Ingestion and Processing of Data For Big Data and IoT Solutions
Bài đăng này đã không được cập nhật trong 4 năm
Overview
In the era of the Internet of Things and Mobility, with a huge volume of data becoming available at a fast velocity, there must be the need for an efficient Analytics System.
Also, the variety of data is coming from various sources in different formats, such as sensors, logs, structured data from an RDBMS, etc. In the past few years, the generation of new data has drastically increased. More applications are being built, and they are generating more data at a faster rate.
Earlier, Data Storage was costly, and there was an absence of technology which could process the data in an efficient manner. Now the storage costs have become cheaper, and the availability of technology to transform Big Data is a reality.
What is Big Data Concept?
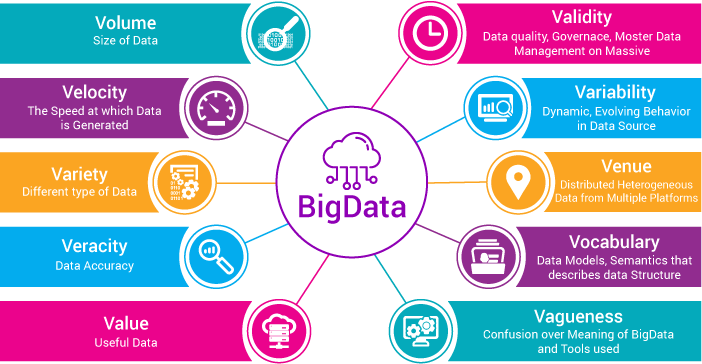
According to the Author Dr Kirk Borne, Principal Data Scientist, Big Data Definition is Everything, Quantified, and Tracked. Let’s pick that apart -
• Everything – Means every aspect of life, work, consumerism, entertainment, and play is now recognized as a source of digital information about you, your world, and anything else we may encounter.
• Quantified – Means we are storing those "everything” somewhere, mostly in digital form, often as numbers, but not always in such formats. The quantification of features, characteristics, patterns, and trends in all things is enabling Data Mining, Machine Learning, statistics, and discovery at an unprecedented scale on an unprecedented number of things. The Internet of Things is just one example, but the Internet of Everything is even more impressive.
• Tracked – Means we don’t directly quantify and measure everything just once, but we do so continuously. It includes - tracking your sentiment, your web clicks, your purchase logs, your geolocation, your social media history, etc. or tracking every car on the road, or every motor in a manufacturing plant or every moving part on an aeroplane, etc. Consequently, we see the emergence of smart cities, smart highways, personalized medicine, personalized education, precision farming, and so much more.
Advantages of Streaming Data
• Smarter Decisions • Better Products • Deeper Insights • Greater Knowledge • Optimal Solutions • Customer-Centric Products • Increased Customer Loyalty • More Automated Processes, more accurate Predictive and Prescriptive Analytics • Better models of future behaviours and outcomes in Business, Government, Security, Science, Healthcare, Education, and more.
D2D Communication Meets Big Data
• Data-to-Decisions • Data-to-Discovery • Data-to-Dollars
10 Vs of Big Data
Big Data Architecture & Patterns
The Best Way to a solution is to "Split The Problem." Big Data Solution can be well understood using Layered Architecture. The Layered Architecture is divided into different Layers where each layer performs a particular function.
This Architecture helps in designing the Data Pipeline with the various requirements of either Batch Processing System or Stream Processing System.
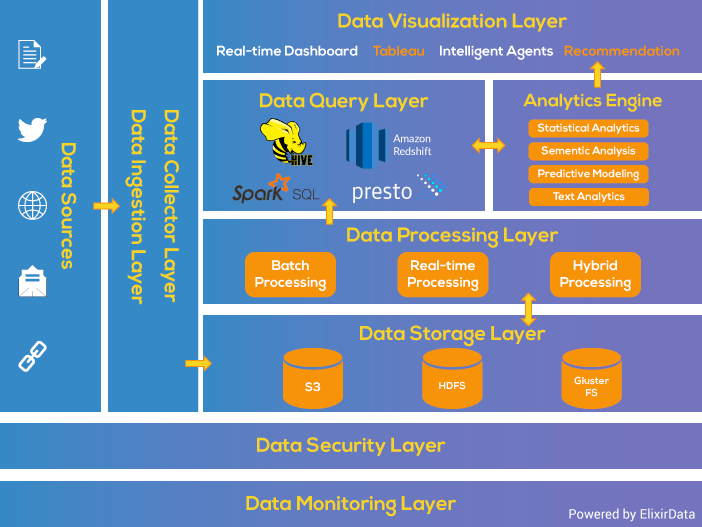
• Data Ingestion Layer
his layer is the first step for the data coming from variable sources to start its journey. Data here is prioritized and categorized which makes data flow smoothly in further layers
• Data Collector Layer
In this Layer, more focus is on the transportation of data from ingestion layer to rest of data pipeline. It is the Layer, where components are decoupled so that analytic capabilities may begin.
• Data Processing Layer
Here we do some magic with the data to route them to a different destination, classify the data flow and it’s the first point where the analytic may take place.
• Data Storage Layer
Storage becomes a challenge when the size of the data you are dealing with, becomes large. Several possible solutions can rescue from such problems. Finding a storage solution is very much important when the size of your data becomes large. This layer focuses on "where to store such a large data efficiently."
• Data Query Layer
This is the layer where active analytic processing takes place. Here, the primary focus is to gather the data value so that they are made to be more helpful for the next layer.
• Data Visualization Layer
The visualization, or presentation tier, probably the most prestigious tier, where the data pipeline users may feel the VALUE of DATA. We need something that will grab people’s attention, pull them into, make your findings well-understood.
1. Data Ingestion Architecture

Data ingestion is the first step for building Data Pipeline and also the toughest task in the System of Big Data. In this layer we plan the way to ingest data flows from hundreds or thousands of sources into Data Center. As the Data is coming from Multiple sources at variable speed, in different formats.
That's why we should properly ingest the data for the successful business decisions making. It's rightly said that "If starting goes well, then, half of the work is already done."
What is Ingestion in Big Data?
It's about moving data - and especially the unstructured data - from where it is originated, into a system where it can be stored and analyzed. We can also say that Data Ingestion means taking data coming from multiple sources and putting it somewhere it can be accessed.
As the number of IoT devices increases, both the volume and variance of Data Sources are expanding rapidly. So, extracting the data such that it can be used by the destination system is a significant challenge regarding time and resources. Some of the other problems faced by Data Ingestion are -
• When numerous Big Data sources exist in the different format, it's the biggest challenge for the business to ingest data at the reasonable speed and further process it efficiently so that data can be prioritized and improves business decisions. • Modern Data Sources and consuming application evolve rapidly. • Data produced changes without notice independent of consuming application. • Data Semantic Change over time as same Data Powers new cases. • Detection and capture of changed data - This task is difficult, not only because of the semi-structured or unstructured nature of data but also due to the low latency needed by individual business scenarios that require this determination.
That's why it should be well designed assuring following things -
• Able to handle and upgrade the new data sources, technology and applications • Assure that consuming application is working with correct, consistent and trustworthy data. • Allows rapid consumption of data • Capacity and reliability - The system needs to scale according to input coming and also it should be fault tolerant. • Data volume - Though storing all incoming data is preferable; there are some cases in which aggregate data is stored.
Data Ingestion Parameters
• Data Velocity - Data Velocity deals with the speed at which data flows in from different sources like machines, networks, human interaction, media sites, social media. The movement of data can be massive or continuous. • Data Size - Data size implies enormous volume of data. Data is generated by different sources that may increase timely. • Data Frequency (Batch, Real-Time) - Data can be processed in real time or batch, in real time processing as data received on same time, it further proceeds but in batch time data is stored in batches, fixed at some time interval and then further moved. • Data Format (Structured, Semi-Structured, Unstructured) - Data can be in different formats, mostly it can be the structured format, i.e., tabular one or unstructured format, i.e., images, audios, videos or semi-structured, i.e., JSON files, CSS files, etc.
Big Data Ingestion Key Principles
To complete the process of Data Ingestion, we should use right tools for that and most important that tools should be capable of supporting some of the fundamental principles written below
Read The Full Article:XenonStack/Blog
All rights reserved
