Kafka Connect là gì? Kiến trúc tích hợp dữ liệu theo thời gian thực trong hệ sinh thái Kafka
Trong các hệ thống dữ liệu hiện đại, bài toán không còn nằm ở việc “có thu thập được dữ liệu hay không”, mà là làm thế nào để đưa dữ liệu đi đúng nơi, đúng thời điểm, với độ tin cậy cao và chi phí vận hành hợp lý. Khi số lượng database, ứng dụng SaaS, data warehouse, object storage hay hệ thống analytics ngày càng tăng, việc tự viết từng pipeline tích hợp riêng lẻ nhanh chóng trở thành gánh nặng cho đội ngũ kỹ thuật.
Đó là lý do Kafka Connect xuất hiện như một lớp tích hợp chuyên biệt trong hệ sinh thái Apache Kafka. Thay vì buộc doanh nghiệp phải xây dựng hàng loạt đoạn code để kéo dữ liệu từ MySQL, PostgreSQL, MongoDB, Elasticsearch, S3 hay các hệ thống khác, Kafka Connect chuẩn hóa việc kết nối thông qua mô hình connector. Nói cách khác, đây là cơ chế giúp Kafka không chỉ là một message broker hay nền tảng streaming, mà trở thành trục trung chuyển dữ liệu của toàn bộ hệ thống.
Kafka Connect thực chất là gì trong kiến trúc dữ liệu hiện đại?
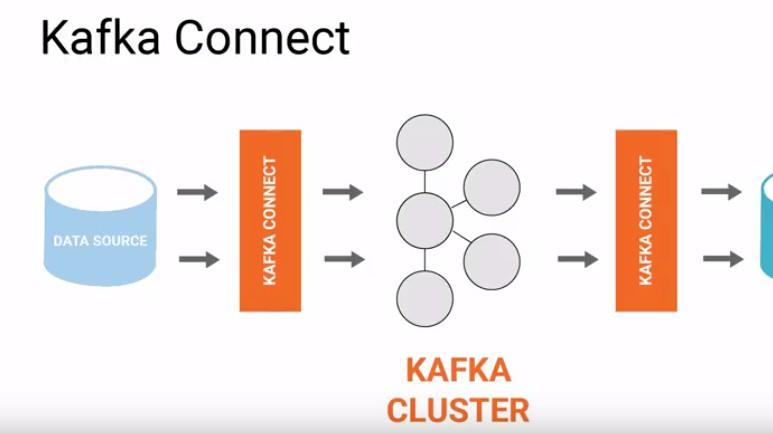 Nếu nhìn ở mức kỹ thuật, Kafka Connect là một framework chạy độc lập, được thiết kế để xử lý luồng tích hợp dữ liệu giữa Kafka và các hệ thống bên ngoài. Nó hoạt động như một lớp trung gian chuyên trách ingestion và delivery dữ liệu, giúp đẩy dữ liệu vào Kafka hoặc lấy dữ liệu từ Kafka ra các hệ thống đích mà không cần phát triển custom application từ đầu.
Nếu nhìn ở mức kỹ thuật, Kafka Connect là một framework chạy độc lập, được thiết kế để xử lý luồng tích hợp dữ liệu giữa Kafka và các hệ thống bên ngoài. Nó hoạt động như một lớp trung gian chuyên trách ingestion và delivery dữ liệu, giúp đẩy dữ liệu vào Kafka hoặc lấy dữ liệu từ Kafka ra các hệ thống đích mà không cần phát triển custom application từ đầu.
Điểm quan trọng là Kafka Connect không đơn thuần là một “bộ công cụ import/export dữ liệu”. Nó được thiết kế với tư duy của một nền tảng vận hành lâu dài: có khả năng scale ngang, quản lý trạng thái, theo dõi tiến trình, phục hồi sau lỗi và phân phối tải giữa nhiều tiến trình xử lý. Vì vậy, trong nhiều kiến trúc event-driven hoặc data platform, Kafka Connect thường được xem là lớp tích hợp chuẩn hóa giữa Kafka và hệ sinh thái dữ liệu xung quanh.
Ở góc độ thực tiễn, điều này giúp doanh nghiệp giảm đáng kể thời gian phát triển integration pipeline. Thay vì để từng team tự viết service đồng bộ dữ liệu riêng, Kafka Connect cung cấp một cơ chế thống nhất để vận hành hàng chục, thậm chí hàng trăm pipeline với cách quản trị tập trung hơn.
Vị trí của Kafka Connect trong toàn bộ hệ sinh thái Kafka
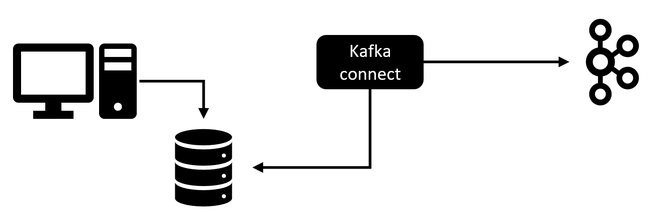
Trong kiến trúc Kafka, broker chịu trách nhiệm lưu trữ và phân phối dữ liệu theo topic, producer gửi dữ liệu vào broker, consumer đọc dữ liệu ra khỏi broker. Kafka Connect nằm ở ranh giới giữa Kafka và các hệ thống ngoài Kafka.
Nếu producer/consumer truyền thống thường do developer tự viết bằng Java, Python, Go hoặc Node.js, thì Kafka Connect thay thế nhu cầu đó trong các tình huống tích hợp chuẩn. Ví dụ, khi cần lấy dữ liệu thay đổi từ database rồi đẩy vào Kafka, doanh nghiệp không nhất thiết phải phát triển một ứng dụng CDC riêng. Tương tự, khi cần đẩy log hoặc event từ Kafka sang Elasticsearch, data lake hoặc object storage, Kafka Connect có thể đảm nhiệm công việc này bằng connector phù hợp.
Chính vì vậy, Kafka Connect giúp chuẩn hóa phần “data movement” trong hệ thống. Nó tách bài toán tích hợp dữ liệu ra khỏi logic nghiệp vụ, giúp đội ngũ phát triển tập trung hơn vào xử lý business logic, stream processing hay xây dựng ứng dụng downstream.
Cơ chế hoạt động của Kafka Connect nhìn từ bên trong hệ thống
Để hiểu rõ giá trị của Kafka Connect, cần nhìn sâu hơn vào cách nó vận hành thay vì chỉ dừng ở khái niệm source connector và sink connector.
Khi một connector được khai báo, Kafka Connect sẽ tạo ra các task tương ứng để xử lý dữ liệu song song. Mỗi task là một đơn vị thực thi, có nhiệm vụ đọc dữ liệu từ nguồn hoặc ghi dữ liệu ra đích. Các task này được phân phối cho các worker trong cluster Connect.
Với source connector, dữ liệu được đọc từ hệ thống nguồn, sau đó chuyển đổi thành record Kafka Connect, rồi serialize thành định dạng mà Kafka broker hiểu được trước khi ghi vào topic. Với sink connector, tiến trình diễn ra theo hướng ngược lại: task đọc record từ Kafka topic, deserialize, xử lý mapping trường dữ liệu nếu cần, rồi ghi vào hệ thống đích.
Điểm đáng chú ý là Kafka Connect không chỉ di chuyển dữ liệu. Nó còn quản lý trạng thái xử lý thông qua offset. Offset ở đây không chỉ mang ý nghĩa vị trí đọc trong Kafka như consumer thông thường, mà còn là trạng thái cần thiết để connector biết mình đã đọc đến đâu ở hệ thống nguồn hoặc đã xử lý đến bản ghi nào. Cơ chế này cực kỳ quan trọng để đảm bảo pipeline có thể tiếp tục hoạt động chính xác sau khi worker bị restart hoặc cluster gặp sự cố.
Các thành phần kỹ thuật quan trọng của Kafka Connect
Connect Worker
Worker là tiến trình Java chạy Kafka Connect runtime. Đây là nơi connector và task được khởi tạo, giám sát và thực thi. Trong môi trường production, worker thường được triển khai thành nhiều node để tăng khả năng chịu lỗi và scale tải.
Worker chịu trách nhiệm giao tiếp với Kafka cluster, lưu metadata nội bộ, phân công task, theo dõi health của connector và xử lý rebalance khi có node mới tham gia hoặc rời cluster. Có thể hiểu worker là “runtime engine” của Kafka Connect.
Connector
Connector là định nghĩa logic tích hợp với một hệ thống cụ thể. Bản thân connector không trực tiếp xử lý toàn bộ dữ liệu, mà đóng vai trò như một template hoặc adapter, mô tả cách kết nối với hệ thống nguồn hoặc hệ thống đích.
Một connector có thể được cấu hình thành nhiều task song song để tăng throughput. Ví dụ, một JDBC Source Connector có thể chia workload theo bảng hoặc theo truy vấn incremental. Một Elasticsearch Sink Connector có thể chạy nhiều task để ghi song song vào cluster Elasticsearch.
Task
Task mới là nơi dữ liệu thực sự được đọc hoặc ghi. Trong thực tế vận hành, hiệu năng của Kafka Connect phụ thuộc nhiều vào cách số lượng task được cấu hình, khả năng phân vùng của topic, đặc điểm của hệ thống nguồn/đích và mức độ song song mà connector hỗ trợ.
Nếu connector là “loại pipeline”, thì task là “công nhân” trực tiếp vận chuyển dữ liệu.
Internal Topics
Ở distributed mode, Kafka Connect dùng chính Kafka để lưu trạng thái nội bộ, bao gồm cấu hình connector, trạng thái cluster và offset. Những internal topic này cho phép toàn bộ cluster worker cùng nhìn thấy một trạng thái nhất quán.
Đây là một đặc điểm kiến trúc rất đáng chú ý: Kafka Connect sử dụng Kafka như một lớp lưu trữ metadata phân tán cho chính nó. Nhờ đó, cluster có thể tự phục hồi tốt hơn và hỗ trợ mở rộng ngang hiệu quả hơn.
Converter và Transformation
Dữ liệu khi đi qua Kafka Connect thường phải được serialize hoặc deserialize thông qua converter, ví dụ JSON Converter, Avro Converter hoặc Protobuf Converter. Ngoài ra, Connect còn hỗ trợ SMT (Single Message Transform) để chỉnh sửa record ngay trong pipeline, chẳng hạn đổi tên field, thêm metadata, lọc bản ghi hoặc chuyển đổi cấu trúc dữ liệu nhẹ.
Đây là phần thường bị bỏ qua trong các bài giới thiệu cơ bản, nhưng trên thực tế lại rất quan trọng, vì nó quyết định mức độ chuẩn hóa dữ liệu trước khi record đi vào Kafka hoặc ra khỏi Kafka.
Standalone và Distributed Mode khác nhau ở đâu?
Kafka Connect hỗ trợ hai chế độ triển khai, nhưng khác biệt của chúng không chỉ là “một cái đơn giản, một cái phức tạp hơn”.
Standalone Mode
Standalone phù hợp cho môi trường phát triển, test hoặc các pipeline nhỏ. Toàn bộ connector và task chạy trên một tiến trình duy nhất. Cách triển khai này nhẹ, dễ cấu hình, dễ debug nhưng gần như không có khả năng chịu lỗi ở cấp cluster. Nếu tiến trình dừng, pipeline dừng theo.
Mô hình này phù hợp khi cần proof of concept, đồng bộ dữ liệu quy mô nhỏ hoặc chạy các job đơn giản trong môi trường non-production.
Distributed Mode
Distributed mode là lựa chọn dành cho production. Nhiều worker cùng tham gia vào một cluster Connect, chia sẻ cấu hình và trạng thái thông qua Kafka internal topics. Khi một worker gặp sự cố, task có thể được phân phối lại sang worker khác.
Đây là cơ chế cho phép Kafka Connect đạt được khả năng mở rộng và độ sẵn sàng cao. Trong các hệ thống streaming nghiêm túc, distributed mode gần như là lựa chọn mặc định vì nó giúp pipeline ổn định hơn rất nhiều khi khối lượng dữ liệu tăng hoặc khi hạ tầng có biến động.
Tại sao Kafka Connect giúp giảm độ phức tạp tích hợp dữ liệu?
Trong các hệ thống truyền thống, mỗi lần muốn đồng bộ dữ liệu giữa hai nền tảng, đội ngũ kỹ thuật thường phải viết service riêng: tự quản lý connection pool, retry, batching, checkpoint, logging, monitoring, backpressure và xử lý lỗi. Mỗi pipeline là một ứng dụng mini cần bảo trì.
Kafka Connect thay đổi mô hình này bằng cách đưa toàn bộ những vấn đề hạ tầng nói trên vào một runtime thống nhất. Điều này tạo ra ba lợi ích kỹ thuật rõ rệt.
Thứ nhất là giảm custom code. Khi sử dụng connector chuẩn, doanh nghiệp không phải viết lại những logic integration lặp đi lặp lại.
Thứ hai là tăng tính vận hành tập trung. Thay vì quản lý nhiều ứng dụng đồng bộ dữ liệu khác nhau, toàn bộ connector được đưa về một nền tảng chung với REST API, logging và cơ chế scale thống nhất.
Thứ ba là tăng tính chuẩn hóa cho data platform. Khi dữ liệu đi qua cùng một lớp tích hợp, việc kiểm soát schema, transform, retry và monitoring sẽ đồng bộ hơn, từ đó giảm rủi ro pipeline hoạt động lệch chuẩn giữa các team.
Quy trình triển khai Kafka Connect trong môi trường thực tế
Bước 1: Xác định bài toán tích hợp
Trước khi cài đặt, cần làm rõ pipeline thuộc loại nào: source hay sink, batch hay near real-time, dữ liệu dạng row-based, event-based hay file-based. Đây là bước quyết định connector nào phù hợp và có cần custom connector hay không.
Ví dụ, nếu mục tiêu là đẩy thay đổi dữ liệu từ MySQL vào Kafka, phương án phù hợp có thể là JDBC Source hoặc Debezium CDC tùy yêu cầu. Nếu mục tiêu là đẩy dữ liệu từ Kafka vào S3 để xây data lake, một sink connector chuyên biệt sẽ phù hợp hơn.
Bước 2: Chuẩn bị Kafka cluster và Connect runtime
Kafka Connect không hoạt động độc lập khỏi Kafka. Nó cần một Kafka cluster ổn định để lưu dữ liệu streaming và cả metadata nội bộ. Ở bước này, cần chuẩn bị broker, network, authentication, internal topics và đảm bảo worker có thể truy cập tới hệ thống nguồn/đích.
Trong môi trường doanh nghiệp, đây cũng là lúc cần cân nhắc TLS, SASL, ACL và chính sách tách network giữa data plane với control plane.
Bước 3: Cài connector plugin
Connector không phải lúc nào cũng đi kèm sẵn trong Kafka distribution. Rất nhiều connector cần được cài dưới dạng plugin riêng. Việc quản lý plugin path, version tương thích và dependency là khâu dễ phát sinh lỗi nếu không chuẩn hóa ngay từ đầu.
Trong môi trường container hoặc Kubernetes, plugin thường được đóng gói thành image riêng để đảm bảo các worker có cùng phiên bản connector.
Bước 4: Thiết kế cấu hình connector
Đây là phần tác động trực tiếp tới độ ổn định của pipeline. Không chỉ là endpoint, username hay password, cấu hình còn liên quan đến chế độ đọc incremental, batching, poll interval, task parallelism, error handling, dead letter queue, converter, transform và commit strategy.
Một connector cấu hình đúng không chỉ chạy được, mà còn phải vận hành ổn định dưới tải, có khả năng retry hợp lý và không gây áp lực quá lớn lên hệ thống nguồn.
Bước 5: Kiểm thử dưới tải thực tế
Rất nhiều pipeline chạy tốt ở môi trường test nhưng gặp sự cố khi dữ liệu tăng đột biến. Vì vậy, trước khi đưa vào production, nên kiểm thử với dữ liệu gần sát thực tế để đánh giá throughput, latency, memory usage, tốc độ commit offset và hành vi khi có lỗi mạng hoặc restart worker.
Bước 6: Giám sát và tối ưu vận hành
Sau khi triển khai, cần theo dõi liên tục tình trạng task, worker, lag, throughput, số lần retry, lỗi serialization và khả năng reconnect tới hệ thống nguồn/đích. Với các pipeline quan trọng, monitoring không phải phần bổ sung mà là yêu cầu bắt buộc.
Ví dụ kỹ thuật: đưa dữ liệu từ MySQL vào Kafka rồi đồng bộ sang data lake
Một kịch bản rất điển hình là doanh nghiệp có hệ thống giao dịch chạy trên MySQL và muốn đưa dữ liệu sang Kafka để phục vụ analytics, downstream processing hoặc lưu vào data lake.
Ở hướng triển khai cơ bản, source connector sẽ đọc dữ liệu từ MySQL, chuyển đổi thành record Kafka và đẩy vào topic tương ứng. Từ topic này, các consumer khác có thể xử lý stream, còn sink connector có thể ghi record ra HDFS, S3 hoặc warehouse.
Nếu thiết kế tốt, Kafka lúc này trở thành lớp đệm trung gian giữa hệ thống giao dịch và hệ thống phân tích. Điều này giúp tách rời workload online và workload analytics, tránh việc mỗi hệ thống downstream phải truy cập trực tiếp vào database nguồn.
Từ góc độ kiến trúc, đây là giá trị lớn nhất của Kafka Connect: không chỉ đồng bộ dữ liệu, mà còn giúp kiến trúc dữ liệu trở nên decoupled hơn.
Khi nào nên dùng Kafka Connect, khi nào nên viết custom consumer/producer?
Kafka Connect rất mạnh, nhưng không phải bài toán nào cũng phù hợp.
Kafka Connect phù hợp khi nhu cầu chính là tích hợp dữ liệu chuẩn hóa giữa Kafka và hệ thống ngoài, ít logic nghiệp vụ phức tạp, cần vận hành lâu dài và muốn tận dụng connector sẵn có. Nó đặc biệt hiệu quả khi doanh nghiệp có nhiều pipeline tương tự nhau và muốn chuẩn hóa cách quản trị.
Ngược lại, nếu pipeline cần xử lý nghiệp vụ sâu, join nhiều nguồn dữ liệu, áp dụng rule động phức tạp, gọi API theo logic tùy biến hoặc yêu cầu luồng xử lý mang tính ứng dụng nhiều hơn tích hợp, việc viết custom producer/consumer hoặc stream application thường phù hợp hơn.
Nói cách khác, Kafka Connect tối ưu cho integration pipeline, không phải là công cụ thay thế toàn bộ application logic.
Tham khảo dịch vụ Kafka hiệu quả: https://bizflycloud.vn/kafka
Những lỗi kỹ thuật thường gặp khi triển khai Kafka Connect
Lỗi không nhận plugin connector
Đây là lỗi phổ biến khi plugin path cấu hình sai, image không chứa thư viện cần thiết hoặc worker chưa được restart sau khi thêm connector mới. Trong cluster nhiều node, chỉ cần một worker thiếu plugin là task có thể fail khi rebalance.
Lỗi serializer hoặc converter không tương thích
Nếu producer side và sink side không dùng cùng chuẩn dữ liệu, pipeline rất dễ gặp lỗi deserialize. Đây là vấn đề thường gặp khi một bên dùng JSON, bên còn lại dùng Avro hoặc khi schema thay đổi nhưng connector chưa được cập nhật converter phù hợp.
Lỗi offset dẫn tới đọc trùng hoặc mất dữ liệu
Offset là nền tảng đảm bảo tính liên tục của pipeline. Khi offset topic bị lỗi, bị xóa hoặc cấu hình commit không phù hợp, connector có thể đọc lại từ đầu hoặc bỏ qua một phần dữ liệu. Với pipeline production, đây là nhóm lỗi cần được kiểm soát chặt.
Lỗi nghẽn ở hệ thống đích
Trong nhiều trường hợp, Kafka Connect không nghẽn ở Kafka mà nghẽn ở đích đến, ví dụ Elasticsearch chậm ghi, database bị giới hạn connection hoặc object storage phản hồi chậm. Khi đó, backlog sẽ tăng dần và task có thể rơi vào trạng thái retry liên tục.
Lỗi do thiết kế task song song chưa hợp lý
Tăng số lượng task không phải lúc nào cũng làm pipeline nhanh hơn. Nếu hệ thống nguồn không hỗ trợ đọc song song tốt, hoặc topic không đủ partition, việc tăng task chỉ làm tăng overhead mà không cải thiện throughput đáng kể.
Một số lưu ý quan trọng khi vận hành Kafka Connect ở production
Khi đưa Kafka Connect vào production, điều cần tránh là xem nó như một công cụ “cài xong là chạy”. Trên thực tế, đây là một thành phần hạ tầng dữ liệu và cần được vận hành với tư duy platform.
Cần quản lý chặt version của connector, kiểm soát schema evolution, chuẩn hóa logging, thiết lập cảnh báo khi task fail, theo dõi internal topics và xây quy trình rollback khi nâng cấp plugin. Ngoài ra, nếu triển khai trên Kubernetes hoặc môi trường cloud-native, cũng nên tính tới autoscaling có kiểm soát, persistent configuration và chiến lược rolling update để tránh gián đoạn pipeline.
Trong các hệ thống có nhiều nguồn dữ liệu quan trọng, việc kết hợp Kafka Connect với một dịch vụ Kafka được quản trị sẵn sẽ giúp giảm mạnh độ phức tạp ở tầng hạ tầng, từ đó đội ngũ kỹ thuật có thể tập trung hơn vào thiết kế luồng dữ liệu, governance và tối ưu ứng dụng downstream.
Kết luận
Kafka Connect không chỉ là một tiện ích bổ sung trong Apache Kafka, mà là lớp tích hợp dữ liệu mang tính chiến lược trong các kiến trúc streaming hiện đại. Giá trị lớn nhất của nó nằm ở việc chuẩn hóa cách dữ liệu đi vào và đi ra khỏi Kafka, đồng thời giảm đáng kể chi phí phát triển và vận hành các pipeline tích hợp.
Khi được triển khai đúng cách, Kafka Connect giúp doanh nghiệp xây dựng hệ thống dữ liệu linh hoạt hơn, dễ mở rộng hơn và bền vững hơn về dài hạn. Tuy vậy, để tận dụng tối đa công cụ này, đội ngũ kỹ thuật cần hiểu rõ cơ chế task, worker, offset, converter và giới hạn thực tế của từng connector. Chỉ khi nhìn Kafka Connect như một thành phần platform thay vì một công cụ import/export đơn giản, doanh nghiệp mới khai thác hết giá trị mà nó mang lại.
Nguồn bài viết: https://bizflycloud.vn/tin-tuc/kafka-connect-la-gi-20260323180047897.htm
All rights reserved
