Introduction to Recommender Systems
Bài đăng này đã không được cập nhật trong 6 năm
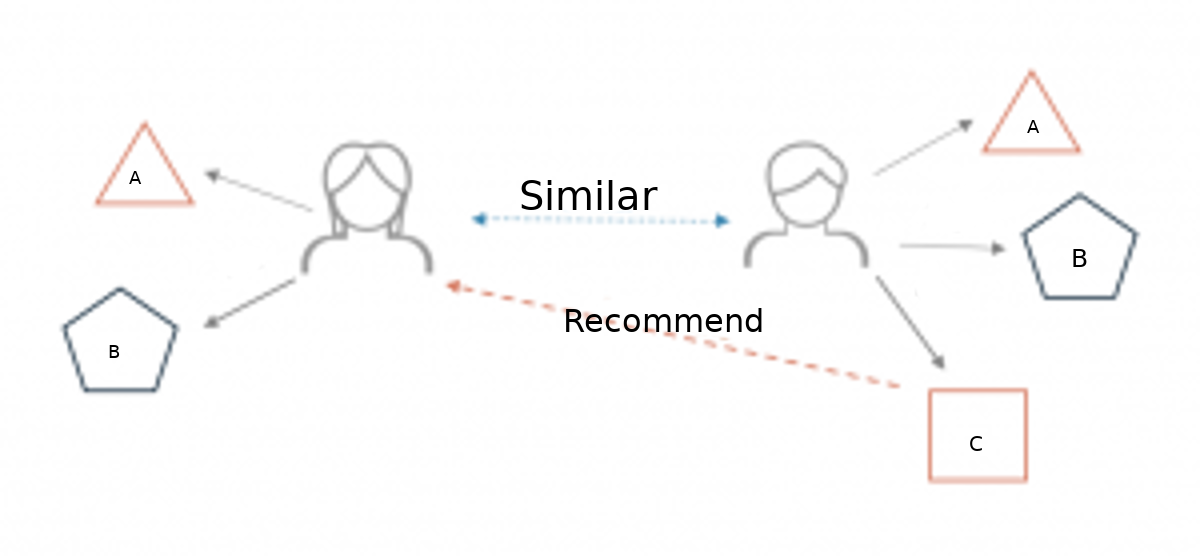
Hệ tư vấn là gì?
Hệ tư vấn (recommender system) là một dạng công cụ lọc thông tin (information filtering) cho phép suy diễn, dự đoán các sản phẩm, dịch vụ, nội dung mà người dùng có thể quan tâm dựa trên những thông tin thu thập được về người dùng, về các sản phẩm, dịch vụ, về các hoạt động, tương tác cũng như đánh giá của người dùng đối với các sản phẩm, dịch vụ trong quá khứ.
Các cách tiếp cận
- Tiếp cận dựa trên luật hay tri thức (rule/knowledge-based)
- Tiếp cận dựa trên lọc cộng tác (collabrative - CF)
- Tiếp cận dựa trên nội dung (content-based)
- Tiếp cận dựa trên sự kết hợp giữa CF và content-based (hybrid)
1. Collaborative filtering - CF (lọc cộng tác)
- Lọc cộng tác thực hiện tư vấn (gợi ý) các sản phẩm, dịch vụ, nội dung cho một người dùng nào đó dựa trên mối quan tâm, sở thích (preferences) của những người dùng tương tự đối với các sản phẩm, dịch vụ, nội dung đó.
- Lọc cộng tác được xem là một trong ba cách tiếp cận chính trong xây dựng các hệ thống tư vấn.
- Có nhiều kỹ thuật lọc cộng tác và được chia thành hai dạng chính:
- Memory–based: lọc cộng tác dựa trên việc ghi nhớ toàn bộ dữ liệu.
- Model–based: Lọc cộng tác dựa trên các mô hình phân lớp, dự đoán.
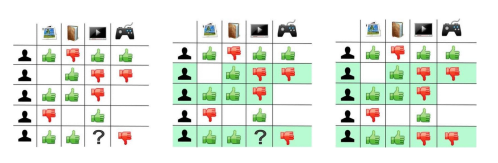
1.1 Ma trận đánh giá (rating matrix, user-item rating matrix)
- m người dùng U = { u1, u2, ..., um}
- n sản phẩm I = {i1, i2, ..., in}
- Ma trận đánh giá R = {ru,i}mxn với ru,i thuộc R


-
Ma trận tường minh (explicit rating matrix)
Người dùng đánh giá trực tiếp đối với các sản phẩm, dịch vụ, nội dung. Thang điểm thường là:- Nhị phân: Like, Dislike.
- Liên tục trong đoạn [0,1]
- Năm mức rời rạc: 1, 2, 3, 4, 5 (với 5 là mức đánh giá tốt nhất)
-
Ma trận đánh giá suy diễn (implicit rating matrix)
Ma trận được suy diễn từ thông tin thu thập được về hành vi người dùng như:- Tìm kiếm (browsing)
- Đọc (reading)
- Xem (watching)
- Chia sẻ (sharing)
- Mua (buying)
Sau đó ánh xạ hành vi người dùng vào các mức điểm.
1.2 Các tính chất của lọc cộng tác
- Dữ liệu thưa (data sparsity)
- Ma trận đánh giá có thể rất thưa.
- Dữ liệu thưa ảnh hưởng rất nhiều đến hiệu quả hệ tư vấn bởi rất khó tính toán sự tương tự giữa các người dùng (users) hoặc giữa các sản phẩm (items)
- Hai sản phẩm có thể rất giống nhau nhưng có ít người cùng đánh giá đồng thời hai sản phẩm.
- Hai người dùng có thể giống nhau về sở thích nhưng chưa đánh giá cùng sản phẩm.
- Giải pháp: Áp dụng các kỹ thuật giảm số chiều (dimensionality reduction)
- Xuất phát nguội (cold start)
- Vấn đề người dùng mới (new user problem)
- Chưa đánh giá sản phẩm nào
- Chưa có các dữ liệu về các hành vi
- Vấn đề sản phẩm mới (new item problem)
- Chưa được người dùng nào đánh giá
- Chưa được ai xem, mua, tìm kiếm, ...
- Giải pháp:
- Tư vấn các sản phẩm phổ biến, ngẫu nhiên cho người dùng mới; các sản phẩm mới được xuất hiện ở đầu trang
- Content-boosted CF: tích hợp thêm hồ sơ (profile) người dùng mới hoặc sử dụng thêm các đặc tính của sản phẩm.
- Khả năng mở rộng (scalability)
- Khi ma trận đánh giá lớn, tức số người dùng lẫn sản phẩm lớn thì thời gian tính toán sẽ tăng cao, khó đáp ứng tư vấn thời gian thực hoặc gần thời gian thực.
- Giải pháp:
- Áp dụng các kỹ thuật giảm số chiều như SVD, PCA.
- Item-based CF có khả năng mở rộng cao hơn so với user-based CF.
- Vấn đề từ đồng nghĩa (synonymy)
- Các từ đồng nghĩa có thể gây cản trở cho việc tính toán độ tương tự.
- Ví dụ: children movie và children film có thể gây ra keyword-mismath, làm ảnh hưởng đến việc tính toán độ tương tự.
- Giải pháp: Áp dụng các kỹ thuật phân tích ngữ nghĩa như LSI (Latent Semantic Indexing), mô hình chủ đề (Topic Models) hoặc Deep Learning để giải quyết vấn đề này.
- Gray sheep và Black sheep
- Gray sheep:
- Những người có sở thích không giống ai.
- CF không có hiệu quả trong trường hợp này.
- Có thể kết hợp CF và content-based.
- Black sheep:
- Những người có đánh giá kì quặc (ví dụ như thích nhưng lại dùng những từ ngữ đánh giá như không thích) nên không thể recommend chính xác cho những người này.
- Shilling attacks
- Xảy ra khi cạnh tranh không lành mạnh:
- Đánh giá sản phẩm của mình cao, đánh giá sản phẩm của đối thủ thấp.
- Item-based CF ít bị ảnh hưởng bởi shilling attacks hơn so với user-based CF.
- Có thể phát hiện hiện tượng này ở bước tiền xử lý bằng phân tích phát hiện ngoại lệ.
1.4 Memory-based CF (lọc cộng tác dựa trên ghi nhớ)
- Sử dụng ma trận đánh giá để thực hiện dự đoán và tư vấn.
- Giả sử mỗi người dùng thuộc ít nhất một nhóm những người có chung sở thích, mối quan tâm.
- Người cần được tư vấn được gọi là active user.
- Những người dùng có sở thích tương tự với active user được gọi là neighbors.
- Cách tiếp cận:
- User-based: dựa trên người dùng để dự đoán.
- Items-based: dựa trên sản phẩm để dự đoán.
Các bước thực hiện
- Bước 1: Similarity computation - Tính toán độ tương tự giữa các người dùng (wu,v) đối với user-based và giữa các sản phẩm (wi,j) đối với items-based.
- Bước 2: Prediction- Ước lượng hay dự đoán giá trị rating của active user đối với một sản phẩm nào đó dựa trên thông tin từ bước 1.
Gợi ý top-N sản phẩm
- Xác định k người dùng tương tự nhất với active user và gọi là k người dùng láng giềng (neighbors).
- Tổng hợp từ k người dùng láng giềng top-N sản phẩm phổ biến nhất để tư vấn cho active user.
Bước 1: Tính toán mức độ tương tự (similarity computation)
- Đối với item-based CF: Tính toán độ tương tự wi,j giữa hai item i và j dựa trên những người dùng cùng đánh giá hai item này.
- Đối với user-based CF: tính toán độ tương tự wu,v giữa hai người dùng u, v dựa trên những đánh giá của hai người dùng này trên cùng các items.
Khoảng cách Consine
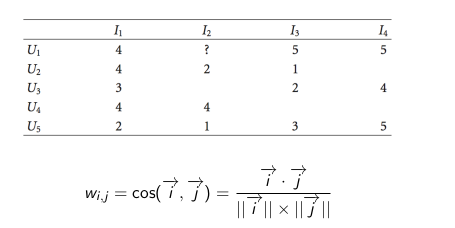
- i và j là hai vecto trong ma trận rating của hai sản phẩm i và j.
- Ở ma trận trên: i1 = (4,4,3,4,2) và i2 = (?,2,?,4,1)
- Khi tính toán wi,j: i1 = (4,4,2) và i2 = (2,4,1)
Khoảng cách Kullback-Leiber
Ký hiệu p(x) và q(x) là hai phân bố xác suất:
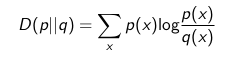
- Với user-based: hai phân bố là hai hàng trong ma trận đánh giá R
- Với item-based: hai phân bố là hai cột trong ma trận đánh giá R
- Các phân bố cần được chuẩn hóa trước khi tính D(p||q) và D(q||p).
Tương quan Pearson - user-based CF

- I là tập các items cả hai người dùng u và v cùng đánh giá.
- ru và rv là rating trung bình của u và v trên các sản phẩm trong I.
Tương quan Pearson - item-based CF
- U là tập các users cùng đánh giá hai sản phẩm i và j.
- ru,i: rating u đối với i, tương tự cho ru,j.
- ri, rj: trung bình rating của các người dùng trong U đối với i và j.
Bước 2: Dự đoán và tư vấn - Weight Sum of Other's Rating
Dự đoán mức độ rating của active user a đối với một sản phẩm i nào đó, ký hiệu là Pa,i:
- ra và ru là rating trung bình của a và u trên các sản phẩm.
- wa,u là mức độ tương tương tự giữa hai người dùng a và u.
- U là tập tất cả người dùng (trừ a) đã đánh giá sản phẩm i.

Dự đoán và tư vấn - Simple Weighted Average
Với tư vấn dựa trện sản phẩm (item-based), giá trị dự đoán rating của một người dùng u trên sản phẩm i, ký hiệu là Pu,i, được tính như sau:
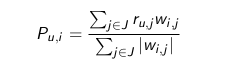
Trong đó:
- J là tập tất cả các sản phẩm (trừ i) mà người dùng u đã đánh giá.
- wi,j là mức độ tương tự giữa hai sản phẩm i và j.
- ru,j là rating của người dùng đối với sản phẩm j.
Top-N recommendations
Gợi ý top-N sản phẩm theo người dùng (user-based)
- Gọi a là active user
- Tìm Ua là tập k người dùng tương tự nhất với a.
- Dùng độ đo tương quan Pearson hoặc Cosine
- Gọi C là tập tất cả các sản phẩm mà các người dùng trong Ua đã mua hoặc đánh giá mà a chưa mua hay đánh giá.
- Xếp hạng các sản phẩm trong C giảm dần theo số người dùng (trong Ua) mua hoặc đánh giá.
- Lấy top-N sản phẩm từ C theo thứ tự xếp hạng trên để tư vấn hay gợi ý cho a.
Gợi ý top N sản phẩm theo sản phẩm (items-based)
- Gọi a là active user, R là ma trận đánh giá.
- Gọi Ia là tập sản phẩm mà a đã mua hoặc đánh giá.
- Với mỗi sản phẩm i trong Ia, xác định k sản phẩm tương tự nhất với i.
- C là tập tất cả các sản phẩm tương tự các sản phẩm trong Ia.
- Loại bỏ các sản phẩm Ia trong C.
- Tính độ tương tự giữa các sản phẩm trong C vơí tập sản phẩm Ia.
- Xếp hạng C giảm dần theo mức độ tương tự nói trên.
- Lấy top N sản phầm từ C theo thứ tự giảm dần của độ tương tự, sau đó tư vấn cho người dùng a.
1.5 Lọc cộng tác dựa trên mô hình (model-based CF)
- Thực hiện tư vấn dựa trên các mô hình học máy.
- Các mô hình được xây dựng dựa trên dữ liệu huấn luyện.
- Các phương pháp để xây dựng mô hình lọc cộng tác thường dùng:
- Bayesian models
- Clustering model
2. Content-based (dựa trên nội dung)
- Các phương pháp lọc cộng tác chỉ dựa trên tương tác của người dùng, thì các phương pháp dựa trên nội dung sử dụng thông tin bổ sung (features) về người dùng và sản phẩm.
Ví dụ về hệ thống gợi ý phim: Thông tin bổ sung (features) có thể là: độ tuổi, giới tính, công việc của người dùng, thể loại, diễn viên chính, thời lượng của bộ phim. - Sau đó, ý tưởng của phương pháp dựa trên nội dung là cố gắng xây dựng một mô hình dựa trên các thông tin bổ sung. Ví dụ chúng ta xây dựng được mô hình thực tế chỉ ra rằng phụ nữ có xu hướng đánh giá tốt một số phim, nam giới trẻ tuổi lại có xu hướng đánh giá tốt một số phim khác,...
- Nếu xây dựng được mô hình như vậy, thì việc dự đoán cho người dùng mới rất dễ dàng: chúng ta chỉ cần xem xét hồ sơ (tuổi, giới tính,..) của người dùng và dựa trên những thông tin này để đề xuất phim.
Kiến trúc chung của hệ tư vấn dựa trên nội dung
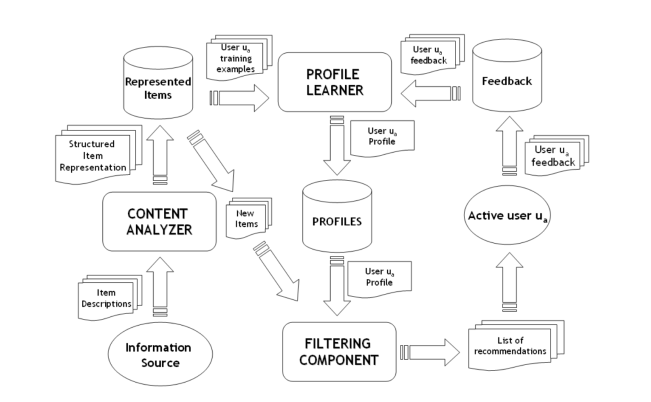
Các thành phần chính
- Content Analyzer
- Phân tích và trích chọn thông tin, nội dung từ các sản phẩm
- Biểu diễn thông tin vừa trích chọn được theo một cấu trúc nào đó
- User profiles
- Cơ sở dữ liệu chứa thông tin, sở thích của người dùng (nhân khẩu học, sở thích, ý định, ...)
- Profile Learner
- Cập nhật profile user dựa trên hành vi của họ
- Các hành vi như một dạng thông tin phản hồi (feedback) từ người dùng
- Các hành vi như: Đọc, xem, thích, đánh giá, chia sẻ, mua, tìm kiếm, ...
- Filter Component
- Bộ lọc thực hiện tư vấn
- Đối sánh nội dung sản phẩm với hồ sơ người dùng.
- Xếp hạng các sản phẩm theo mức độ tương đồng với người dùng.
Phân loại phương pháp content-based
Trong các phương pháp dựa trên nội dung, vấn đề được đưa vào phân lớp (dự đoán xem người dùng thích hay không thích một mặt hàng) hoặc vấn đề hồi quy (dự đoán mức độ đánh giá mà người dùng đưa ra cho một mặt hàng). Trong cả hai trường hợp, chúng ta sẽ thiết lập một mô hình sẽ dựa trên các đặc điểm của người dùng hoặc sản phẩm theo ý của chúng ta.
- Item-centred
- Nếu việc phân lớp (hoặc phân cụm) dựa trên các đặc điểm của người dùng (users features), việc mô hình hóa, tối ưu hóa và tính toán được thực hiện trên sản phẩm.
- Xây dựng và tìm hiểu một mô hình theo item-based trên users features cố gắng trả lời câu hỏi, "Xác suất của mỗi người dùng thích mặt hàng này là bao nhiêu?" (Hoặc Mức đánh giá của mỗi người dùng về sản phẩm là bao nhiêu?). Mô hình xây dựng theo phương pháp này ít cá nhân hóa so với phương pháp lấy người dùng làm trung tâm.
- Nếu việc phân lớp (hoặc phân cụm) dựa trên các đặc điểm của người dùng (users features), việc mô hình hóa, tối ưu hóa và tính toán được thực hiện trên sản phẩm.
- User centred
- Nếu chúng ta đang làm việc với các đặc điểm của sản phẩm, việc đào tạo mô hình hóa, tối ưu hóa và tính toán có thể được thực hiện dựa trên người dùng.
- Mô hình theo user based trên items features cố gắng trả lời câu hỏi. "Xác suất người dùng này thích từng mặt hàng là bao nhiêu?" (Hay mức đánh giá mà người dùng này đưa ra cho mỗi mặt hàng là gì? ).
- Sau đó, chúng ta có thể đính kèm một mô hình cho mỗi người dùng được đào tạo về dữ liệu của mình do đó mô hình được cá nhân hóa hơn so với phương pháp trung vào item vì nó chỉ tính đến các tương tác từ người dùng được xem xét. Tuy nhiên, người dùng tương tác với tương đối ít sản phẩm và do đó, mô hình chúng ta thu được sẽ kém mạnh mẽ hơn so với mô hình tập trung vào sản phẩm.
Item-centred Bayesian classifier
Đối với mỗi sản phẩm chúng ta muốn đào tạo một phân lớp Bayesian dựa vào những đặc điểm của người dùng là đầu vào và đầu ra là "like" hoặc "dislike". Như vậy chúng ta cần tính:
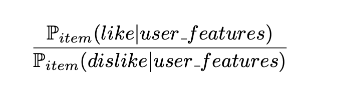
Tỉ lệ xác xuất người dùng có các đặc điểm nhất định thích sản phẩm trên xác xuất người không thích nó. Có thể tính theo công thức Bayes như sau:

User-centred linear regression
Đối với mỗi người dùng, chúng ta cần đào tạo một mô hình hồi quy tuyến tính đơn giản, lấy các đặc điểm của sản phẩm làm đầu vào và đầu ra là mức xếp hạng của người dùng cho sản phẩm này. Chúng ta vẫn biểu thị ma trận tương tác item-user M, sau đó xếp chồng vào ma trận một vecto ma trận hàng X đại diện cho các hệ số người dùng sẽ học và xếp chồng vào một vectơ ma trận Y đại diện cho các đặc điểm của sản phẩm được đưa ra. Sau đó, đối với người dùng i đã cho, chúng tôi tìm hiểu các hệ số trong X_i bằng cách giải quyết vấn đề sau:
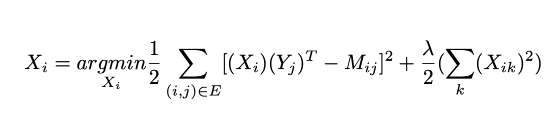
Trong đó i cố định vì vậy, tổng đầu tiên chỉ là các cặp (user, item) liên quan đến người dùng i. Chúng ta có thể thấy rằng nếu chúng ta giải quyết vấn đề này cho tất cả người dùng cùng một lúc, thì vấn đề tối ưu hóa hoàn toàn giống với vấn đề “alternated matrix factorisation” khi các item cố định.
Ưu điểm
- Đảm bảo tính độc lập giữa các người dùng
- Dễ hiểu
- Giải quyết phần lớn vấn đề xuất phát nguội (người dùng mới, sản phẩm mới)
Nhược điểm
- Phải phân tích và trích chọn nội dung sản phẩm
- Có thể tạo lối mòn (over-specification, serendipity)
- Tư vấn các sản phẩn quen thuộc
- Khó tư vấn các sản phẩm mới vẻ hay bất thường
- Vẫn khó khăn trong khi tư vấn cho người dùng mới.
3. Hybrid approach (các phương pháp lai)
Các phương pháp này là sự kết hợp các phương pháp tiếp cận dựa trên nội dung và lọc cộng tác, chúng cho kết quả tốt trong nhiều trường hợp và do đó, được sử dụng trong nhiều hệ thống đề xuất quy mô lớn hiện nay. Sự kết hợp được thực hiện trong các phương pháp lai có thể chủ yếu có hai dạng:
- Huấn luyện hai mô hình một cách độc lập (một mô hình lọc cộng tác và một mô hình dựa trên nội dung) và kết hợp các đề xuất của chúng
- Trực tiếp xây dựng một mô hình để thống nhất cả hai cách tiếp cận bằng cách sử dụng làm thông tin trước khi nhập (về người dùng và / hoặc vật phẩm) cũng như thông tin tương tác của cộng tác trực tuyến.
Bài viết tham khảo từ giáo trình của thầy Phan Xuân Hiếu - giảng viên trường đại học Công Nghệ và bài viết Introduction to recomment systems của tác giả Baptiste Rocca
All rights reserved
