Kafka dưới góc nhìn System Design: Khi dữ liệu là một dòng thời gian
Vấn đề gốc của system design: bạn đang lưu state hay đang lưu sự thật?
Trong hầu hết hệ thống backend, dữ liệu được thiết kế xoay quanh state hiện tại. Một bản ghi user chứa email mới nhất, một order có trạng thái cuối cùng, một product có tồn kho hiện tại. Cách tiếp cận này phù hợp với CRUD, nhưng lại có một hạn chế lớn: nó không trả lời được câu hỏi “điều gì đã xảy ra trước đó”.
Khi hệ thống bắt đầu phức tạp, đây lại là câu hỏi quan trọng nhất. Một đơn hàng bị huỷ không chỉ là một trạng thái, mà là kết quả của một chuỗi sự kiện. Nếu chỉ lưu trạng thái cuối cùng, toàn bộ ngữ cảnh phía sau sẽ biến mất. Việc debug, audit hay phân tích hành vi trở nên khó khăn vì hệ thống không còn giữ lại lịch sử.
Kafka xuất hiện để giải quyết đúng điểm này. Nó không cố gắng tối ưu việc lưu state, mà thay đổi cách nhìn: dữ liệu cần được lưu như một chuỗi sự kiện theo thời gian.
Kafka = append-only log, không phải message queue
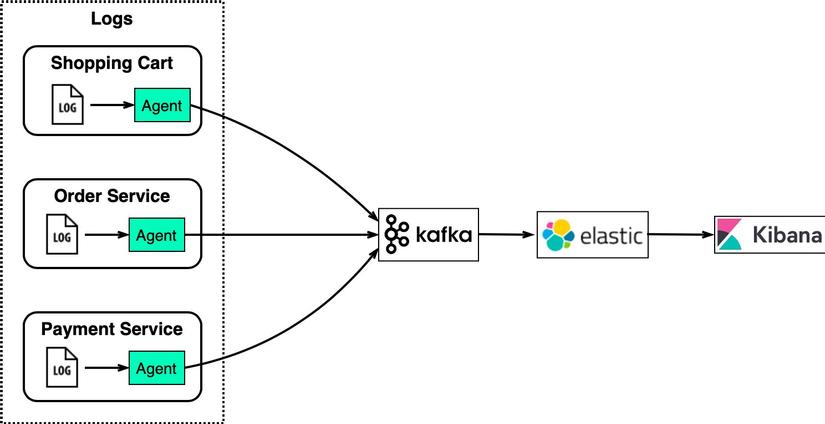 Điểm dễ gây hiểu nhầm nhất là Kafka thường bị so sánh với message queue. Thực tế, cách vận hành của Kafka khác hẳn.
Điểm dễ gây hiểu nhầm nhất là Kafka thường bị so sánh với message queue. Thực tế, cách vận hành của Kafka khác hẳn.
Kafka không “xử lý message rồi xoá đi”, mà giữ lại tất cả dữ liệu dưới dạng một log bất biến. Mỗi event được ghi thêm vào cuối log và không bị thay đổi.
[0] OrderCreated
[1] PaymentSuccess
[2] OrderShipped
[3] OrderCancelled
Cách lưu này khiến Kafka giống với:
- Write-ahead log trong database
- Commit history trong Git
- Hoặc một event journal
Điểm quan trọng là: Kafka không quan tâm message đã được xử lý hay chưa, nó chỉ quan tâm việc ghi nhận sự kiện một cách tuần tự. Việc xử lý là trách nhiệm của consumer, không phải broker.
Chính điều này tạo ra sự khác biệt lớn trong cách thiết kế hệ thống.
Từ CRUD sang event stream: thay đổi tư duy dữ liệu
Trong mô hình CRUD, khi có thay đổi, ta update trực tiếp vào database. Giá trị cũ bị ghi đè, và hệ thống chỉ giữ lại phiên bản mới nhất.
Trong Kafka, thay vì update, ta ghi một event mới. Ví dụ, thay vì sửa trạng thái đơn hàng, hệ thống ghi thêm một sự kiện mới:
OrderCreated
PaymentSuccess
OrderCancelled
State hiện tại không còn là dữ liệu gốc, mà là kết quả được tính toán lại từ chuỗi event.
state = reduce(events)
Cách tiếp cận này mở ra một khả năng quan trọng: có thể dựng lại trạng thái tại bất kỳ thời điểm nào. Điều này đặc biệt hữu ích khi cần debug hoặc replay logic sau khi thay đổi code.
Offset trong Kafka: vị trí trong timeline, không phải ID
Một chi tiết nhỏ nhưng có ý nghĩa lớn trong system design là cách Kafka định danh dữ liệu. Thay vì dùng ID độc lập cho từng message, Kafka dùng offset tức là vị trí của event trong log.
Điều này có nghĩa là consumer không đọc “message A” hay “message B”, mà đọc dữ liệu từ một điểm trong timeline.
read from offset = 100
Cách đọc này giúp hệ thống:
- Có thể replay dữ liệu từ bất kỳ điểm nào
- Không phụ thuộc vào trạng thái trước đó của consumer
- Dễ dàng scale nhiều consumer đọc cùng một nguồn dữ liệu
Nói cách khác, Kafka không ép bạn xử lý dữ liệu theo một lần duy nhất. Nó cho phép bạn đọc lại lịch sử bất cứ khi nào cần.
Partition: đánh đổi giữa ordering và scalability
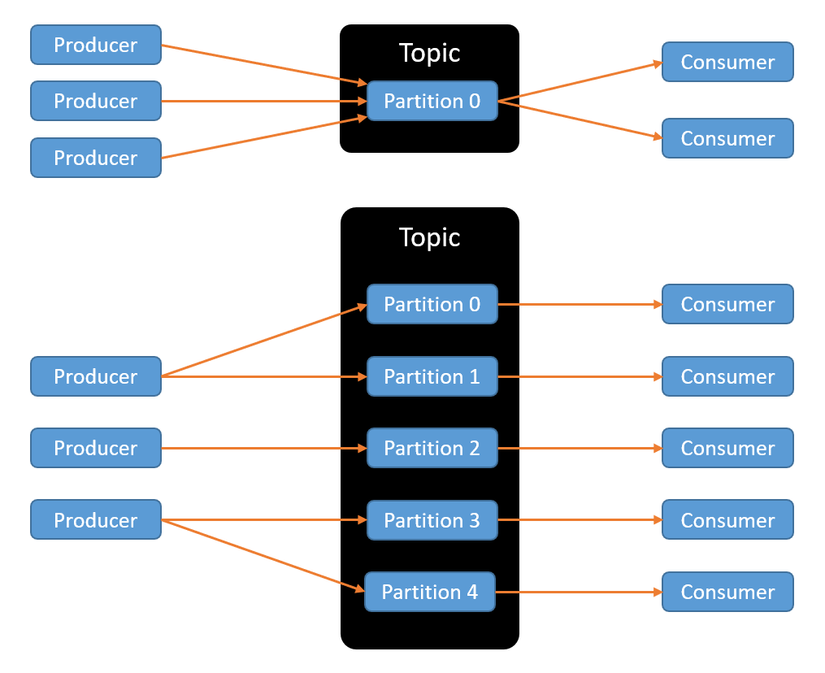 Kafka scale bằng cách chia log thành nhiều partition. Mỗi partition là một chuỗi sự kiện độc lập, có thứ tự riêng.
Kafka scale bằng cách chia log thành nhiều partition. Mỗi partition là một chuỗi sự kiện độc lập, có thứ tự riêng.
Partition 0 → A, C, E
Partition 1 → B, D, F
Điều này mang lại khả năng xử lý song song rất lớn, nhưng đi kèm một trade-off quan trọng: Kafka chỉ đảm bảo thứ tự trong từng partition, không đảm bảo thứ tự toàn cục.
Vì vậy, khi thiết kế hệ thống, developer phải quyết định:
- Cần ordering toàn bộ → khó scale
- Hay chấp nhận ordering theo từng key → scale tốt hơn
Đây không phải là hạn chế của Kafka, mà là một quyết định thiết kế có chủ đích để đạt được throughput cao.
Kafka thay đổi vai trò của database trong kiến trúc
Trong kiến trúc truyền thống, database là trung tâm. Các service tương tác với nhau thông qua việc đọc và ghi vào cùng một database.
Kafka làm điều ngược lại. Nó đưa event stream lên làm trung tâm, còn database trở thành nơi lưu state đã được xử lý.
Luồng dữ liệu khi đó sẽ như sau:
Service A → publish event → Kafka → Service B/C/D consume → update DB riêng
Cách tiếp cận này giúp:
- Giảm coupling giữa các service
- Cho phép mỗi service có database riêng
- Dễ mở rộng thêm consumer mới mà không ảnh hưởng hệ thống cũ
Đây chính là nền tảng của event-driven architecture.
Kafka thực sự mạnh khi hệ thống cần “ghi nhớ”
 Không phải hệ thống nào cũng cần Kafka. Nhưng khi hệ thống bắt đầu có nhu cầu:
Không phải hệ thống nào cũng cần Kafka. Nhưng khi hệ thống bắt đầu có nhu cầu:
- Phân tích hành vi user theo thời gian
- Xử lý dữ liệu realtime
- Đồng bộ dữ liệu giữa nhiều service
- Hoặc audit toàn bộ hoạt động
thì việc chỉ lưu state là không đủ.
Kafka giải quyết vấn đề này bằng cách giữ lại toàn bộ dòng sự kiện. Khi đó, hệ thống không chỉ “biết”, mà còn “nhớ”.
Khả năng “nhớ” này cho phép developer:
- Replay dữ liệu khi logic thay đổi
- Debug bằng lịch sử thật thay vì giả lập
- Xây thêm service mới mà không cần thay đổi producer
Kết luận
Kafka thường được nhắc đến với throughput cao và khả năng scale. Nhưng đó không phải lý do cốt lõi khiến nó trở nên quan trọng trong system design.
Giá trị lớn nhất của Kafka là nó cho phép hệ thống chuyển từ việc lưu trạng thái sang việc lưu lịch sử. Khi dữ liệu được lưu như một dòng thời gian, hệ thống trở nên linh hoạt hơn, dễ mở rộng hơn và có khả năng xử lý lại quá khứ điều mà các mô hình truyền thống làm rất kém.
Vì vậy, nếu nhìn Kafka chỉ như một message broker mạnh hơn bình thường, ta đang bỏ lỡ phần quan trọng nhất. Kafka không phải là công cụ để tối ưu việc truyền dữ liệu, mà là nền tảng để tổ chức dữ liệu theo đúng bản chất của nó: một chuỗi sự kiện diễn ra theo thời gian.
All rights reserved
