Hướng dẫn làm chatbot đơn giản
Bài đăng này đã không được cập nhật trong 6 năm
Mở đầu
Nhân một ngày đẹp trời, tôi ngồi đây viết một bài hướng dẫn làm một con chatbot đơn giản, nói không với framework chatbot như Rasa  . Con bot này tôi sẽ code theo hướng NLU, tức là no stories, no dialogue memory, no slotfilling, no action, bla bla ...
. Con bot này tôi sẽ code theo hướng NLU, tức là no stories, no dialogue memory, no slotfilling, no action, bla bla ...
Ngôn ngữ: Python Hệ điều hành: Ubuntu 16.04 Kỹ thuật: Database, Intent Classification
Database
DB: Postgres
Để tiện code và run sản phẩm, tôi có tạo 1 file shell auto chạy các lệnh cài đặt run.sh as below:
#!/bin/bash
sudo apt-get update -y
sudo apt-get install -y software-properties-common
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt-get update -y
sudo apt-get install -y build-essential python3.6 python3.6-dev python3-pip libpq-dev \
postgresql postgresql-contrib python-virtualenv -y
virtualenv -p /usr/bin/python3.6 funnybot_env
source funnybot_env/bin/activate
python3.6 -m3 pip install pip --upgrade
python3.6 -m pip install wheel
pip3 install -r requirements.txt
File requirements.txt chứa các packages của python, trc hết cài postgres đã:
psycopg2>=2.7,<3.0
Để chạy file run.sh bạn dùng lệnh này sh run.sh
Sau khi cài xong, bạn tạo 1 database, ờ thì tôi cũng viết thêm 1 file shell cho tiện cài 
create_db.sh:
#!/bin/bash
#tạo db
sudo -u postgres psql postgres -c "CREATE DATABASE funnybot WITH ENCODING 'UTF8';"
#tạo user và password
sudo -u postgres psql postgres -c "CREATE USER bot_owner WITH PASSWORD '123456';"
#config role
sudo -u postgres psql postgres -c "ALTER ROLE bot_owner SET client_encoding TO 'utf8';"
sudo -u postgres psql postgres -c "ALTER ROLE bot_owner SET default_transaction_isolation TO 'read committed';"
sudo -u postgres psql postgres -c "ALTER ROLE bot_owner SET timezone TO 'UTC';"
#độ ưu tiên
sudo -u postgres psql postgres -c "GRANT ALL PRIVILEGES ON DATABASE funnybot TO bot_owner;"
Sau khi tạo xong db, bạn tạo 1 function kết nối với db funnybot:
import psycopg2
def connect_db():
conn = None
try:
#kết nối db dùng thư viện psycopg2
conn = psycopg2.connect(host="localhost", database="funnybot", user="bot_owner", password="123456")
#khai báo con trỏ
cur = conn.cursor()
return conn, cur
except (Exception, psycopg2.DatabaseError) as error:
print(error)
Sau khi kết nối với db funnybot xong, bạn tạo table:
def create_tables():
commands = [
""" CREATE TABLE bot (
bot_id SERIAL PRIMARY KEY,
bot_name VARCHAR(255) NOT NULL
);
""",
""" CREATE TABLE intents (
intent_id SERIAL PRIMARY KEY,
intent_name VARCHAR(255) NOT NULL
);
""",
""" CREATE TABLE intents_bot (
intent_id int REFERENCES intents (intent_id) ON UPDATE CASCADE,
bot_id int REFERENCES bot (bot_id) ON UPDATE CASCADE,
CONSTRAINT intent_bot_pkey PRIMARY KEY (intent_id, bot_id)
);
""",
""" CREATE TABLE training_data (
training_data_id SERIAL PRIMARY KEY,
intent_id int NOT NULL REFERENCES intents (intent_id),
content VARCHAR(255) NOT NULL
);
""",
""" CREATE TABLE response_data (
response_data_id SERIAL PRIMARY KEY,
intent_id int NOT NULL REFERENCES intents (intent_id),
answer VARCHAR(255) NOT NULL
);
"""
]
conn, cur = connect_db()
for command in commands:
cur.execute(command)
cur.close()
conn.commit()
if __name__ == '__main__':
create_tables()
Thêm tí dữ liệu vào table:
- Thêm bot
def insert_bot_data():
sql = "INSERT INTO bot(bot_name) VALUES(%s)"
conn, cur = connect_db()
cur.execute(sql, ("funnybot",))
conn.commit()
cur.close()
- Thêm intents
def insert_intents_data():
sql = "INSERT INTO intents(intent_name) VALUES(%s)"
conn, cur = connect_db()
cur.executemany(sql, [('chào hỏi',), ('tạm biệt',), ('xin lỗi',), ('cảm ơn',)])
conn.commit()
cur.close()
- Thêm dữ liệu training cho intents
def insert_training_data():
sql = "INSERT INTO training_data(intent_id, content) VALUES(%s, %s)"
conn, cur = connect_db()
data = [
(1, 'chào bạn',), (1, 'chào anh',), (1, 'em chào anh',), (1, 'chào chị',), (1, 'chào đằng ấy',), (1, 'hello',),
(2, 'tạm biệt',), (2, 'tạm biệt anh',), (2, 'hẹn gặp lại',), (2, 'lần sau gặp lại',), (2, 'goodbye',),
(3, 'xin lỗi',), (3, 'xin lỗi bạn',), (3, 'xin lỗi anh',), (3, 'thật có lỗi',), (3, 'em rất xin lỗi',),
(4, 'cảm ơn',), (4, 'cảm ơn bạn',), (4, 'cảm ơn anh',), (4, 'cảm ơn rất nhiều',), (4, 'em rất biết ơn anh',), (4, 'em cảm ơn anh',)
]
cur.executemany(sql, data)
conn.commit()
cur.close()
- Thêm câu trả lời
def insert_response_data():
sql = "INSERT INTO response_data(intent_id, answer) VALUES(%s, %s)"
conn, cur = connect_db()
data = [(1, 'chào anh/chị',), (2, 'chúc anh chị một ngày tốt lành',), (3, 'xin lỗi anh/chị'), (4, 'cảm ơn anh/chị')]
iệu
cur.executemany(sql, data)
conn.commit()
cur.close()
Chắc các bạn cảm thấy có tí ti dữ liệu thế này thì cần gì DB, nhưng không khi làm một dự án thực tế, các bạn sẽ gặp rất nhiều vấn đề về dữ liệu: số lượng dữ liệu lớn, tính bảo mật của dữ liệu, dung lượng lưu trữ dữ liệu, dữ liệu có cấu trúc, truy xuất dữ liệu, bla bla ... Không phải chỉ cần import một file csv là được  . Ok hơi bị lan man, sau khi có dữ liệu ta cần xử lý nó để đưa vào model của Machine Learning nhằm phân loại Intent của người dùng
. Ok hơi bị lan man, sau khi có dữ liệu ta cần xử lý nó để đưa vào model của Machine Learning nhằm phân loại Intent của người dùng
Intent Classification
Xin các bạn thông cảm tôi không hướng dẫn cách lấy data từ db postgres do bài viết sẽ bị loãng và dài. Nói chung nếu bạn muốn truy xuất dữ liệu thì đổi câu lệnh sql thành
SELECT * FROM table_name; là được.
Import package cần, ở đây tôi sử dụng mô hình xác suất MultinomialNB và kỹ thuật biến text thành vector (Bag of words, TFIDF) của scikit-learn
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
import numpy as np
Chuẩn bị dữ liệu
training_data = [
(1, 'chào bạn'), (1, 'chào anh'), (1, 'em chào anh'), (1, 'chào chị'), (1, 'chào đằng ấy'), (1, 'hello'),
(2, 'tạm biệt'), (2, 'tạm biệt anh'), (2, 'hẹn gặp lại'), (2, 'lần sau gặp lại'), (2, 'goodbye'),
(3, 'xin lỗi'), (3, 'xin lỗi bạn'), (3, 'xin lỗi anh'), (3, 'thật có lỗi'), (3, 'em rất xin lỗi'),
(4, 'cảm ơn'), (4, 'cảm ơn bạn'), (4, 'cảm ơn anh'), (4, 'cảm ơn rất nhiều'), (4, 'em rất biết ơn anh'), (4, 'em cảm ơn anh')
]
response_data = [
(1, 'chào anh/chị'),
(2, 'chúc anh chị một ngày tốt lành'),
(3, 'xin lỗi anh/chị'),
(4, 'cảm ơn anh/chị')
]
Sau khi đã chuẩn bị xong dữ liệu thô bên trên, chúng ta chia tập train test
def convert_to_x_y(data):
X = []
y = []
for d in data:
X.append(d[1])
y.append([d[0]])
X = np.array(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
return X_train, y_train
Ở đây tôi dùng module Pipeline của sklearn để đơn giản hóa cũng như gói gọn quá trình tiền xử lý và define model. model chỉ cần fit dữ liệu => dữ liệu sẽ đi qua pipeline. Train xong thì predict thôi, thêm vài bước xử lý logic nữa
def mapping_response(intent):
for r in response_data:
if r[0] == intent[0]:
return r[1]
def train_and_predict(msg):
X_train, y_train = convert_to_x_y(training_data)
clf = Pipeline([
('vectorizer', CountVectorizer(ngram_range=(1, 2))),
('tfidf', TfidfTransformer()),
('clf', MultinomialNB())
])
clf.fit(X_train, np.ravel(y_train))
intent = clf.predict([msg])
answer = mapping_response(intent)
return answer
Kết quả
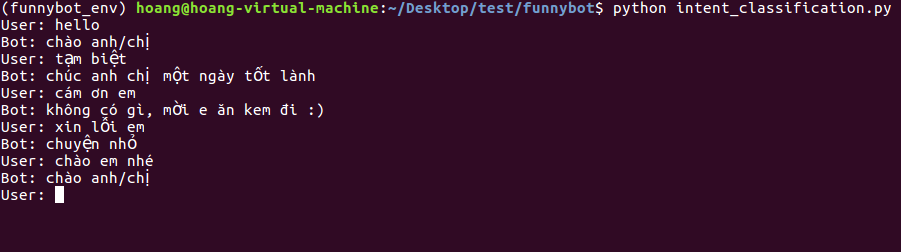
Kết
Thôi đến đây thôi, mình còn tính làm thêm cái Entity Extraction nhưng do bận việc quá nên tạm thời gác lại, có lẽ trong tương lai sẽ làm sau
Cám ơn các bạn đã xem bài viết này 
All rights reserved
