Inpaint Anything - Công cụ chỉnh sửa ảnh bằng cách kết hợp SAM với Stable Diffusion
Bài đăng này đã không được cập nhật trong 2 năm
Mở đầu
Inpaint Anything được giới thiệu trong bài báo Inpaint Anything: Segment Anything Meets Image Inpainting (Yu et al., 2023) vào tháng 4 năm 2023 bởi các nhóm nguyên cứu đến từ trường Đại học Khoa học và Công nghệ Trung Quốc. Inpaint Anything được đề xuất với mục đích đơn giản hoá tác vụ inpaint ảnh bằng việc "clicking and filling" (click chọn vật thể và lấp đầy) mà vẫn đảm bảo độ chính xác một cách tương đối. Bằng việc ứng dụng khả năng segment vật thể bằng cách click chọn của SAM, khả năng xóa vật thể trong ảnh sử dụng segmentation mask của LaMa và khả năng sinh ảnh bằng prompt của Stable Diffusion, Inpaint Anything có thể thực hiện 3 tác vụ chính đó là Remove Anything (xoá vật thể và lấp đầy ảnh bằng background), Fill Anything (xoá vật thể và lấp đầy ảnh bằng vật thể khác) và Replace Anything (giữ nguyên vật thể, xoá background và lấp đầy ảnh bằng background khác). Bài viết sau đây sẽ đi vào chi tiết hơn về mô hình này.
| Remove Anything | Fill Anything | Replace Anything |
|---|---|---|
 |
 |
 |
| Prompt: "" | Prompt: "a teddy bear on a bench" | Prompt: "a man in office" |
Tổng quan về SAM
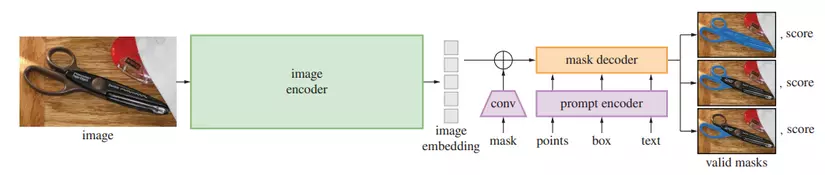
SAM (Segment Anything Model) được giới thiệu trong bài báo Segment Anything là một mô hình có khả năng segment vật thể trong ảnh sử dụng prompt, hay nói cách khác là chỉ bằng việc click chọn một vài điểm bất kỳ của vật thể trong bức ảnh là mô hình có thể trả về một mask khá là sát với vật thể. Ngoài ra, prompt ở đây còn bao gồm cả việc vẽ bounding boxes quanh vật thể hay thậm chí là đoạn văn bản mô tả vật thể cần segment trong ảnh. Để làm được điều này thì SAM tiến hành nén ảnh thành embedding thông qua masked auto-encoder (MAE) pre-trained Vision Transformer (ViT) trong phần Image Encoder, nén prompt thông qua phần Prompt Encoder (point, box → positional encodings, mask → embedding thông qua tích chập, text → embedding thông qua CLIP) rồi cộng từng phần tử lại với nhau, sau đó cho chúng qua phần Mask Decoder để tiến hành giải nén để ra mask của vật thể. Ngoài ra, do một điểm click chọn có thể ám chỉ tay cầm của kéo hoặc thậm chí là cả cái kéo như ở trong hình 2 nên để tăng độ chính xác thì SAM sẽ trả về nhiều mask khác nhau đối với mỗi một prompt (3 masks cho từng prompt là khá đủ trong đa số trường hợp). Ngoài ra, nếu các bạn có mong muốn tìm hiểu sâu hơn về mô hình này thì có thể truy cập vào bài viết này do mình tổng hợp liên quan tới SAM.
Tổng quan về LaMa
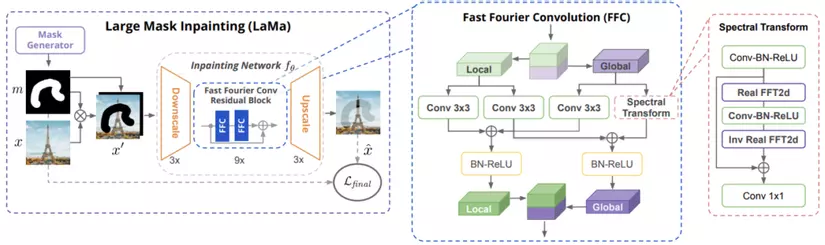
LaMa (Large Mask Inpainting) được giới thiệu trong bài báo Resolution-robust Large Mask Inpainting with Fourier Convolutions (Suvorov et al., 2021) là một mô hình có khả năng xóa vật thể trong ảnh sử dụng segmentation mask mà ảnh vẫn có thể trông tự nhiên sau khi xóa và không tốn nhiều chi phí tính toán. Khi áp dụng trên ảnh có kích thước lớn thì mô hình này đạt kết quả tốt hơn hẳn với so với rất nhiều các phương pháp trước đó do các phương pháp này chỉ tập trung cải thiện kết quả trên các ảnh có kích thước nhỏ. Và sở dĩ LaMa có thể làm được điều này là nhờ vào việc sử dụng FFC (Fast Fourier Convolution) trong kiến trúc mô hình, hàm mất mát Perceptual Loss, và chiến lược sinh mask để huấn luyện mô hình (aggressive training mask generation strategy). FFC bao gồm hai nhánh, một nhánh sử dụng tích chập thông thường để học local context và nhánh còn lại dùng FFT (Fast Fourier Transform) để học global context. Perceptual loss được sử dụng để đánh giá khoảng cách giữa features được trích xuất từ ảnh dự đoán và ảnh mục tiêu thông qua một mạng được pretrain. Hàm mất mát này không yêu cầu kết quả dự đoán phải chính xác tuyệt đối như các hàm mất mát quen thuộc khác trong bài toán học giám sát, và điều này cho phép sự đa dạng trong kết quả trả về của mô hình. Còn về chiến lược huấn luyện thì mask được sinh ra với nhiều cách biến đổi khác nhau như dilation với trọng số ngẫu nhiên (wide masks), chuyển mask thành box (box masks) và việc này giúp cho dữ liệu huấn luyện trở nên đa dạng hơn, từ đó cải thiện kết quả mô hình.
Tổng quan về Stable Diffusion
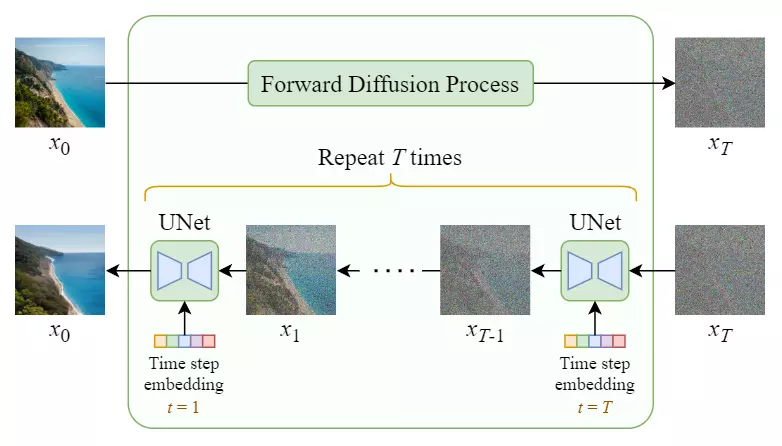
Trước khi đi vào Stable Diffusion thì trước hết không thể không nhắc tới mô hình diffusion đầu tiên. Mô hình này hoạt động bằng cách ứng dụng Unet khử nhiễu lặp đi lặp lại nhiều lần để tạo ra ảnh thực từ nhiễu. Unet được đề xuất trong bài báo U-Net: Convolutional Networks for Biomedical Image Segmentation (Ronneberger et al., 2015) với vai trò là mô hình dùng cho bài toán segmentation được ứng dụng rộng rãi với kết quả mà mô hình này đạt được, và khử nhiễu là một cách ứng dụng khác cho mô hình này. Quá trình huấn luyện của mô hình diffusion bao gồm hai giai đoạn:
- Forward Diffusion Process: thêm Gaussian noise vào trong ảnh qua từng bước một để tạo tập dữ liệu dành cho việc huấn luyện mô hình.
- Reverse Diffusion Process: khử nhiễu từ ảnh từng bước một, đây chính là giai đoạn mà mô hình diffusion sẽ tìm cách học để đảo ngược quá trình thêm nhiễu vào trong ảnh, từ đó có thể tạo ra ảnh thực từ nhiễu.
Kết quả mà mô hình diffusion đạt được không thua kém gì so các generative models như GAN, VAE, với một nhược điểm dễ thấy đó là mô hình tương đối chậm bởi mô hình này phải được dùng lặp đi lặp lại nhiều lần để ra kết quả cuối cùng, nhất là khi số lần mô hình này được dùng và kích thước bức ảnh là tương đối lớn.
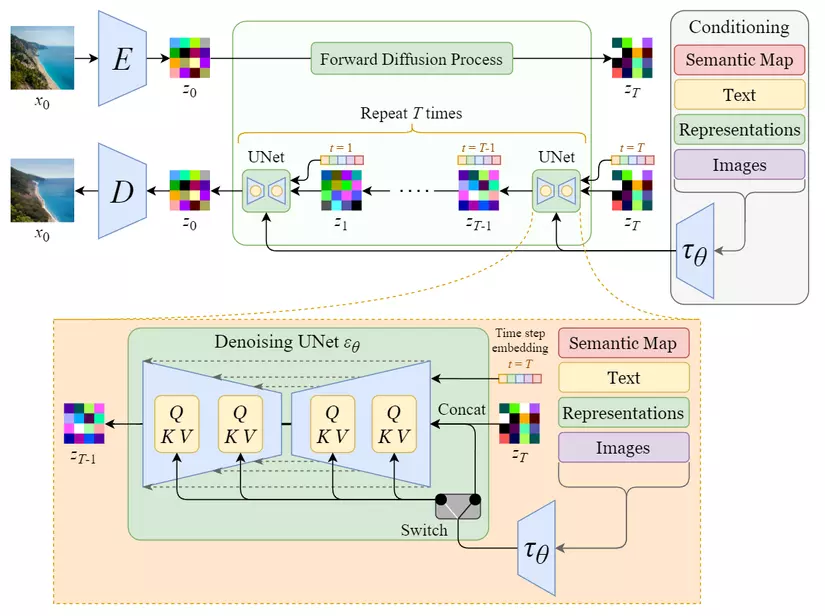
Stable Diffusion (Latent Diffusion Model) được giới thiệu trong bài báo High-Resolution Image Synthesis with Latent Diffusion Models (Rombach et al., 2022) và đạt kết quả tương đối tốt trên nhiều tác vụ khác nhau như unconditional image generation (sinh ảnh không điều kiện), semantic scene synthesis (sinh ảnh từ segmentation mask), and super-resolution (tăng độ phân giải cho ảnh), trong khi chạy nhanh hơn và cần ít tài nguyên tính toán hơn so với mô hình diffusion gốc. Để làm được điều đó thì Stable Diffusion sử dụng phần encoder của một autoencoder để nén ảnh dưới dạng lower-dimensional representations (biểu diễn ít chiều hơn) hay latent data (dữ liệu ẩn), rồi cho qua quá trình tương tự như ảnh trong mô hình diffusion gốc, sau đó sử dụng phần decoder của autoencoder để giải nén latent data trở về ảnh. Ngoài ra, Stable Diffusion còn cho phép sinh ảnh từ text prompts (đoạn văn mô tả) bằng cách chuyển chúng thành text embeddings thông qua việc sử dụng mô hình ngôn ngữ (ví dụ như BERT, CLIP) rồi đưa chúng vào trong Unet thông qua multihead attention layer. Tóm lại thì Stable Diffusion là một mô hình thuộc dạng AIGC (Artificial Intelligence Generated Content) tương tự như ChatGPT trong việc sáng tạo nội dung dựa trên prompt từ người dùng.
Kiến trúc mô hình Inpaint Anything
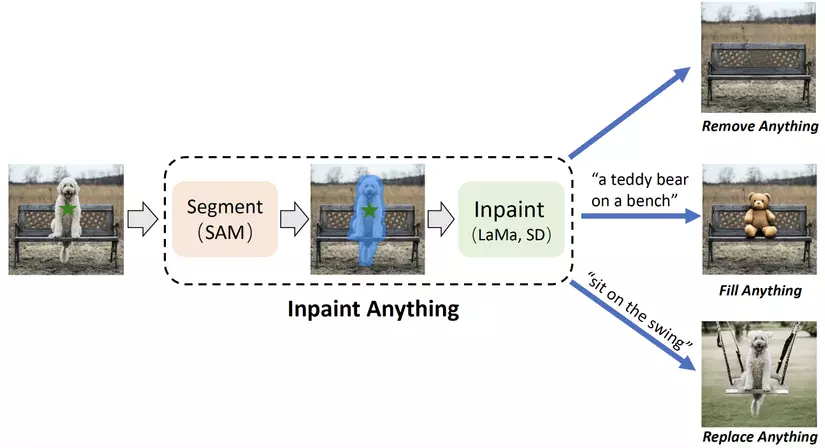
Để nói về cách Inpaint Anything hoạt động thì đầu tiên là người dùng sẽ tiến hành click chọn một điểm trên vật thể trong ảnh, sau đó vị tríểm này cùng với ảnh sẽ cho qua SAM để ra segmentation mask cho vật thể. Sau đó tùy vào từng tác vụ sẽ có cách xử lý khác nhau:
- Remove Anything: để xóa vật thể trong ảnh thì ảnh và segmentation mask của vật thể sẽ được cho qua LaMa để lấp đầy chỗ trống trong ảnh bằng background của ảnh được tạo ra sau khi xóa vật thể.
- Fill Anything: ở tác vụ này thì người dùng sẽ cung cấp text prompt mô tả thứ mà họ muốn lấp đầy chỗ vật thể bị xóa khỏi ảnh và Stable Diffusion sẽ sử dụng text prompt này để sinh ra vật thể mong muốn rồi lấp đầy chỗ bị xóa bằng vật thể đó.
- Replace Anything: tương tự như Fill Anything thì tác vụ này cũng yêu cầu người dùng cung cấp text prompt làm đầu vào cho Stable Diffusion, chỉ khác ở chỗ là text prompt sẽ mô tả background mới để lấp đầy phần background bị xóa.
Tuy nhiên, việc kết hợp các mô hình này lại với nhau sẽ phát sinh ra một số vấn đề như:
- Dilation matters: segmentation mask trả về từ SAM thường chứa ranh giới có phần dứt quãng, không được mượt, hay là chứa các cái lỗ bên trong vật thể, và điều này có thể làm ảnh hưởng không nhỏ đến kết quả trả về của các mô hình kế tiếp. Tuy nhiên, việc này hoàn toàn có thể được khắc phục bằng cách sử dụng toán tử dilation để làm segmentation mask của vật thể to hơn để hạn chế phần bị đứt quãng, có chứa lỗ, đồng thời việc này làm cho không gian cần lấp đầy nhiều lên giúp cho các mô hình kế tiếp dễ trả về kết quả phù hợp với người dùng hơn.
- Fidelity matters: Phần lớn các mô hình AIGC như Stable Diffusion thường yêu cầu ảnh phải có kích thước cố định, thường là 512 × 512. Tuy nhiên, thay đổi kích thước ảnh có thể gây biến dạng, mất tính chân thực, gây ảnh hưởng tiêu cực đến kết quả trả về. Để giải quyết điều này thì việc thay đổi kích thước ảnh sao cho bảo toàn được chất lượng ảnh ban đầu là hoàn toàn cần thiết, và điều này có thể được thực hiện bằng cách crop hoặc giữ nguyên độ tỉ lệ khung hình khi thay đổi kích thước.
- Prompt matters: Nội dung của text prompt có thể gây ảnh hưởng không nhỏ tới kết quả trả về và text prompt càng dài, càng phức tạp thì kết quả trả về càng ấn tượng, tuy nhiên việc này sẽ kém thân thiện với người dùng hơn là việc dùng những text prompt ngắn, đơn giản.
Kết quả



Tập test dùng để đánh giá kết quả của mô hình bao gồm tập test từ bộ dữ liệu COCO, tập test để đánh giá kết quả mô hình LaMa và ảnh chụp từ điện thoại của tác giả bài báo Inpaint Anything. Nhìn chung, Inpaint Anything cho kết quả tương đối tốt với đa dạng về mặt nội dung, kích thước và tỉ lệ khung hình của ảnh.
Kết luận
Tổng kết lại thì Inpaint Anything là mô hình cho phép inpaint ảnh chỉ bằng việc click chọn vật thể trong ảnh thay vì phải vẽ mask như các mô hình SOTA trước đó như LaMa. Để làm được điều này thì Inpaint Anything tích hợp SAM trong việc trích xuất mask của vật thể từ điểm click chọn, LaMa trong việc dùng mask xóa vật thể và lấp đầy chỗ xóa bằng background, Stable Diffusion trong việc sử dụng prompt thay thế vật thể hoặc background trong ảnh bằng vật thể hay background khác tương ứng. Với việc inpaint ảnh chỉ bằng cách click chọn vật thể trong ảnh thì trong tương lai, Inpaint Anything hoàn toàn có thể thay thế cho các công cụ chỉnh sửa ảnh hiện tại trong lĩnh vực Image Inpainting.
Tham khảo
- Inpaint Anything paper (https://arxiv.org/pdf/2304.06790.pdf)
- Inpaint Anything code (https://github.com/geekyutao/Inpaint-Anything)
All rights reserved
