Kafka
Để hiểu cách Kafka hoạt động, điều cần thiết là phải nắm rõ các thành phần cốt lõi của nó. Chúng ta hãy cùng xem xét kỹ hơn từng thành phần này:
1. Kafka Broker
Kafka broker là một máy chủ chạy Kafka và lưu trữ dữ liệu. Thông thường, một cụm Kafka bao gồm nhiều broker hoạt động cùng nhau để cung cấp khả năng mở rộng, khả năng chịu lỗi và tính sẵn sàng cao. Mỗi broker chịu trách nhiệm lưu trữ và cung cấp dữ liệu liên quan đến các chủ đề (topic).
2. Nhà sản xuất
Producer là một ứng dụng hoặc dịch vụ gửi tin nhắn đến một topic Kafka. Các tiến trình này đẩy dữ liệu vào hệ thống Kafka. Producer quyết định tin nhắn sẽ được gửi đến topic nào, và Kafka sẽ xử lý tin nhắn một cách hiệu quả dựa trên chiến lược phân vùng đã chọn.
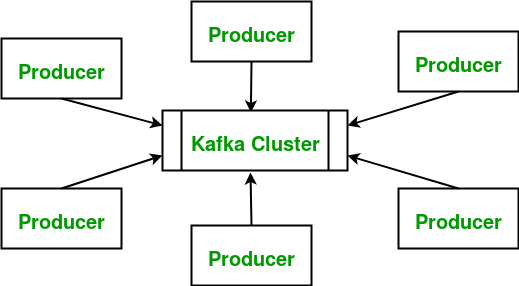
3. Chủ đề Kafka
Trong Kafka, topic là tên của một danh mục hoặc feed mà các tin nhắn được xuất bản đến. Tin nhắn Kafka luôn được liên kết với một topic, và khi bạn muốn gửi một tin nhắn, bạn sẽ gửi nó đến một topic cụ thể. Các topic được chia thành các partition, cho phép Kafka mở rộng theo chiều ngang và xử lý khối lượng dữ liệu lớn.
4. Người tiêu dùng và các nhóm người tiêu dùng
Consumer là một ứng dụng đọc tin nhắn từ các topic Kafka. Kafka cho phép các nhóm consumer, trong đó nhiều consumer có thể đọc từ cùng một topic, nhưng Kafka đảm bảo rằng mỗi tin nhắn chỉ được xử lý bởi một consumer trong nhóm. Điều này giúp cân bằng tải và cho phép các consumer đọc tin nhắn bắt đầu từ bất kỳ offset nào. Phân vùng cho phép bạn xử lý song song một chủ đề bằng cách chia dữ liệu trong một chủ đề cụ thể cho nhiều broker khác nhau.
Các khái niệm quan trọng của Apache Kafka
- Topic partition : Các chủ đề Kafka được chia thành nhiều phân vùng, cho phép bạn phân chia dữ liệu trên nhiều broker.
- Consumer Group : Một nhóm người tiêu dùng bao gồm tập hợp các quy trình người tiêu dùng đăng ký theo dõi một chủ đề cụ thể.
- Node : Một node là một máy tính đơn lẻ trong cụm Apache Kafka.
- Replicas: Bản sao của một phân vùng là "bản dự phòng" của phân vùng đó. Bản sao không bao giờ đọc hoặc ghi dữ liệu. Chúng được sử dụng để ngăn ngừa mất dữ liệu.
- Producer: Ứng dụng gửi các tin nhắn.
- Ứng dụng nhận tin nhắn (Consumer) : Ứng dụng nhận các tin nhắn đó.
Tại sao cần đến Apache Kafka?
- Với việc các doanh nghiệp thu thập khối lượng dữ liệu khổng lồ trong thời gian thực, cần có những công cụ có thể xử lý dữ liệu này một cách hiệu quả. Kafka giải quyết một số vấn đề then chốt:
- Real-Time Processing : Kafka được tối ưu hóa để xử lý các luồng dữ liệu thời gian thực, cho phép các doanh nghiệp xử lý và hành động dựa trên dữ liệu ngay khi nó được tạo ra.
- Fault-Tolerant: Kafka đảm bảo rằng ngay cả khi một phần của hệ thống gặp sự cố, dữ liệu sẽ không bị mất, biến nó thành một hệ thống nhắn tin có độ tin cậy cao.
- Scalable: Kafka có thể mở rộng theo chiều ngang bằng cách thêm nhiều broker, cho phép nó xử lý khối lượng dữ liệu ngày càng tăng và số lượng nhà sản xuất và người tiêu dùng ngày càng nhiều.
- Event-Driven Architecture: Kafka cung cấp sức mạnh cho kiến trúc hướng sự kiện , cho phép các hệ thống phản hồi các sự kiện trong thời gian thực mà không cần phải liên tục kiểm tra trạng thái thay đổi.
Cách thức hoạt động của Apache Kafka
Apache Kafka di chuyển dữ liệu từ nơi này sang nơi khác một cách mượt mà và đáng tin cậy. Dưới đây là cách hoạt động đơn giản của nó:
Bước 1: Nhà sản xuất gửi dữ liệu
- Producer là các ứng dụng tạo ra dữ liệu và gửi dữ liệu đó đến Kafka.
- Dữ liệu này có thể là bất cứ thứ gì — nhật ký, giao dịch, hoạt động của người dùng hoặc sự kiện.
- Kafka chia dữ liệu thành các phần nhỏ hơn gọi là phân vùng , giúp việc xử lý lượng thông tin lớn trở nên dễ dàng hơn.
Bước 2: Kafka lưu trữ dữ liệu
- Kafka tổ chức dữ liệu thành các chủ đề (topic) , nơi dữ liệu được lưu trữ trong một khoảng thời gian nhất định.
- Ngay cả khi người dùng đọc dữ liệu, Kafka cũng không xóa dữ liệu đó ngay lập tức .
- Để ngăn ngừa mất dữ liệu, Kafka tạo bản sao dữ liệu và lưu trữ chúng trên các máy chủ khác nhau.
Bước 3: Người tiêu dùng đọc dữ liệu
- Người tiêu dùng là các ứng dụng đăng ký theo dõi các chủ đề và đọc tin nhắn.
- Để quản lý tải, người dùng được chia thành các nhóm người dùng , do đó không có tin nhắn nào được xử lý hai lần.
- Người tiêu dùng có thể lựa chọn bắt đầu đọc từ đâu , có thể là từ tin nhắn mới nhất hoặc từ một điểm trước đó.
Bước 4: Kafka cân bằng tải
ZooKeeper giúp Kafka quản lý máy chủ nào chịu trách nhiệm lưu trữ và phân phối dữ liệu. Nếu một máy chủ gặp sự cố, Kafka sẽ tự động chuyển hướng dữ liệu sang máy chủ khác.
Bước 5: Dữ liệu được xử lý và sử dụng
- Sau khi người tiêu dùng nhận được dữ liệu, họ có thể lưu trữ dữ liệu đó trong cơ sở dữ liệu, phân tích hoặc kích hoạt các sự kiện khác .
- Kafka có thể hoạt động cùng với các công cụ như Apache Spark, Flink và Hadoop để phân tích chuyên sâu hơn.
Kafka tích hợp các mô hình xử lý dữ liệu khác nhau như thế nào?
Apache Kafka rất linh hoạt và có thể tích hợp liền mạch nhiều mô hình xử lý dữ liệu khác nhau, bao gồm truyền phát sự kiện , xếp hàng tin nhắn và xử lý theo lô .
1. Truyền phát sự kiện (Mô hình xuất bản-đăng ký)
Chức năng chính của Kafka là truyền phát sự kiện , trong đó:
- Các nhà sản xuất (ứng dụng gửi dữ liệu) xuất bản tin nhắn lên các chủ đề Kafka.
- Các ứng dụng đọc dữ liệu ( người dùng ) đăng ký theo dõi các chủ đề và nhận tin nhắn ngay khi chúng được gửi đến.
- Nhiều người dùng có thể đọc cùng một tin nhắn, cho phép phân phối dữ liệu theo thời gian thực.
2. Hàng đợi tin nhắn (Xử lý điểm-đến-điểm)
Kafka cũng có thể hoạt động như một hàng đợi tin nhắn bằng cách sử dụng các nhóm người tiêu dùng :
- Khi có nhiều người tiêu dùng trong cùng một nhóm, Kafka sẽ phân phối tin nhắn giữa họ , đảm bảo mỗi tin nhắn chỉ được xử lý một lần.
- Cấu hình này giúp cân bằng tải , đảm bảo không có người dùng nào bị quá tải.
3. Xử lý theo lô
Mặc dù Kafka được thiết kế cho dữ liệu thời gian thực, nó cũng có thể xử lý dữ liệu theo lô :
- Các thông điệp có thể được lưu trữ trong các chủ đề Kafka và được xử lý sau đó.
- Các công cụ như Apache Spark hoặc Hadoop có thể đọc dữ liệu từ Kafka theo lô và thực hiện phân tích.
4. Mô hình lai (Xử lý thời gian thực + Xử lý theo lô)
Kafka đủ linh hoạt để hỗ trợ cả xử lý thời gian thực và xử lý theo lô :
- Nó có thể gửi dữ liệu ngay lập tức để phân tích theo thời gian thực, đồng thời lưu trữ dữ liệu đó để xử lý theo lô sau này.
- Việc này thường được thực hiện bằng cách sử dụng Kafka Streams, Spark Streaming hoặc Flink .
Các trường hợp sử dụng phổ biến của Apache Kafka
Apache Kafka được sử dụng rộng rãi trong nhiều ngành công nghiệp khác nhau. Một số trường hợp sử dụng phổ biến bao gồm:
- Phân tích thời gian thực: Xử lý các luồng dữ liệu để phân tích trực tiếp, chẳng hạn như giám sát hoạt động của người dùng hoặc giá cổ phiếu.
- Ứng dụng hướng sự kiện: Kafka cung cấp sức mạnh cho các kiến trúc hướng sự kiện, đảm bảo rằng các hệ thống phản hồi theo thời gian thực đối với các sự kiện như hành động của người dùng, giao dịch hoặc dữ liệu cảm biến.
- Tổng hợp nhật ký : Thu thập nhật ký từ nhiều hệ thống vào một hệ thống ghi nhật ký tập trung để phân tích và giám sát tốt hơn.
- Xử lý luồng dữ liệu: Kafka, cùng với các công cụ như Apache Flink hoặc Apache Spark, được sử dụng để xử lý các luồng dữ liệu theo thời gian thực.
- Tích hợp dữ liệu: Kafka tích hợp dữ liệu giữa các hệ thống khác nhau, chẳng hạn như di chuyển dữ liệu giữa các microservice khác nhau hoặc đồng bộ hóa cơ sở dữ liệu.
Lợi ích của Apache Kafka
Dưới đây là một số lợi ích khi sử dụng Apache Kafka:
- Dễ dàng xử lý dữ liệu lớn. Kafka được thiết kế để xử lý khối lượng dữ liệu lớn, lý tưởng cho các doanh nghiệp có luồng dữ liệu khổng lồ.
- Đáng tin cậy và có khả năng chịu lỗi Ngay cả khi một số máy chủ gặp sự cố, Kafka vẫn giữ an toàn cho dữ liệu bằng cách tạo bản sao.
- Xử lý dữ liệu thời gian thực Hoàn hảo cho các ứng dụng cần cập nhật dữ liệu tức thời.
- Tích hợp hệ thống dễ dàng Nhà sản xuất và người tiêu dùng hoạt động độc lập, tạo nên sự linh hoạt.
- Hoạt động với mọi loại dữ liệu Có thể xử lý dữ liệu có cấu trúc, bán cấu trúc và không có cấu trúc.
- Sự hỗ trợ mạnh mẽ từ cộng đồng Với việc nhiều công ty sử dụng Kafka, cộng đồng hỗ trợ nó rất lớn và năng động, cùng với sự tích hợp với các công cụ như Apache Spark và Flink.
Những hạn chế của Apache Kafka
Dưới đây là một số hạn chế bạn phải đối mặt khi sử dụng Apache Kafka:
- Khó cài đặt Cần có kiến thức kỹ thuật để cài đặt và quản lý.
- Chi phí lưu trữ có thể cao. Vì nó lưu trữ tin nhắn trong một thời gian nhất định, chi phí có thể tăng lên.
- Các vấn đề về thứ tự tin nhắn Chức năng này chỉ đảm bảo thứ tự trong phạm vi một phân vùng duy nhất, chứ không phải trên nhiều phân vùng khác nhau.
- Không có bộ xử lý tích hợp Cần thêm các công cụ để chuyển đổi hoặc phân tích dữ liệu.
- Cần nguồn lực cao Tiêu tốn nhiều CPU, bộ nhớ và băng thông mạng.
- Không lý tưởng cho các tin nhắn ngắn Phù hợp hơn cho các luồng dữ liệu lớn; các tác vụ nhỏ hơn có thể phát sinh chi phí không cần thiết.
All rights reserved
