Hướng dẫn cài đặt Hive
Bài đăng này đã không được cập nhật trong 6 năm
Trong bài viết trước tôi đã giới thiệu với các bạn về Hive, và ở bài viết này chúng ta sẽ cùng nhau cài đặt Hive nhé
Tất cả các dự án con của Hadoop như Hive, Pig và HBase đều hỗ trợ hệ điều hành Linux. Do đó, bạn cần cài đặt bất kỳ HĐH Linux nào. Các bước được thực hiện để cài đặt Hive:
Bước 1: Xác minh cài đặt JAVA
Java phải được cài đặt trên hệ thống của bạn trước khi cài đặt Hive. Xác minh cài đặt java bằng lệnh sau:
$ java –version
Nếu Java đã được cài đặt trên hệ thống của bạn, bạn có thể thấy phản hồi sau:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Nếu java không được cài đặt trong hệ thống của bạn, thì hãy làm theo các bước dưới đây để cài đặt java.
Cài đặt Java
Step I
Tải xuống java (JDK <phiên bản mới nhất> - X64.tar.gz) bằng cách truy cập liên kết sau, VD http://www.oracle.com/technetwork/java/javase/doads/jdk7-doads-1880260.html.
Sau đó, jdk-7u71-linux-x64.tar.gz sẽ được tải xuống hệ thống của bạn.
Step II
Nói chung, bạn sẽ tìm thấy tệp java đã tải xuống trong thư mục Downloads. Xác minh nó và giải nén tệp jdk-7u71-linux-x64.gz bằng các lệnh sau.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gz
Step III
Để cung cấp java cho tất cả người dùng, bạn phải di chuyển nó đến vị trí "/usr/local/".Gõ các lệnh sau:
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit
Step IV
Để thiết lập các biến PATH và JAVA_HOME, hãy thêm các lệnh sau vào tệp ~/.bashrc.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/bin
Bây giờ áp dụng tất cả các thay đổi vào hệ thống đang chạy hiện tại.
$ source ~/.bashrc
Step V
Sử dụng các lệnh sau để cấu hình các lựa chọn thay thế java:
# alternatives --install /usr/bin/java/java/usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac/javac/usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar/jar/usr/local/java/bin/jar 2
# alternatives --set java/usr/local/java/bin/java
# alternatives --set javac/usr/local/java/bin/javac
# alternatives --set jar/usr/local/java/bin/jar
Bây giờ hãy xác minh cài đặt bằng lệnh java -version từ terminal như được giải thích ở trên.
Bước 2: Xác minh cài đặt Hadoop
Hadoop phải được cài đặt trên hệ thống của bạn trước khi cài đặt Hive. Hã xác minh cài đặt Hadoop bằng lệnh sau:
$ hadoop version
Nếu Hadoop không được cài đặt trên hệ thống của bạn, thì hãy tiến hành các bước sau:
Tải Hadoop
Tải xuống và trích xuất Hadoop 2.4.1 từ Apache Software Foundation bằng các lệnh sau.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exit
Cài đặt Hadoop trong chế độ Pseudo Distributed
Step I : Setting Hadoop
Bạn có thể đặt các biến môi trường Hadoop bằng cách nối thêm các lệnh sau vào tệp ~/.bashrc.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export
PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Bây giờ áp dụng tất cả các thay đổi vào hệ thống đang chạy hiện tại.
Step II : Configure Hadoop
Bạn có thể tìm thấy tất cả các tệp cấu hình Hadoop trong vị trí của “$HADOOP_HOME/etc/hadoop”. Bạn cần thực hiện các thay đổi phù hợp trong các tệp cấu hình đó theo cơ sở hạ tầng Hadoop của bạn.
$ cd $HADOOP_HOME/etc/hadoop
Để phát triển các chương trình Hadoop bằng java, bạn phải đặt lại các biến môi trường java trong tệp hadoop-env.sh bằng cách thay thế giá trị JAVA_HOME bằng vị trí của java trong hệ thống của bạn.
export JAVA_HOME=/usr/local/jdk1.7.0_71
Dưới đây là danh sách các tập tin mà bạn phải chỉnh sửa để cấu hình Hadoop.
core-site.xml
Tệp core-site.xml chứa thông tin như số cổng được sử dụng cho Hadoop instance, bộ nhớ được phân bổ cho hệ thống tệp, giới hạn bộ nhớ để lưu trữ dữ liệu và kích thước của bộ đệm Đọc/Ghi.
Mở core-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configure> và </ configure>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
Tệp hdfs-site.xml chứa thông tin như giá trị của dữ liệu sao chép, đường dẫn nút tên và đường dẫn nút dữ liệu của các hệ thống tệp cục bộ của bạn. Nó có nghĩa là nơi bạn muốn lưu trữ Hadoop infra.
Chúng ta hãy giả sử các dữ liệu sau đây:
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Mở tệp này và thêm các thuộc tính sau vào giữa các thẻ <configure>, </ configure> trong tệp này.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value >
</property>
</configuration>
Lưu ý: Trong tệp trên, tất cả các giá trị thuộc tính đều do người dùng xác định và bạn có thể thực hiện thay đổi theo cơ sở hạ tầng Hadoop của mình.
yarn-site.xml
Tập tin này được sử dụng để cấu hình yarn vào Hadoop. Mở tệp yarn-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configure>, </ configure> trong tệp này.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
Tệp này được sử dụng để chỉ định framework MapReduce mà chúng tôi đang sử dụng. Theo mặc định, Hadoop chứa một mẫu của tệp yarn-site.xml. Trước hết, bạn cần sao chép tệp từ mapred-site,xml.template sang tệp mapred-site.xml bằng lệnh sau.
$ cp mapred-site.xml.template mapred-site.xml
Mở tệp mapred-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configure>, </ configure> trong tệp này.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Xác minh cài đặt Hadoop
Step I : Name Node Setup
Set up the namenode sử dụng the command:
$ cd ~
$ hdfs namenode -format
KQ mong đợi :
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/
Step II : Kiểm tra Hadoop dfs
Start Hadoop với câu lệnh sau:
$ start-dfs.sh
Output sẽ có format như:
10/13/19 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
Step III : Kiểm tra Yarn Script
Start yarn:
$ start-yarn.sh
Output:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Step IV : Kiểm tra Hadoop trên browser
Cổng mặc định 50070 chúng ta sử sụng url sau để truy cập Hadoop:
http://localhost:50070/
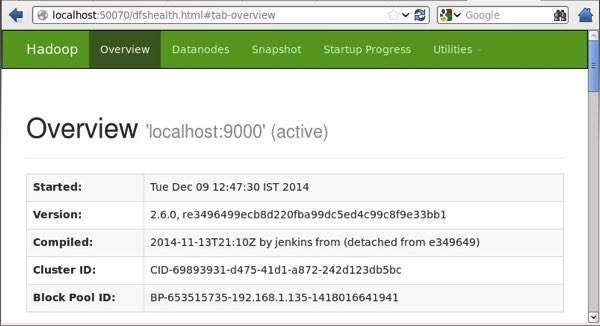
Bước 3: Download và install Hive
Chúng ta sẽ sử dụng hive-0.14.0 trong bài này, các bạn có thể tải file “apache-hive-0.14.0-bin.tar.gz” về tại đây
Giải nén file chúng ta vừa tải về:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz
Copy file giải nén đến thư mục /usr/local/hive:
$ su -
passwd:
# cd /home/user/Download
# mv apache-hive-0.14.0-bin /usr/local/hive
# exit
Cài đặt biến môi trường cho Hive
Để cài đặt biến môi trường chúng ta thêm vào cuối file ~/.bashrc:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
và thực hiện command:
$ source ~/.bashrc
Bước 4: Cấu hình Hive
Để cấu hình Hive với Hadoop, chúng ta cần chỉnh sửa một ít trong file hive-env.sh (được đạt trong $HIVE_HOME/conf). Trước tiên cần copy file này từ file mẫu của nó:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
Rồi thêm vào cuối file này:
export HADOOP_HOME=/usr/local/hadoop
Cài đặt Hive cơ bản là đã thành công, giờ đây chúng ta sẽ cần một external database để cấu hình Metastore. Chúng ta có một vài lựa chọn như dùng MySQL, PostgreSQL, ... Và ở trong bài này thì tôi sẽ sử dụng Apache Derby.
Bước 5: Download và install Apache Derby
Ta sẽ tải về và giải nén Derby với command:
$ cd ~
$ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz
Copy file vừa giải nén đến thư mục /usr/local/derby:
$ su -
passwd:
# cd /home/user
# mv db-derby-10.4.2.0-bin /usr/local/derby
# exit
Cài đặt biến môi trường cho Derby
Tương tự như Hive chúng ta thêm vào cuối file ~/.bashrc:
export DERBY_HOME=/usr/local/derby
export PATH=$PATH:$DERBY_HOME/bin
export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
Và chạy command:
$ source ~/.bashrc
Tạo thư mục để lưu Metastore
$ mkdir $DERBY_HOME/data
Bước 6: Cấu hình Metastore cho Hive
Metastore như là một kho trung tâm của Hive metadata, nó lưu trữ metadata cho các tables của Hive (như schema hay vị trí được lưu trữ). Chúng ta sẽ cấu hình nó ở trong file hive-site.xml. Đầu tiên copy file này ra từ file mẫu:
$ cd $HIVE_HOME/conf
$ cp hive-default.xml.template hive-site.xml
Dùng vim, nano, etc ... để edit file hive-site.xml. Thêm những dòng sau vào giữa thẻ <configuration> và </configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby://localhost:1527/metastore_db;create=true </value>
<description>JDBC connect string for a JDBC metastore </description>
</property>
Tạo một file được đặt tên jpox.properties và thêm những dòng sau:
javax.jdo.PersistenceManagerFactoryClass =
org.jpox.PersistenceManagerFactoryImpl
org.jpox.autoCreateSchema = false
org.jpox.validateTables = false
org.jpox.validateColumns = false
org.jpox.validateConstraints = false
org.jpox.storeManagerType = rdbms
org.jpox.autoCreateSchema = true
org.jpox.autoStartMechanismMode = checked
org.jpox.transactionIsolation = read_committed
javax.jdo.option.DetachAllOnCommit = true
javax.jdo.option.NontransactionalRead = true
javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver
javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true
javax.jdo.option.ConnectionUserName = APP
javax.jdo.option.ConnectionPassword = mine
Bước 7: Kiểm tra Hive
Trước khi start Hive, chúng ta phải tạo một thư mục /tmp và thư mục Hive riêng trong HDFS. Ở đây chúng ta sẽ tạo thư mục /user/hive/warehouse:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
Chúng ta sẽ kiểm tra việc cài đặt có hoàn tất không với command:
$ cd $HIVE_HOME
$ bin/hive
Nếu cài đặt thành công chúng ta sẽ có respond như:
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/hive-log4j.properties
Hive history file=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt
………………….
hive>
Chúng ta thử thực hiện show toàn bộ database trong HIve:
hive> show tables;
OK
Time taken: 2.798 seconds
hive>
Tham khảo
All rights reserved
