[K8S] Phần 9: Service Monitor - Cách giám sát ứng dụng trên Prometheus một cách nhanh chóng và hiệu quả
Bài đăng này đã không được cập nhật trong 3 năm
Lời tựa
Chào các bạn, sau bài viết về Monitoring trên Kubernetes sử dụng Prometheus thì có rất nhiều bạn quan tâm tới chủ đề này. Đặc biệt là có một khái niệm nhiều người nhắc tới là "Service Monitoring". Vậy nó là gì, và ứng dụng gì cho việc Monitoring?
Thì trong bài hôm nay mình sẽ giới thiệu nhiều hơn một chút về khái niệm "Service Monitor" nhé!
Giới thiệu
Trong phần trước mình đã giới thiệu về các thành phần của monitoring gồm Alert Manager - Prometheus - Grafana (phần 8: https://viblo.asia/p/k8s-phan-8-monitoring-tren-kubernetes-cluster-dung-prometheus-va-grafana-Qbq5QRkEKD8)
Mục tiêu của bài viết hôm nay sẽ giúp các bạn:
- Cách cấu hình lấy metric một ứng dụng bằng cấu hình job trong scrapeConfig
- Cách cấu hình lấy metric một ứng dụng bằng "Service Monitor"
- Cách cài một ứng dụng hỗ trợ sẵn metric và serviceMonitor
- Cách trouble-shoot các vấn đề phát sinh trong khi cấu hình --> Đây chính là bước quan trọng nhất bởi nhiều bạn cấu hình ko chạy được nhưng lại ko biết làm thế nào để check xem mình sai ở đâu và cần sửa gì rồi đi vào ngõ cụt, chản nản và bỏ cuộc
 )
)
Và để đi vào từng bước chi tiết thì ta nên có cái nhìn tổng quan trước đã, ta có kiến trúc như sau:
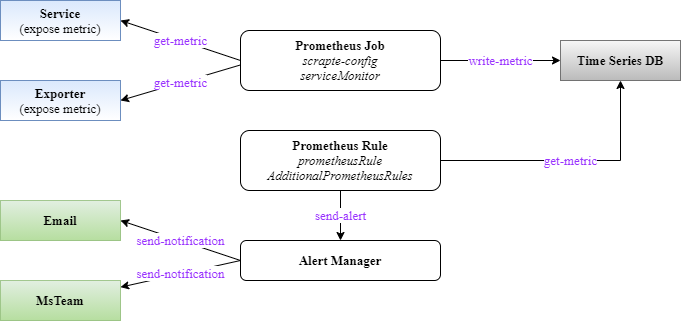
Luồng giám sát được mô tả như sau:
- Prometheus lấy thông tin metric từ các đối tượng cần giám sát. Minh tạm chia các đối tượng này thành 2 loại:
- Một loại hỗ trợ expose metric tương thích với Prometheus, nghĩa là nó có sẵn api cho việc lấy metric và ta chỉ cần cấu hình prometheus lấy metric từ đó
- Một loại không hỗ trợ sẵn metric mà ta sẽ phải cài thêm một exporter (node-exporter là một ví dụ về exporter để lấy metric của node)
- Note: Việc prometheus lấy dữ liệu từ đối tượng nào được gọi là các "job". Các job này chứa thông tin đối tượng nó cần lấy metric cũng như cách lấy metric (tần suất, thời gian lưu...). Và để tạo các "job" này có 2 cách:
- Cấu hình scrape-config cho prometheus: Cách này mình cho là cách truyền thống, và quản lý sẽ rất vất vả nếu số lượng job lớn thì file cấu hình của bạn sẽ phình to và dễ mất control @@. Hơn nữa mỗi lần update thì bạn sẽ phải update cả stack để nó update config mới
- Cấu hình service monitor: Cách này sẽ hiệu quả hơn vì bạn sẽ kiểm soát tốt hơn với từng đối tượng giám sát sẽ tương ứng một file yaml cấu hình riêng cho nó. Hơn nữa không phải đổi lại cấu hình của prometheus server (không cần update stack)
- Khi lấy được metric thì nó sẽ "làm giàu" thông tin của metric đó, ví dụ gán thêm các label nhưng namespace, jobname, servicename.. để phân loại sau này và ghi vào database của Prometheus (làm một internal Time Series Database).
- Prometheus đọc các prometheus rule (là các hàm so sánh giá trị metric với các ngưỡng xác định) để quyết định những rule nào cần cảnh báo (alert) để đẩy về Alert Manager
- Alert Manager sẽ có config riêng của nó để thực hiện việc "phân luồng" cảnh báo tới các người nhận khác nhau, việc này gọi là "route". Thông tin người nhận (gọi là receiver) được cấu hình ở Alert Manager, hỗ trợ khá đa dạng từ email, slack, msteam, telegram...
Prometheus Job và Service monitor
Giờ mình sẽ giới thiệu kỹ hơn về Prometheus Job và cách tạo job này bằng Service Monitor.
Prometheus Job
Là đối tượng lưu thông tin về cách thức lấy dữ liệu metric của một đối tượng cần giám sát, có thể là service, node.. Thông tin của job, được cấu hình trong scrape_config của Prometheus. Một số tham số cấu hình của job có thể không khai báo thì sẽ lấy mặc định ở khai báo global. Với bộ kube-prometheus-stack thì việc khai báo job trong scrapeConfig được thực hiện ở phần cấu hình trong file helm-value ở cấu hình sau:
additionalScrapeConfigs:
- job_name: minio-job
scrape_interval: 30s
scrape_timeout: 5s
metrics_path: /minio/v2/metrics/cluster
scheme: http
static_configs:
- targets: ['minio.monitoring.svc.cluster.local:9000']
Sau đó upgrade lại stack để cập nhật giá trị mới:
helm -n monitoring upgrade prometheus-stack -f values-prometheus-clusterIP.yaml kube-prometheus-stack
Và để cấu hình được prometheus job thì bạn cần nắm rõ thông tin về đối tượng cần lấy metric để khai báo các tham số, quan trọng nhất là metrics_path, targets
Với cấu hình bên trên, mình đang thực hiện lấy metric của service minio với các thông tin như sau:
- Kết nối tới service minio ở namespace monitoring ở port 9000, thông tin đầy đủ là minio.monitoring.svc.cluster.local:9000
- Path để lấy metric là /minio/v2/metrics/cluster
- Giao thức lấy dữ liệu là HTTP
- Thời gian lấy dữ liệu là mỗi 30s
- Thời gian timedout khi lấy dữ liệu là 5s Như vậy mỗi 30s, thì prometheus sẽ gọi request tới http://minio.monitoring.svc.cluster.local:9000/minio/v2/metrics/cluster để lấy metric của service minio.
NOTE: Với service cùng namespace thì các bạn có thể chỉ cần cấu hình tên service là đủ thay vì viết "minio.monitoring.svc.cluster.local" thì có thể chỉ cần viết "minio" cho ngắn gọn.
Các bạn cũng có thể tìm hiểu sâu hơn về scrapeConfig trên trang của Prometheus nhé: https://prometheus.io/docs/alerting/latest/configuration/
Tới đây, bài toán đặt ra là khi bạn cần cấu hình lấy metric của 10 hay 20 hoặc nhiều hơn nữa các service, thì tương ứng mỗi service bạn sẽ phải cấu hình một job trong scrapeConfig này. Sẽ vẫn là OK nếu bạn là một người tay to thực sự và ko ngại việc khai báo thủ công, nhưng chắc chắn nếu mình là manager thì sẽ không đánh giá cao việc này.
Chưa kể tới việc để update cái scrapeConfig này của Prometheus trong bộ cài kube-prometheus-stack, bạn sẽ phải update lại file helm-value (như trong hướng dẫn ở phần 8 (https://viblo.asia/p/k8s-phan-8-monitoring-tren-kubernetes-cluster-dung-prometheus-va-grafana-Qbq5QRkEKD8) và sau đó phải thực hiện update lại cả bộ kube-prometheus-stack bằng lệnh helm upgrade để cập nhật cấu hình mới.
Như vậy cứ mỗi lần cần cấu hình một job lấy dữ liệu cho một service mới thì bạn sẽ phải cập nhật file helm value và upgrade chart một lần. Oh my god!! Ở ĐÂY CHÚNG TÔI KHÔNG LÀM NHƯ VẬY 😂😂😂
Đó là lúc bạn cần sử dụng cái gọi là Service Monitor!!
Service Monitor
ServiceMonitor là một đối tượng của K8S giúp cho Prometheus có thể tự động phát hiện được các đối tượng cần lấy metric. Nó sẽ chứa các thông tin về đối tượng cần giám sát tương tự như cấu hình job trong scrape-config vậy.
Trước tiên bạn cần hiểu về nguyên lý hoạt động của nó đã. Và hình dưới đây sẽ giúp bạn hiểu rõ hơn:
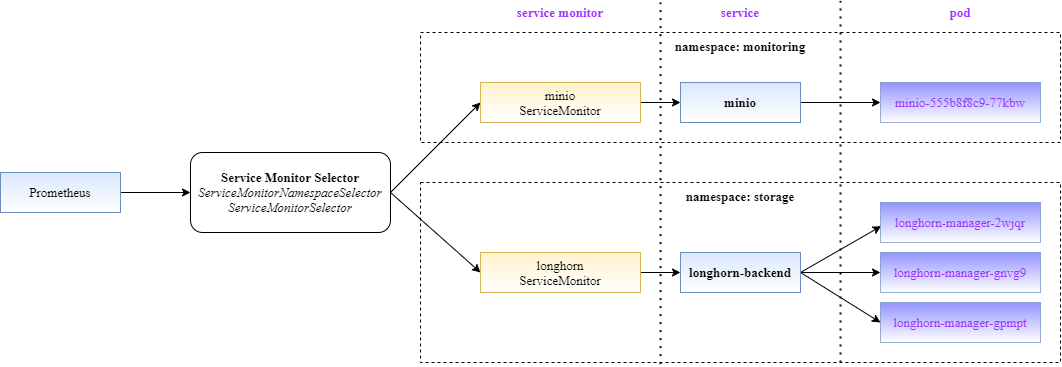
Cách thức hoạt động với ServiceMonitor:
- Prometheus sẽ đọc thông tin job của ở scrapeConfig và từ các ServiceMonitor, tất cả các đối tượng này sẽ hiển thị ở phần targets của Prometheus
- Việc đọc từ scrapeConfig thì là quá rõ ràng rồi, nó được cấu hình ở file config của Prometheus
- Việc đọc ServiceMonitor thì dựa vào cấu hình của Prometheus gồm 2 tham số:
- serviceMonitorNamespaceSelector: Là cấu hình chỉ đọc các ServiceMonitor ở một số namespace nhất định, mặc định là đọc từ tất cả các namespace
- serviceMonitorSelector: Là cấu hình về cách chọn các ServiceMonitor sẽ được đọc để lưu cấu hình job cho Prometheus. Các bạn có thể cấu hình theo nhiều rule khác nhau, mình chọn cách cấu hình theo label của ServiceMonitor là cách đơn giản và dễ dùng nhất.
- Trong cấu hình của ServiceMonitor sẽ có thông tin label của nó (dùng cho Prometheus select như trên) và các thông tin tới đối tượng cần giám sát (giống các thông tin khai báo cho job trong scrapeConfig vậy)
Như vậy trước tiên ta cần cấu hình lại Prometheus để update lại cấu hình ServiceMonitor selector. Ở đây mình sẽ select từ tất cả namespace, và sẽ filter các ServiceMonitor có gán label** app.kubernetes.io/instance** tương ứng với giá trị mình sẽ set cho các serviceMonitor khai báo sau này là viettq-service-monitor.
Mình sẽ sửa lại tham số "serviceMonitorSelector:" trong helm-value của kube-prometheus-stack (file values-prometheus-clusterIP.yaml) như sau:
serviceMonitorSelector:
matchExpressions:
- key: app.kubernetes.io/instance
operator: In
values:
- viettq-service-monitor
- nginx-ingress-controller
- prometheus-stack
sau đó upgrade lại stack để cập nhật giá trị mới:
helm -n monitoring upgrade prometheus-stack -f values-prometheus-clusterIP.yaml kube-prometheus-stack
Như vậy tất cả các serviceMonitor ở tất cả các namespace nếu có gán label app.kubernetes.io/instance với 1 trong các giá trị như trên thì sẽ được Prometheus đọc vào nạp vào cấu hình của nó.
Đến đây thì việc giám sát thêm 10 hay 20 service mới đã không còn là vấn đề nữa. Bạn chỉ cần thống nhất 1 label sẽ gán cho toàn bộ các serviceMonitor mới sau này trùng với cấu hình serviceMonitorSelector của Prometheus là nó sẽ tự động được đọc và không cần phải update gì với Prometheus nữa cả! Ngoài ra, với cách tiếp cận này, mỗi service cần giám sát bạn sẽ tạo một file serviceMonitor dạng yaml sẽ rất tiện lợi cho việc quản lý, cập nhật và tái sử dụng sau này.
Đây là cấu hình mẫu của ServiceMonitor để giám sát service minio, tương tự với cấu hình scrapeConfig mình giới thiệu bên trên. Bạn tạo file serviceMonitor-minio.yaml với nội dung như sau:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: minio-monitor
# Change this to the namespace the Prometheus instance is running in
namespace: monitoring
labels:
app.kubernetes.io/instance: viettq-service-monitor
spec:
endpoints:
- port: 9000
interval: 15s
scheme: http
metrics_path: /minio/v2/metrics/cluster
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
app.kubernetes.io/instance: minio
Và apply nó vào k8s và kiểm tra kết quả:
[sysadmin@vtq-cicd prometheus]$ kubectl apply -f serviceMonitor-minio.yaml
[sysadmin@vtq-cicd prometheus]$ kubectl -n monitoring get servicemonitors.monitoring.coreos.com -l "app.kubernetes.io/instance=viettq-service-monitor"
NAME AGE
fluentd 6d17h
longhorn-prometheus-servicemonitor 21d
minio-monitor 21d
redis-cluster 18d
Với cấu hình trên thì đối tượng serviceMonitor có tên là minio-monitor sẽ được deploy vào namespace là monitoring, và có gán key "app.kubernetes.io/instance: viettq-service-monitor" thỏa mãn điều kiện trong cấu hình serviceMonitorSelector của Prometheus nên nó sẽ được Prometheus nạp vào cấu hình của nó.
Tiếp đến, trong cấu hình của serviceMonitor này sẽ có phần cấu hình spec chính là cấu hình thông tin lấy metric từ đối tượng cần giám sát, gồm thông tin endpoints (port/metric_path) và thông tin object cần giám sát (namespaceSelector và selector)
Để làm rõ chỗ này, các bạn thực hiện lệnh get service theo thông tin selector bên trên trong cấu hình serviceMonitor sẽ rõ. Nó sẽ tìm đến service ở namespace là monitoring có gán label app.kubernetes.io/instance=minio:
[sysadmin@vtq-cicd prometheus]$ kubectl -n monitoring get service -l "app.kubernetes.io/instance=minio"
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
minio ClusterIP 10.233.19.122 <none> 9000/TCP,9001/TCP 21d
Chỗ này các bạn cần lưu ý về đối tượng giám sát có 2 loại: Chính nó hỗ trợ metric hay phải dùng exporter. Trong trường hợp này minio hỗ trợ sẵn metric nên ta sẽ kết nối tới service minio ở port và path mà nó cung cấp metric.
Với trường hợp service không hỗ trợ metric mà phải dùng exporter thì ta sẽ cần cấu hình phần endpoints và selector bên trên tới thông tin service exporter.
Cài service hỗ trợ sẵn cả metric và serviceMonitor (redis)
Có một điều rất tuyệt vời là nhiều open-source cài qua helm-chart ngoài hỗ trợ sẵn metric còn hỗ trợ luôn cả template tạo serviceMonitor và PrometheusRule luôn. Ở đây mình sẽ cài thử redis bằng helm là một opensource mà mình thấy hỗ trợ tất cả những thứ mình nói bên trên. Cách cài một phần mềm dùng helm thì mình đã mô tả nhiều ở các phần trước rồi nên ở đây mình nói nhanh và tóm tắt thôi.
mkdir -p /home/sysadmin/open-sources
cd /home/sysadmin/open-sources
mkdir redis
cd redis
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
helm search repo redis
helm pull bitnami/redis-cluster --version 7.5.1
ls -lrt
tar -xzf redis-cluster-7.5.1.tgz
cp redis-cluster/values.yaml values-redis.yaml
vi values-redis.yaml
Mình sẽ cài redis lên namespace prod sử dụng hầu hết cấu hình mặc định, chỉ sửa một vài tham số như sau để enable metric và serviceMonitor:
usePassword: false
redis: "30101"
type: NodePort
storageClass: "longhorn-storage-delete"
size: 1Gi
metrics:
enabled: true
serviceMonitor:
enabled: true
namespace: "monitoring"
labels:
app.kubernetes.io/instance: viettq-service-monitor
Sau khi cập nhật các giá trị trong file values-redis.yaml như bên trên thì thực hiện cài đặt:
[sysadmin@vtq-cicd redis]$ helm -n prod install redis-cluster -f values-redis.yaml redis-cluster
[sysadmin@vtq-cicd redis]$ kubectl -n prod get pods -l " app.kubernetes.io/instance=redis-cluster"
NAME READY STATUS RESTARTS AGE
redis-cluster-0 2/2 Running 0 19d
redis-cluster-1 2/2 Running 0 19d
redis-cluster-2 2/2 Running 0 19d
redis-cluster-3 2/2 Running 0 19d
redis-cluster-4 2/2 Running 0 19d
redis-cluster-5 2/2 Running 0 19d
[sysadmin@vtq-cicd redis]$ kubectl -n prod get service -l " app.kubernetes.io/instance=redis-cluster"
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-cluster NodePort 10.233.63.22 <none> 6379:30101/TCP 19d
redis-cluster-headless ClusterIP None <none> 6379/TCP,16379/TCP 19d
redis-cluster-metrics ClusterIP 10.233.49.30 <none> 9121/TCP 19d
[sysadmin@vtq-cicd redis]$ kubectl -n monitoring get servicemonitors.monitoring.coreos.com redis-cluster
NAME AGE
redis-cluster 19d
Như vậy sau khi cài đặt ta có một cụm redis-cluster gồm 6 pods, 3 service ở namespace prod và một object serviceMonitor là redis-cluster được tạo ở namespace monitoring (theo đúng những gì ta cấu hình ở file values-redis.yaml
Giờ ta kiểm tra xem thằng serviceMonitor của redis này có gì:
[sysadmin@vtq-cicd redis]$ kubectl -n monitoring describe servicemonitors.monitoring.coreos.com redis-cluster
Name: redis-cluster
Namespace: monitoring
Labels: app.kubernetes.io/instance=viettq-service-monitor
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=redis-cluster
helm.sh/chart=redis-cluster-7.5.1
Annotations: meta.helm.sh/release-name: redis-cluster
meta.helm.sh/release-namespace: prod
API Version: monitoring.coreos.com/v1
Kind: ServiceMonitor
Metadata:
Creation Timestamp: 2022-04-29T03:27:03Z
Generation: 1
Managed Fields:
API Version: monitoring.coreos.com/v1
Fields Type: FieldsV1
<some information truncated>
Manager: helm
Operation: Update
Time: 2022-04-29T03:27:03Z
Resource Version: 5816043
Self Link: /apis/monitoring.coreos.com/v1/namespaces/monitoring/servicemonitors/redis-cluster
UID: bafc11b4-e814-4968-ad0d-2782184c6515
Spec:
Endpoints:
Port: metrics
Namespace Selector:
Match Names:
prod
Selector:
Match Labels:
app.kubernetes.io/component: metrics
app.kubernetes.io/instance: redis-cluster
app.kubernetes.io/name: redis-cluster
Events:
Trong đó ta thấy một vài thông tin quan trọng như:
- "Labels: app.kubernetes.io/instance=viettq-service-monitor" --> Đây chính là thông tin Label để Prometheus lựa chọn đọc thông tin từ serviceMonitor này (như đã mô tả bên trên). Với mỗi serviceMonitor mới ta sẽ đều thêm label này vào để được đọc tự động vào Prometheus.
- Thông tin spec: Là thông tin tới đối tượng cần lấy metric. Ở đây nó tự hiểu cần kết nối tới service ở namespace prod mà có gán các Label như bên dưới, ở port tên là metrics.
Spec:
Endpoints:
Port: metrics
Namespace Selector:
Match Names:
prod
Selector:
Match Labels:
app.kubernetes.io/component: metrics
app.kubernetes.io/instance: redis-cluster
app.kubernetes.io/name: redis-cluster
Verify lại thông tin service được chỉ định theo spec trên bằng lệnh:
[sysadmin@vtq-cicd redis]$ kubectl -n prod get service -l "app.kubernetes.io/component=metrics" -l "app.kubernetes.io/instance=redis-cluster" -l "app.kubernetes.io/name=redis-cluster"
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-cluster NodePort 10.233.63.22 <none> 6379:30101/TCP 19d
redis-cluster-headless ClusterIP None <none> 6379/TCP,16379/TCP 19d
redis-cluster-metrics ClusterIP 10.233.49.30 <none> 9121/TCP 19d
Quay lại trang Prometheus xem service này đã được hiển thị trong phần targets hay chưa:
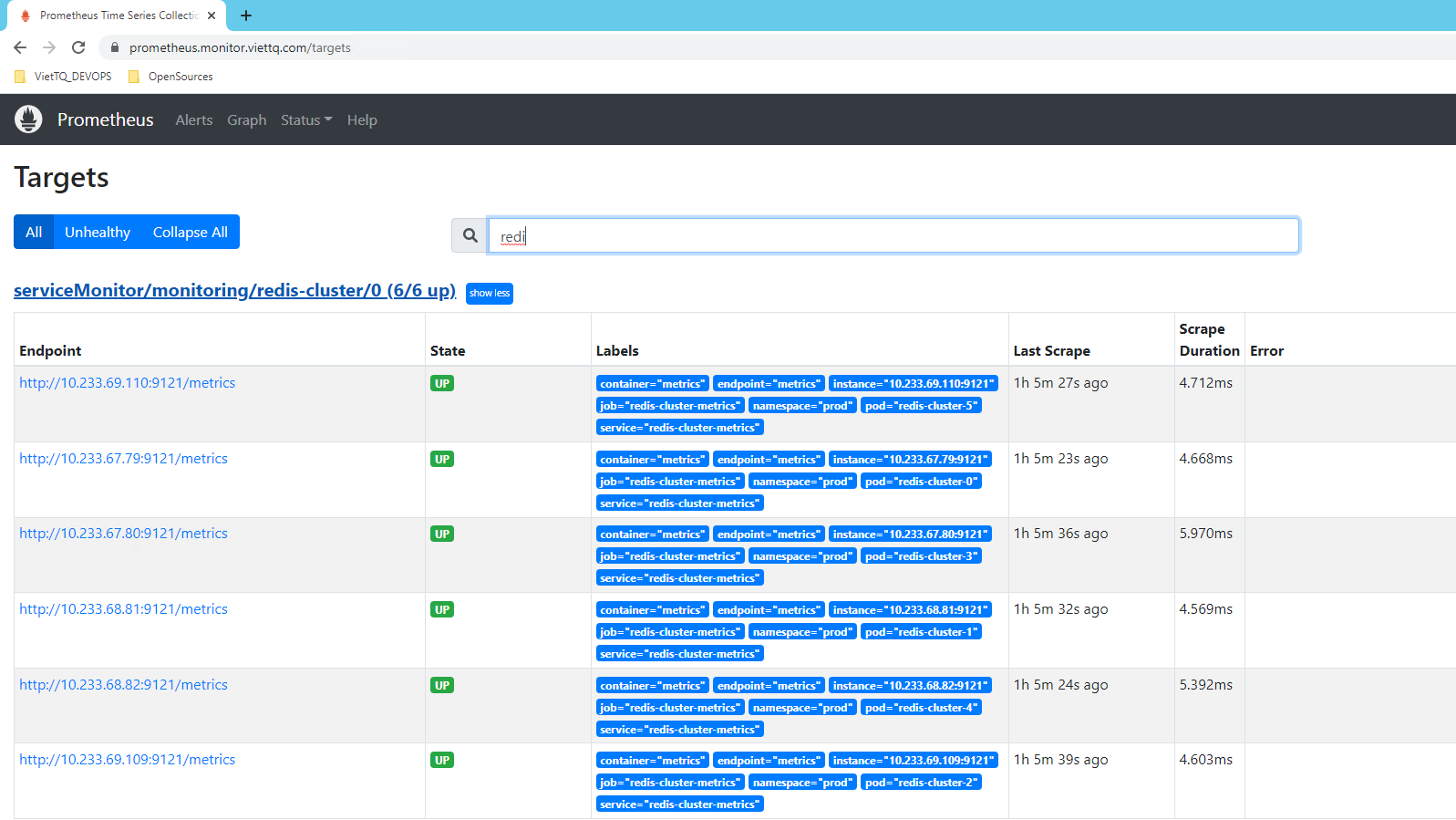
Như vậy là phần lấy metric của Redis đã ok rồi. Thật sự là đơn giản và nhanh gọn phải không các bạn
Tiếp đến là chút màu mè cho nó bằng cách add redis-dashboard trên Grafana (cái này các bạn tự tìm trên mạng nhé, mình làm lâu quên mất ID của dashboard rồi).
Và đây là thành quả để tiếp tục up facebook đây:
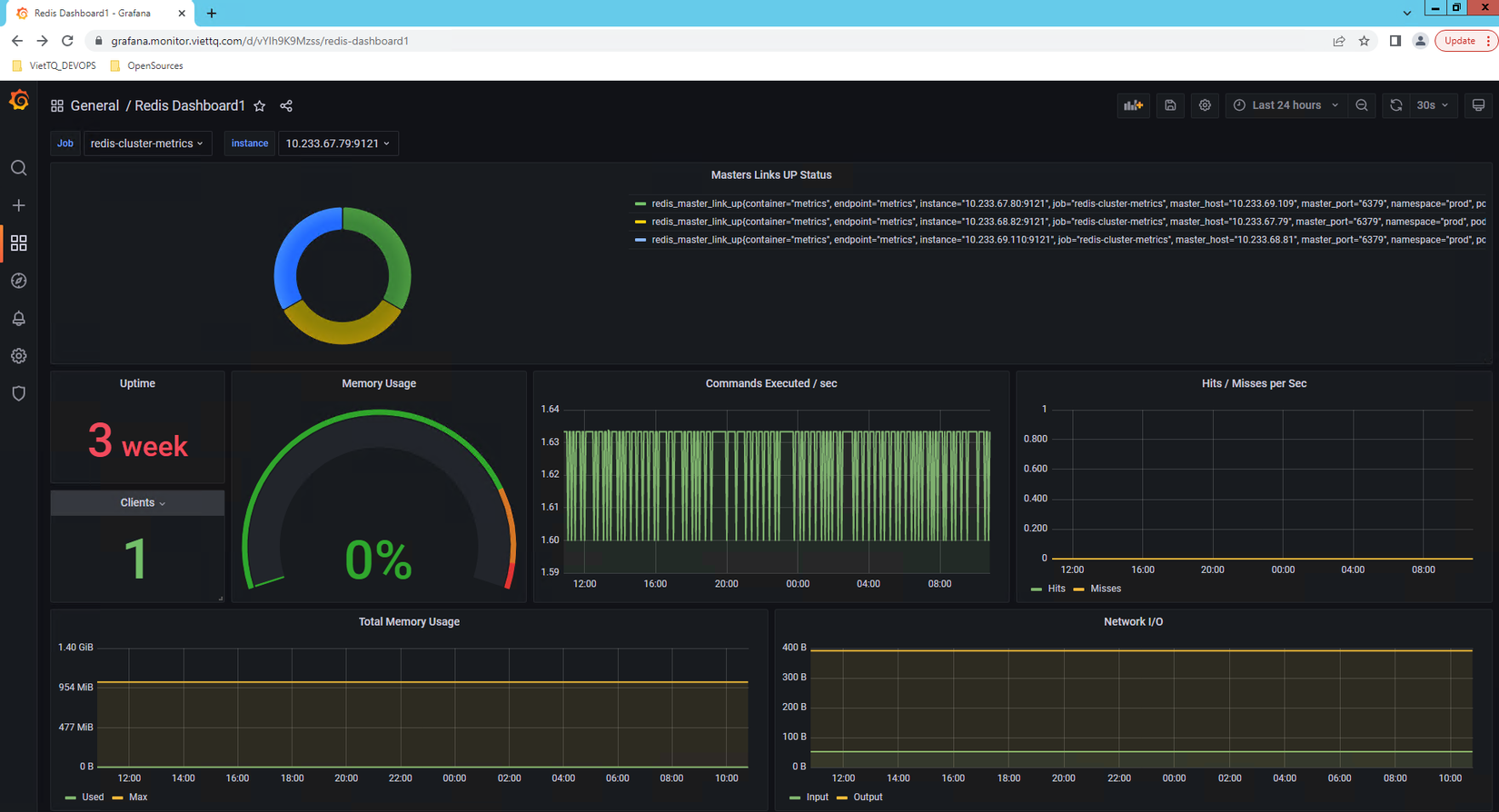
Và cũng hoàn toàn tương tự với redis, khi cài đặt NGINX-Ingress controller thì các bạn cũng hoàn toàn có thể enable metric và serviceMonitor cho nó (các bạn tự voọc file helm-value của nó nhé) sau đó cũng download grafana-dashboard cho nó để hiển thị sẽ được kết quả long lanh như thế này:
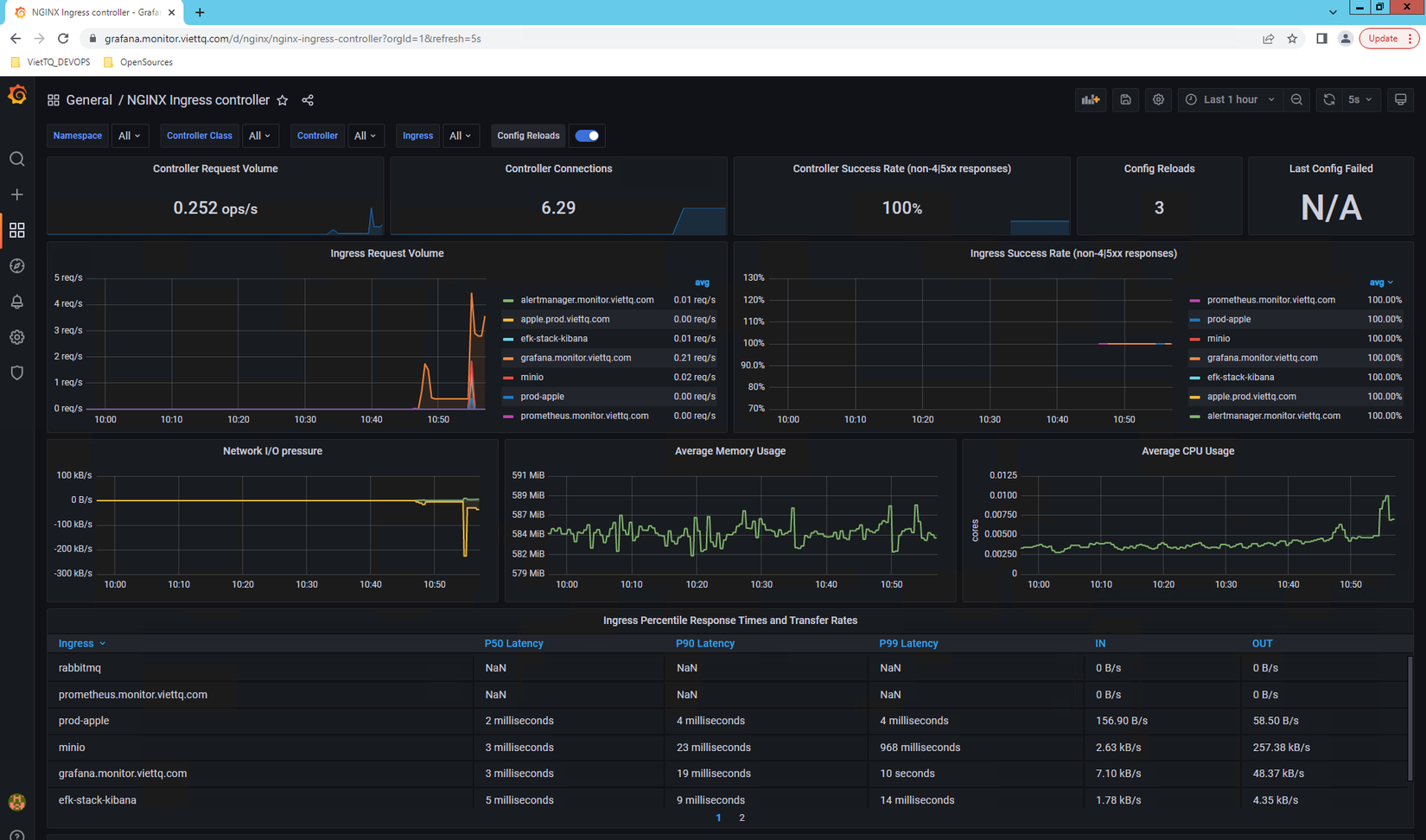
Bonus
Thêm một thông tin nữa nếu bạn nào cài đặt Longhorn storage cho K8S có thể sẽ gặp phải vấn đề cấu hình scrapeConfig xong thì nó sẽ chỉ lấy được thông tin của 1 node (trong N node mà bạn có). Muốn lấy metric của Longhorn thì bắt buộc phải sử dụng qua serviceMonitor để nó lấy đủ thông tin từ tất cả các node nhé! Các bạn có thể tham khảo cấu hình serviceMonitor của Longhorn như sau nhé, tùy biến theo môi trường của các bạn nữa là ok:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: longhorn-prometheus-servicemonitor
namespace: monitoring
labels:
name: longhorn-prometheus-servicemonitor
release: prometheus-grafana-stack
k8s-app: longhorn
app: kube-prometheus-stack
app.kubernetes.io/instance: viettq-service-monitor
spec:
selector:
matchLabels:
app: longhorn-manager
namespaceSelector:
matchNames:
- storage
endpoints:
- port: manager
Sau đó bạn tìm grafana-dashboard cho nó nhé (keyword: longhorn example v1.1.0) để hiển thị thông tin lên dashboard:
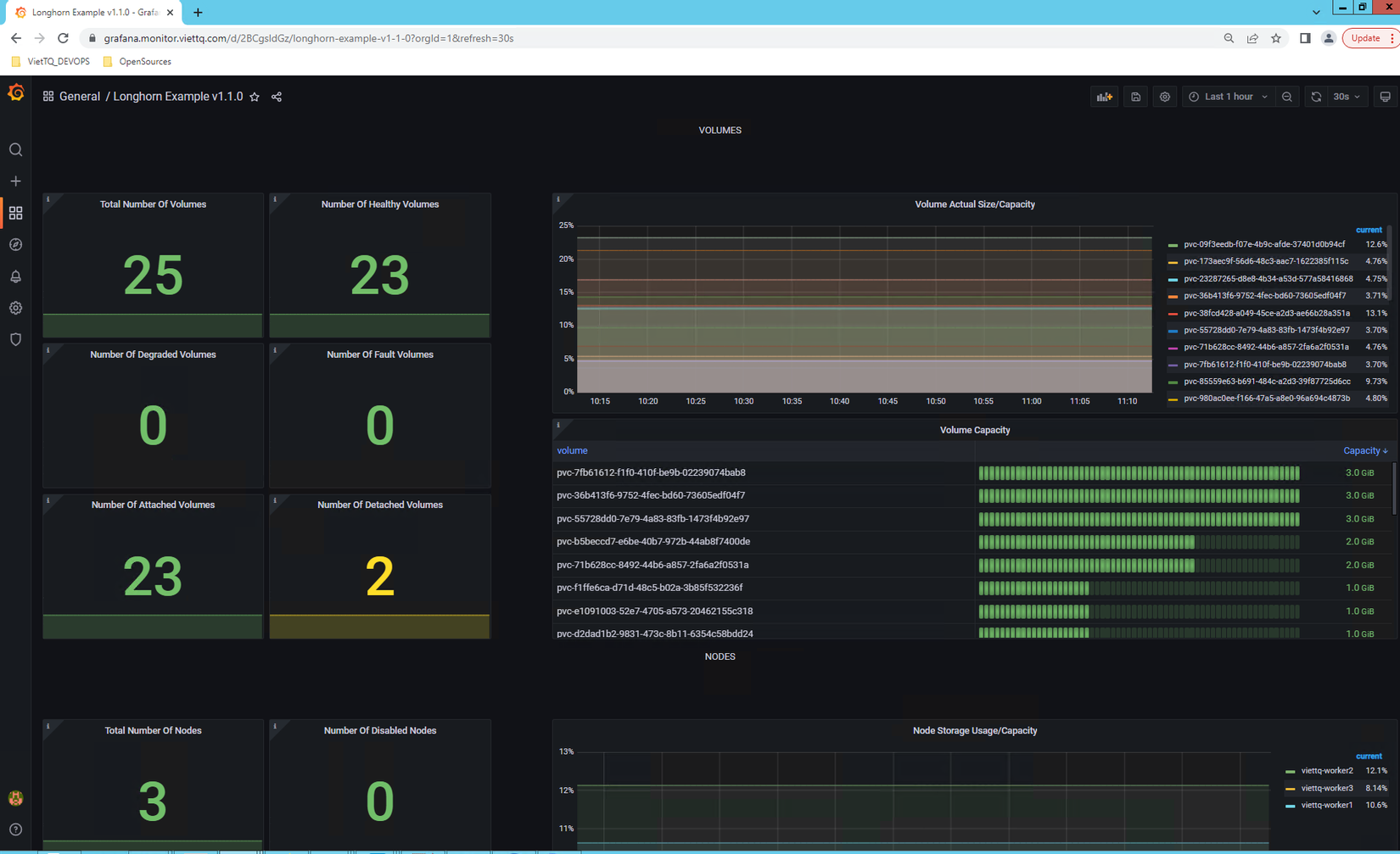
Chúc các bạn thành công :>
PS: Trong phần tiếp theo mình sẽ hướng dẫn tiếp về cấu hình Alert Manager và cách sử dụng PrometheusRule (tương tự như bạn dùng serviceMonitor vậy). Mong các bạn tiếp tục theo dõi và ủng hộ nhé!
All rights reserved
