[K8S basic] Advanced Scheduling - Lập lịch trên Kubernetes dùng Affinity
Bài đăng này đã không được cập nhật trong 3 năm
Mở đầu
Hello mọi người đã trở lại với series k8s basic. Trong bài trước mình đã giới thiệu một số cách thức sử dụng trong lập lịch thực hiện các work load như:
- Tạo static Pod
- Sử dụng nodeName
- Sử dụng nodeSelector
- Sử dụng Taint/Toleration
Trong bài này mình sẽ tiếp tục giới thiệu một số cách thức nữa thường được sử dụng trong cấu hình ứng dụng phục vụ các yêu cầu lập lịch khác nhau như:
- NodeAffinity: Lựa chọn node thỏa mã các điều kiện về labels của node
- PodAffinity: Tạo Pod trên node mà trên đó phải có Pod khác có label thỏa mãn điều kiện cho trước
- PodAntiAffinity: Tạo Pod trên node mà trên đó phải KHÔNG CÓ Pod khác có label thỏa mãn điều kiện cho trước

Trong môi trường lab của mình đang cài đặt kubernetest v1.20.7 có 3 master và 3 worker như sau:
[sysadmin@viettq-master1 ~]$ k get nodes -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
viettq-master1 Ready control-plane,master 99d v1.20.7 192.168.10.11 <none> CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 docker://20.10.10
viettq-master2 Ready control-plane,master 99d v1.20.7 192.168.10.12 <none> CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 docker://20.10.10
viettq-master3 Ready control-plane,master 99d v1.20.7 192.168.10.13 <none> CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 docker://20.10.10
viettq-worker1 Ready <none> 99d v1.20.7 192.168.10.14 <none> CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 docker://20.10.10
viettq-worker2 Ready <none> 99d v1.20.7 192.168.10.15 <none> CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 docker://20.10.10
viettq-worker3 Ready <none> 99d v1.20.7 192.168.10.16 <none> CentOS Linux 7 (Core) 3.10.0-1160.45.1.el7.x86_64 docker://20.10.10
[sysadmin@viettq-master1 ~]$
Sử dụng NodeAffinity
Nhắc lại trong bài trước, chúng ta có đặt ra bài toán là cấu hình cho Pod chỉ chạy trên các Node có cấu hình lớn (size=large). Tuy nhiên với bài toán ngược lại là chỉ chọn các node có cấu hình vừa và nhỏ để chạy Pod (size != large) thì cách dùng nodeSelector sẽ không giải quyết được bài toán.
Bởi nodeSelector chỉ cho phép chúng ta định nghĩa ra tập node theo một điều kiện label duy nhất. Vậy để giải quyết bài toán này thì chúng ta sẽ phải dùng tới cấu hình nodeAffinity.
Ý tưởng của cấu hình nodeAffinity giống với nodeSelector đó là đều lựa chọn node để thực thi Pod, tuy nhiên điều kiện lựa chọn của nodeAffinity thì linh động và đa dạng hơn so với nodeSelector, chúng ta có thể sử dụng nhiều toán tử so sánh hơn.
Khi sử dụng cấu hình NodeAffinity thì chúng ta có 2 loại:
- requiredDuringSchedulingIgnoredDuringExecution (hard): Scheduler sẽ không thể lập lịch cho Pod cho đến khi rule của NodeAffinity được thỏa mãn.
- preferredDuringSchedulingIgnoredDuringExecution (soft): Với cấu hình này thì ta thông báo cho scheduler "cố gắng hết sức" để tìm ra các node thỏa mãn điều kiện. Tuy nhiên khi đã "cố gắng hết sức" rồi mà không tìm dc node nào thỏa mã thì Pod sẽ vẫn được lập lịch.
Sử dụng hard nodeAffinity
Tiếp tục trở lại bài toán ban đầu là làm sao để lựa chọn các node có cấu hình "không lớn" để chạy Pod. Lúc này ta sẽ sử dụng cấu hình NodeAffinity.
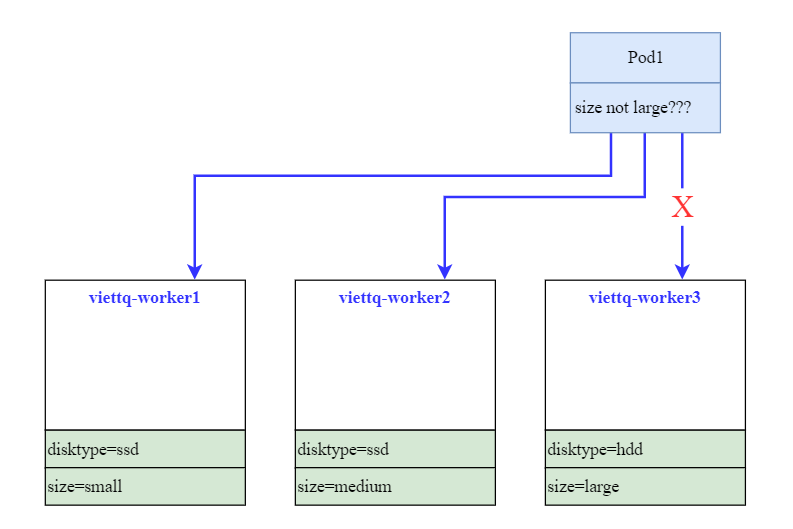
Mấu chốt ở đây nằm ở cấu hình affinity cho Pod như sau:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: NotIn
values:
- large
Lab1: Ta tạo file manifest deployment-nodeaffinity.yaml có nội dung như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: deployment-nodeaffinity
name: deployment-nodeaffinity
spec:
replicas: 3
selector:
matchLabels:
app: deployment-nodeaffinity
strategy: {}
template:
metadata:
labels:
app: deployment-nodeaffinity
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: NotIn
values:
- large
Thực hiện apply vào hệ thống và kiểm tra kết quả:
[sysadmin@vtq-cicd scheduling]$ k apply -f deployment-nodeaffinity.yaml
deployment.apps/deployment-nodeaffinity created
[sysadmin@vtq-cicd scheduling]$ k get pod -l "app=deployment-nodeaffinity" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-nodeaffinity-598bb4c77b-6gwp8 1/1 Running 0 26s 10.233.68.88 viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-hcj6d 1/1 Running 0 26s 10.233.68.89 viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-qkhmh 1/1 Running 0 26s 10.233.68.90 viettq-worker2 <none> <none>
Như vậy các Pod sinh ra của deployment đều chạy trên node viettq-worker2, đây là node có label size=medium thỏa mãn điều kiện của nodeAffinity mà chúng ta đã cấu hình cho deployment.
[sysadmin@vtq-cicd scheduling]$ k get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
viettq-worker1 Ready <none> 99d v1.20.7 disktype=ssd,kubernetes.io/hostname=viettq-worker1,size=small
viettq-worker2 Ready <none> 99d v1.20.7 disktype=ssd,kubernetes.io/hostname=viettq-worker2,size=medium
viettq-worker3 Ready <none> 99d v1.20.7 disktype=hdd,kubernetes.io/hostname=viettq-worker3,size=large
Và để trực quan hơn nữa thì mình sẽ scale deployment này thành 20 Pod để kiểm tra:
[sysadmin@vtq-cicd scheduling]$ k scale deployment deployment-nodeaffinity --replicas=20
deployment.apps/deployment-nodeaffinity scaled
[sysadmin@vtq-cicd scheduling]$ k get pod -l "app=deployment-nodeaffinity" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-nodeaffinity-598bb4c77b-5d9zm 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-5s5wm 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-6gwp8 1/1 Running 0 3m31s 10.233.68.88 viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-779bk 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-8fl4p 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-9fgv2 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-bldtg 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-czptc 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-fnjtx 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-hcj6d 1/1 Running 0 3m31s 10.233.68.89 viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-jgwm4 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-kc7j9 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-l5zfr 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-lhrhp 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-qkhmh 1/1 Running 0 3m31s 10.233.68.90 viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-qqnb8 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-qzmd6 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
deployment-nodeaffinity-598bb4c77b-tc4kf 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-thfcj 0/1 ContainerCreating 0 3s <none> viettq-worker1 <none> <none>
deployment-nodeaffinity-598bb4c77b-v5v5x 0/1 ContainerCreating 0 3s <none> viettq-worker2 <none> <none>
[sysadmin@vtq-cicd scheduling]$
Thì kết quả cho ra 20 Pod vẫn chỉ chạy trên 2 node viettq-worker1 và viettq-worker2 thỏa mãn điều kiện của nodeAffinity.
Lab2: Thay đổi một chút về yêu cầu bài toán như sau
Cấu hình để Pod chỉ chạy trên node có ổ SSD (disktype=ssd) và có cấu hình không nhỏ (size not small). 2 yêu cầu trên cho ta kết quả Pod chỉ được chạy trên node viettq-worker2. Để thực hiện yêu cầu này ta sẽ vẫn dùng cấu hình NodeAffinity tuy nhiên sẽ phải dùng 2 điều kiện lọc.
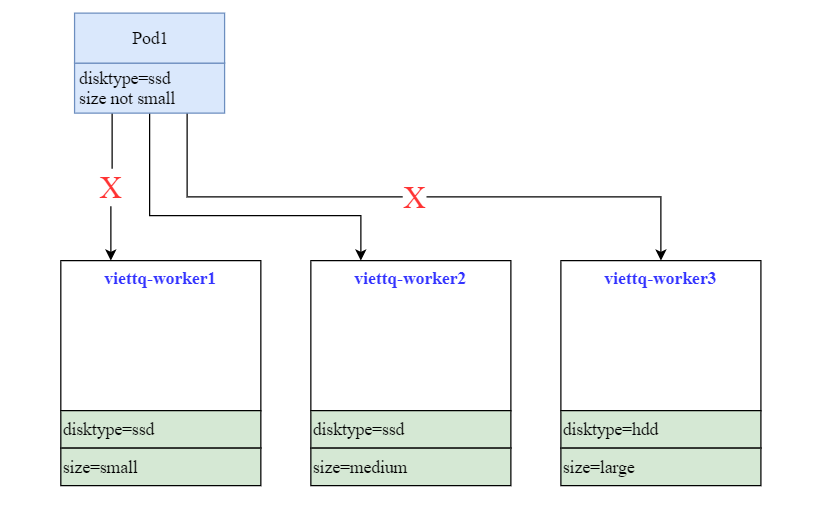
Mấu chốt cho bài toán này nằm ở phần cấu hình nodeAffinity như sau:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
- key: size
operator: NotIn
values:
- small
Tạo file deployment-multi-nodeaffinity.yaml có nội dung như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: deployment-multi-nodeaffinity
name: deployment-multi-nodeaffinity
spec:
replicas: 3
selector:
matchLabels:
app: deployment-multi-nodeaffinity
strategy: {}
template:
metadata:
labels:
app: deployment-multi-nodeaffinity
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
- key: size
operator: NotIn
values:
- small
Thực hiện apply vào hệ thống và kiểm tra:
[sysadmin@vtq-cicd scheduling]$ k apply -f deployment-multi-nodeaffinity.yaml
deployment.apps/deployment-multi-nodeaffinity created
[sysadmin@vtq-cicd scheduling]$ k get pods -l "app=deployment-multi-nodeaffinity" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-multi-nodeaffinity-56b9d8546b-f98lx 1/1 Running 0 6s 10.233.68.102 viettq-worker2 <none> <none>
deployment-multi-nodeaffinity-56b9d8546b-fw7cw 1/1 Running 0 6s 10.233.68.104 viettq-worker2 <none> <none>
deployment-multi-nodeaffinity-56b9d8546b-np6jd 1/1 Running 0 6s 10.233.68.103 viettq-worker2 <none> <none>
Lúc này kết quả cho thấy cả 3 Pod sinh ra đều chạy trên node viettq-worker2 đúng như chúng ta mong muốn.
Lab3: Tiếp tục thay đổi yêu cầu bài toán như sau:
Cấu hình để Pod chỉ chạy trên node có ổ SSD (disktype=ssd) và có cấu hình lớn (size=large). Thực tế với hiện trạng 3 node của chúng thì sẽ không có node nào thỏa mãn cả 2 điều kiện trên ==> Pod sinh ra sẽ ở trạng thái Pending.
Để thực hiện yêu cầu này ta sẽ vẫn dùng cấu hình NodeAffinity.
Tạo file deployment-multi-nodeaffinity.yaml có nội dung như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: deployment-multi-nodeaffinity2
name: deployment-multi-nodeaffinity2
spec:
replicas: 3
selector:
matchLabels:
app: deployment-multi-nodeaffinity2
strategy: {}
template:
metadata:
labels:
app: deployment-multi-nodeaffinity2
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
- key: size
operator: In
values:
- large
Thực hiện apply vào hệ thống và kiểm tra:
[sysadmin@vtq-cicd scheduling]$ k apply -f deployment-multi-nodeaffinity2.yaml
deployment.apps/deployment-multi-nodeaffinity2 created
[sysadmin@vtq-cicd scheduling]$ k get pods -l "app=deployment-multi-nodeaffinity2" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-multi-nodeaffinity2-69f4b94ccf-6q4mg 0/1 Pending 0 8s <none> <none> <none> <none>
deployment-multi-nodeaffinity2-69f4b94ccf-gljfd 0/1 Pending 0 8s <none> <none> <none> <none>
deployment-multi-nodeaffinity2-69f4b94ccf-swrn5 0/1 Pending 0 8s <none> <none> <none> <none>
[sysadmin@vtq-cicd scheduling]$
Đúng như dự đoán, 3 Pod sinh ra bởi deployment này đều ở trạng thái Pending. Nguyên nhân là chúng ta đang cấu hình tham số requiredDuringSchedulingIgnoredDuringExecution do đó khi không tìm được node thỏa mãn thì Pod sẽ ở trạng thái Pending.
Sử dụng soft nodeAffinity
Trong lab trên khi chúng ta thiết lập các cấu hình nodeAffinity và không có node nào thỏa mãn thì ứng dụng của chúng sẽ không được lập lịch và thực hiện.
Do đó thay vì "cứng nhắc" bắt buộc phải tuân theo rule đó thì chúng ta có thể lựa chọn cấu hình "soft rule" tức là cố gắng hết sức để lựa chọn theo điều kiện nhưng nếu không thể tìm được node thỏa mãn thì sẽ vẫn lập lịch thực hiện.
Lab1: Ưu tiên cao nhất cho việc lập lịch cho Pod trên node có size=large, nếu không có thì tiếp tục ưu tiên node có ổ SSD disktype=ssd.
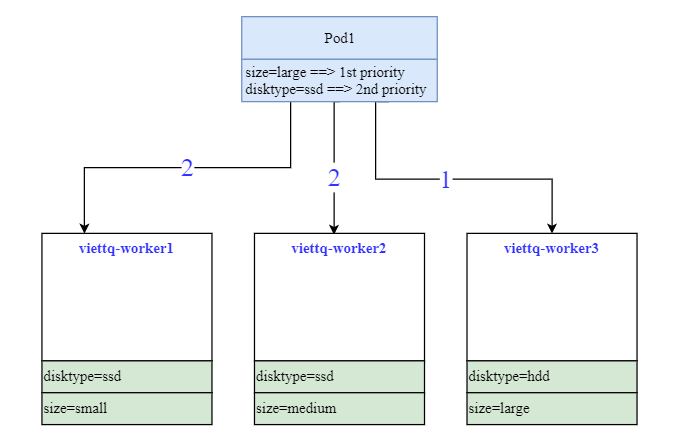
Với yêu cầu và hiện trạng như trên thì các Pod sinh ra sẽ luôn được ưu tiên chạy trên node viettq-worker3.
Tạo file deployment-prefer-nodeaffinity.yaml có nội dung như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: deployment-prefer-nodeaffinity
name: deployment-prefer-nodeaffinity
spec:
replicas: 3
selector:
matchLabels:
app: deployment-prefer-nodeaffinity
strategy: {}
template:
metadata:
labels:
app: deployment-prefer-nodeaffinity
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: size
operator: In
values:
- large
- weight: 50
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
Ta apply file trên vào hệ thống và kiểm tra kết quả:
[sysadmin@vtq-cicd scheduling]$ k apply -f deployment-prefer-nodeaffinity.yaml
deployment.apps/deployment-prefer-nodeaffinity created
[sysadmin@vtq-cicd scheduling]$ k get pods -l "app=deployment-prefer-nodeaffinity" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-prefer-nodeaffinity-78b9bcc67b-6hcvg 1/1 Running 0 18s 10.233.67.124 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-fhsf9 1/1 Running 0 18s 10.233.67.123 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-vpb7b 1/1 Running 0 18s 10.233.67.122 viettq-worker3 <none> <none>
Đúng như lý thuyết đã phân tích, các Pod sinh ra đều được lập lịch thực hiện trên node viettq-worker3. Để củng cố thêm nữa thì mình sẽ lại scale deployment thành 20 Pod để check xem sao:
[sysadmin@vtq-cicd scheduling]$ k scale deployment deployment-prefer-nodeaffinity --replicas=20
deployment.apps/deployment-prefer-nodeaffinity scaled
[sysadmin@vtq-cicd scheduling]$ k get pods -l "app=deployment-prefer-nodeaffinity" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-prefer-nodeaffinity-78b9bcc67b-28kv7 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-4tgwv 1/1 Running 0 9s 10.233.67.126 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-5bnqp 1/1 Running 0 9s 10.233.67.125 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-5xrff 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-6hcvg 1/1 Running 0 3m53s 10.233.67.124 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-6tblw 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-79x4l 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-84x2q 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-fhsf9 1/1 Running 0 3m53s 10.233.67.123 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-fpj7j 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-hnkqj 1/1 Running 0 9s 10.233.67.136 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-kprjp 1/1 Running 0 9s 10.233.67.138 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-ld28n 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-n99cs 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-nn8qt 1/1 Running 0 9s 10.233.67.141 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-qkmz9 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-vpb7b 1/1 Running 0 3m53s 10.233.67.122 viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-vzl52 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-zclwc 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
deployment-prefer-nodeaffinity-78b9bcc67b-zw84r 0/1 ContainerCreating 0 9s <none> viettq-worker3 <none> <none>
Kết quả vẫn vậy, các Pod vẫn chỉ ưu tiên chạy trên node viettq-worker3 trừ khi nó hết tài nguyên 
Sử dụng PodAffinity
Khi sử dụng nodeAffinity thì chúng ta đang sử dụng các labels của node để làm điều kiện lựa chọn.
Còn với PodAffinity thì nó vẫn là cách thức lựa chọn node nhưng là dựa vào labels của các Pod chạy trên node.
Hiểu nôm na thì cấu hình PodAffinity tưng tự với việc Pod-A chỉ ưu tiên/yêu cầu chạy trên một node nào đó mà đang có Pod-B đang chạy.
Trong thực tế thì việc này có ý nghĩa gì? Nó giúp chúng ta có thể tùy biến cho các Pod ứng dụng có giao tiếp nhiều với nhau thì ưu tiên chạy trên chung một node để tối ưu kết nối.
Và tương tự như nodeAffinity thì podAffinity cũng có 2 loại:
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
Chúng ta cùng xem xét một ví dụ như sau:
 Trên hệ thống đã triển khai sẵn ứng dụng db, các Pod của DB có label là
Trên hệ thống đã triển khai sẵn ứng dụng db, các Pod của DB có label là app=db. Tôi muốn deploy các Pod BE của tôi lên nhưng node nào có đang chạy DB để tối ưu phần kết nối.
Để giải quyết yêu cầu trên chúng ta sẽ sử dụng cấu hình podAffinity.
Đầu tiên ta sẽ setup 2 Pod chạy trên 2 node và có label là app=db để giả định DB đang chạy trên 2 node này.
Ta sẽ tạo 2 Pod sử dụng cấu hình nodeName để assign trực tiếp vào node:
apiVersion: v1
kind: Pod
metadata:
labels:
app: db
name: pod-db1
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: mynginx
resources: {}
nodeName: viettq-worker1
dnsPolicy: ClusterFirst
restartPolicy: Always
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: db
name: pod-db2
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: mynginx
resources: {}
nodeName: viettq-worker2
dnsPolicy: ClusterFirst
restartPolicy: Always
Lưu nội dung trên thành db-pod.yaml và apply vào hệ thống:
[sysadmin@vtq-cicd scheduling]$ k apply -f db-pod.yaml
pod/pod-db1 created
pod/pod-db2 created
[sysadmin@vtq-cicd scheduling]$ k get pods -l "app=db" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-db1 1/1 Running 0 3s 10.233.69.130 viettq-worker1 <none> <none>
pod-db2 1/1 Running 0 3s 10.233.68.105 viettq-worker2 <none> <none>
Tiếp theo ta sẽ tạo một deployment từ file deployment-pod-affinity.yaml như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: deployment-pod-affinity
name: deployment-pod-affinity
spec:
replicas: 2
selector:
matchLabels:
app: be
strategy: {}
template:
metadata:
labels:
app: be
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- db
topologyKey: kubernetes.io/hostname
Tiến hành apply vào hệ thống và kiểm tra:
[sysadmin@vtq-cicd scheduling]$ k get pod -l "app=deployment-pod-affinity" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-pod-affinity-696c74f6-2dssd 1/1 Running 0 14s 10.233.69.131 viettq-worker1 <none> <none>
deployment-pod-affinity-696c74f6-9dhts 1/1 Running 0 14s 10.233.69.132 viettq-worker1 <none> <none>
Kết quả đúng như mong đợi, các Pod của BE chỉ chạy trên các node có Pod của DB
Tuy nhiên lúc này lại phát sinh ra vấn đề là cả Pod của BE đều chạy trên 1 node. Sẽ là tuyệt vời hơn nếu 2 Pod của BE lại chia đều trên 2 node có chạy Pod DB. Vấn đề này sẽ được giải quyết khi sử dụng cấu hình podAntiAffinity.
Sử dụng PodAntiAffinity
Hiểu nôm na thì cấu hình PodAntiAffinity tưng tự với việc Pod-A chỉ chấp nhận chạy trên một node nào đó mà đang không có Pod-B đang chạy.
Như trong ví dụ trên, best case mà chúng ta muốn là 2 Pod của BE sẽ chạy trên 2 node có Pod DB.
Chúng ta đã giải quyết được 1 nửa bài toán là chỉ cho Pod BE chạy trên node có Pod DB.
Còn nửa còn lại, ý tưởng giải quyết sẽ là "ưu tiên không chạy Pod Be trên node đã có Pod BE". Nghĩa là một node sẽ chỉ có tối đa 1 Pod Be được chạy, như vậy sẽ giải quyết hoàn toàn bài toán.
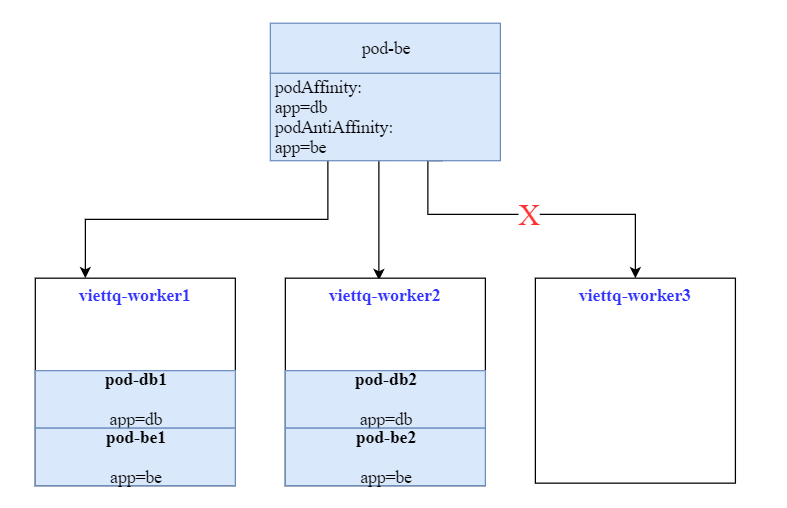
Chúng ta sẽ cập nhật lại deployment bên trên để sử dụng thêm cấu hình podAntiAffinity nữa như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: deployment-pod-affinity
name: deployment-pod-affinity
spec:
replicas: 2
selector:
matchLabels:
app: be
strategy: {}
template:
metadata:
labels:
app: be
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- db
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- be
topologyKey: kubernetes.io/hostname
Thực hiện apply lại vào hệ thống vào kiểm tra:
[sysadmin@vtq-cicd scheduling]$ k apply -f deployment-pod-affinity.yaml
deployment.apps/deployment-pod-affinity created
[sysadmin@vtq-cicd scheduling]$ k get pod -l "app=be" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-pod-affinity-6bccfd9c96-l48hm 1/1 Running 0 15s 10.233.68.106 viettq-worker2 <none> <none>
deployment-pod-affinity-6bccfd9c96-wr6sw 1/1 Running 0 15s 10.233.69.133 viettq-worker1 <none> <none>
Như vậy là 2 Pod BE đã chia đều đúng trên 2 node có chạy Pod DB cho chúng ta. Trong phần cấu hình podAntiAffinity mình chỉ sử dụng mode là preferredDuringSchedulingIgnoredDuringExecution để ưu tiên cho các Pod chia đều ra các node.
Tuy nhiên thực tế sẽ có các bài toán số lượng replicas (số Pod) nhiều hơn số node do đó nên để tham số prefer để nếu có vi phạm thì Pod sẽ vẫn được lên lịch thực hiện chứ không bị pending.
Để làm rõ hơn điều này, mình sẽ thử scale deployment của Be lên thành 4 pod:
[sysadmin@vtq-cicd scheduling]$ k scale deployment deployment-pod-affinity --replicas=4
deployment.apps/deployment-pod-affinity scaled
[sysadmin@vtq-cicd scheduling]$ k get pod -l "app=be" -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-pod-affinity-6bccfd9c96-l48hm 1/1 Running 0 3m48s 10.233.68.106 viettq-worker2 <none> <none>
deployment-pod-affinity-6bccfd9c96-pb52l 1/1 Running 0 3s 10.233.68.107 viettq-worker2 <none> <none>
deployment-pod-affinity-6bccfd9c96-rltz5 1/1 Running 0 3s 10.233.69.134 viettq-worker1 <none> <none>
deployment-pod-affinity-6bccfd9c96-wr6sw 1/1 Running 0 3m48s 10.233.69.133 viettq-worker1 <none> <none>
Như vậy thì sau khi scale ứng dụng vẫn được lập lịch thực hiện được. Nếu chúng ta để cấu hình podAntiAffinity là requiredDuringSchedulingIgnoredDuringExecution thì chỗ này Pod BE của chúng ta sẽ chỉ allocate được 2 Pod (tương ứng 2 node) còn lại sẽ ở trạng thái Pending.
Hy vọng qua bài viết này các bạn đã hiểu về các cơ chế trong việc cấu hình lập lịch cho workload trên k8s. Thực tế thì các bạn sẽ gặp các bài toán cụ thể và sẽ cần kết hợp nhiều kỹ thuật để xử lý vấn đề. Quan trọng là các bạn hiểu từng kỹ thuật đó và áp dụng cho hợp lý.
Nếu thấy nội dung hữu ích thì các bạn vui lòng cho mình một nút Upvote vào bài viết để có động lực tiếp tục viết bài nhé! Many thanks
All rights reserved
