Hướng dẫn AWS Lambda + Bedrock BDA: Tự động xử lý tài liệu thông minh
Giới thiệu
Bài viết này hướng dẫn chi tiết cách xây dựng một serverless document processing pipeline sử dụng AWS Lambda và Amazon Bedrock Data Automation (BDA). Chúng ta sẽ tạo một hệ thống tự động xử lý tài liệu: khi upload document lên S3, Lambda function sẽ tự động được trigger và sử dụng BDA để trích xuất thông tin có cấu trúc từ tài liệu.
Những gì bạn sẽ học được
Sau khi hoàn thành hướng dẫn này, bạn sẽ có thể:
- Tạo và cấu hình Lambda function qua AWS Console
- Tích hợp Lambda với Amazon Bedrock Data Automation
- Thiết lập S3 Event trigger cho Lambda
- Xử lý tài liệu tự động và lưu kết quả
- Giám sát và troubleshoot Lambda function
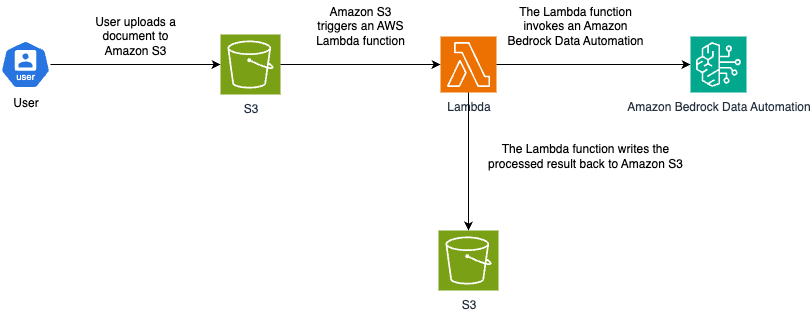
Kiến trúc giải pháp
Yêu cầu kiến thức
- Hiểu biết cơ bản về AWS Console
- Kiến thức cơ bản về Python
- Hiểu biết về S3 và Lambda (mức cơ bản)
Cấu trúc bài viết
Bài viết được chia thành 5 phần chính:
| Phần | Nội dung |
|---|---|
| Phần 1 | Chuẩn bị môi trường (Enable Models, S3, IAM, BDA Project) |
| Phần 2 | Tạo và cấu hình Lambda Function |
| Phần 3 | Thiết lập S3 Trigger |
| Phần 4 | Testing và Deployment |
| Phần 5 | Monitoring và Troubleshooting |
Prerequisites
Trước khi bắt đầu, đảm bảo bạn có:
- AWS Account với IAM permissions cho Bedrock, Lambda, S3, IAM
- Access vào AWS Console
- Chọn một region hỗ trợ Amazon Bedrock Data Automation (khuyến nghị:
us-east-1hoặcus-west-2) - Browser hiện đại (Chrome, Firefox, Safari, hoặc Edge)
Giới thiệu về Amazon Bedrock Data Automation
Intelligent Document Processing với Generative AI
Generative AI không chỉ thúc đẩy đổi mới thông qua ý tưởng sáng tạo và nội dung, mà còn tối ưu hóa quy trình vận hành và tăng năng suất trong nhiều lĩnh vực khác nhau. Amazon Bedrock Data Automation (BDA) là một dịch vụ được quản lý hoàn toàn, cung cấp khả năng Intelligent Document Processing (IDP) được tăng cường bởi generative AI.
Tại sao chọn BDA?
1. Tự động hóa hoàn toàn
Các doanh nghiệp có thể khai thác giá trị đáng kể từ IDP được tăng cường bởi generative AI. Bằng cách tích hợp khả năng generative AI vào giải pháp IDP, tổ chức có thể:
- Hiểu tài liệu nâng cao: Phân tích sâu cấu trúc và ngữ nghĩa
- Trích xuất dữ liệu có cấu trúc: Tự động chuyển đổi từ unstructured sang structured data
- Phân loại tự động: Nhận diện loại tài liệu và định tuyến phù hợp
- Truy xuất thông tin: Tìm kiếm và lấy thông tin từ văn bản phi cấu trúc
2. BDA vs Direct Bedrock API
| Khía cạnh | Direct Bedrock API | BDA (Managed Service) |
|---|---|---|
| Complexity | Cần tự xây dựng pipeline | Fully managed, tích hợp sẵn |
| Document Understanding | Cần prompt engineering | Built-in document intelligence |
| Multimodal | Chỉ xử lý images | Hỗ trợ đa dạng: PDF, images, audio, video |
| Output Format | JSON custom | Standardized JSON + Markdown/HTML/CSV |
| Bounding Boxes | Không có | Tự động cung cấp vị trí elements |
| Scalability | Tự quản lý | Auto-scaling |
| Best For | Custom IDP solutions | Enterprise document processing |
Business Value và Use Cases
Government & Public Sector
Xử lý và trích xuất dữ liệu từ:
- Đơn xin cấp giấy khai sinh, CMND/CCCD
- Hồ sơ nhập cư và visa
- Hợp đồng pháp lý và các mẫu đơn chính phủ
Lợi ích: Giảm thời gian xử lý từ ngày xuống còn vài phút, cải thiện chất lượng dịch vụ công dân.
Healthcare
Trích xuất và tổ chức thông tin từ:
- Hồ sơ bệnh án điện tử
- Yêu cầu bồi thường bảo hiểm y tế
- Đơn thuốc và kết quả xét nghiệm
- Hồ sơ thử nghiệm lâm sàng
Lợi ích: Cải thiện độ chính xác dữ liệu, tăng khả năng tiếp cận thông tin để chăm sóc bệnh nhân tốt hơn.
Finance & Banking
Tự động hóa xử lý:
- Đơn xin vay và hồ sơ tín dụng
- Báo cáo tài chính và thuế
- Hợp đồng và thỏa thuận
- Hồ sơ tuân thủ quy định
Lợi ích: Giảm công việc thủ công, tăng hiệu quả vận hành, giảm rủi ro tuân thủ.
Logistics & Supply Chain
Xử lý:
- Chứng từ vận chuyển và hóa đơn
- Đơn đặt hàng và phiếu nhập kho
- Hợp đồng với nhà cung cấp
- Giấy chứng nhận hải quan
Lợi ích: Tối ưu hóa quy trình, tăng khả năng hiển thị chuỗi cung ứng.
Retail & E-commerce
Tự động hóa:
- Đơn hàng của khách hàng
- Danh mục sản phẩm và mô tả
- Hóa đơn và biên lai
- Tài liệu marketing
Lợi ích: Cá nhân hóa trải nghiệm khách hàng, xử lý đơn hàng nhanh chóng và hiệu quả.
Tại sao kết hợp BDA với Lambda?
Việc kết hợp BDA với AWS Lambda tạo ra một serverless IDP pipeline mạnh mẽ:
- Event-Driven: Tự động xử lý khi có document mới
- Scalable: Tự động scale theo volume documents
- Cost-Effective: Chỉ trả tiền khi xử lý
- Low Maintenance: Không cần quản lý servers
- Integration Ready: Dễ dàng tích hợp với hệ thống hiện có
Thống kê và Impact
Theo AWS, các tổ chức triển khai IDP với generative AI đã đạt được:
- 90%+ giảm thời gian xử lý tài liệu
- 60-70% tiết kiệm chi phí vận hành
- 95%+ độ chính xác trong trích xuất dữ liệu
- 80% giảm nhu cầu can thiệp thủ công
AWS Services trong Workshop
Workshop này sử dụng các AWS services sau để xây dựng serverless IDP pipeline:
Amazon Bedrock Data Automation
Dịch vụ được quản lý hoàn toàn cung cấp khả năng xử lý tài liệu thông minh với generative AI. BDA tự động xử lý documents và trích xuất thông tin có cấu trúc mà không cần phải orchestrate các tác vụ phức tạp.
Tính năng chính:
- Document classification và extraction
- Multi-granularity analysis (document, page, element level)
- Generative summaries và descriptions
- Support đa dạng format: PDF, images, audio, video
AWS Lambda
Serverless computing service cho phép chạy code mà không cần quản lý servers. Lambda tự động scale và bạn chỉ trả tiền cho compute time sử dụng.
Vai trò trong solution:
- Trigger khi có document mới upload
- Gọi BDA API để xử lý document
- Xử lý và lưu kết quả
Amazon S3 (Simple Storage Service)
Object storage service có khả năng mở rộng cao, bền vững và bảo mật.
Vai trò trong solution:
- Lưu trữ input documents
- Lưu trữ output results từ BDA
- Trigger S3 events cho Lambda
Amazon CloudWatch
Monitoring và observability service cho AWS resources và applications.
Vai trò trong solution:
- Thu thập logs từ Lambda execution
- Monitor metrics (invocations, errors, duration)
- Troubleshooting và debugging
AWS IAM (Identity and Access Management)
Quản lý access và permissions cho AWS resources một cách bảo mật.
Vai trò trong solution:
- Tạo execution role cho Lambda
- Cấp quyền truy cập S3, Bedrock, CloudWatch
- Security và access control
Workflow Chi tiết
1. USER uploads document
│
▼
2. S3 Event Notification
│
▼
3. Lambda Function triggered
│
├─▶ Read document from S3
│
├─▶ Call BDA InvokeDataAutomationAsync API
│ │
│ ▼
│ BDA Processing:
│ ├─ Document ingestion
│ ├─ Structure analysis
│ ├─ Content extraction (text, tables, figures)
│ ├─ Semantic enrichment (AI summaries)
│ └─ Result formation (JSON, Markdown, CSV)
│
├─▶ Poll for completion status
│
└─▶ Save results to S3 output bucket
Điểm khác biệt với Traditional IDP
| Traditional IDP | BDA-Powered IDP |
|---|---|
| Rule-based extraction | AI-powered understanding |
| Template dependency | Template-free processing |
| Manual training needed | Pre-trained models |
| Limited format support | Multi-format support |
| No semantic understanding | Deep semantic analysis |
| Fixed output structure | Flexible, rich output |
Phần 1: Chuẩn bị môi trường
Bước 1.1: Enable Model Access trong Amazon Bedrock
Mục đích: Kích hoạt quyền truy cập các foundation models cần thiết cho BDA.
Quan trọng: Đây là bước bắt buộc trước khi sử dụng Amazon Bedrock Data Automation. Nếu không enable model access, BDA sẽ không thể xử lý documents.
Các models cần enable:
Chúng ta cần enable các models sau cho workshop này:
- Amazon Models: Tất cả các models
- Claude Models:
- Claude 3.5 Haiku
- Claude 3 Sonnet
- Claude 3.5 Sonnet
- Cohere Models:
- Cohere Rerank 3.5
Các bước thực hiện:
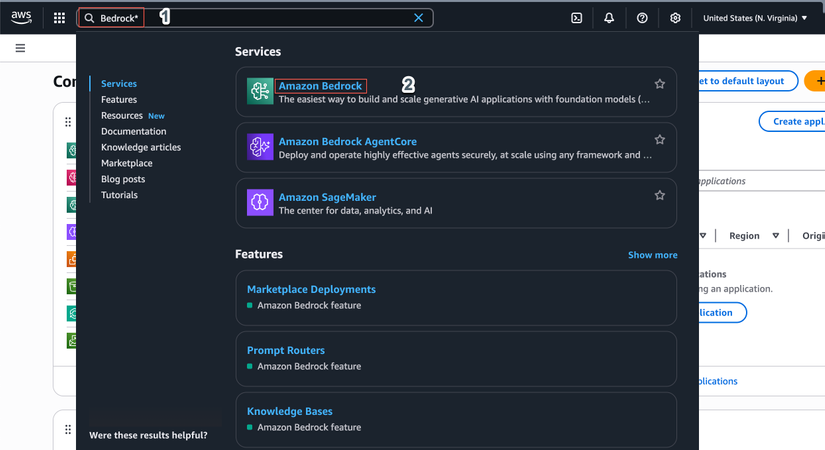
- Mở Amazon Bedrock Console
- Tìm kiếm Bedrock trong thanh tìm kiếm phía trên
- Click vào Amazon Bedrock
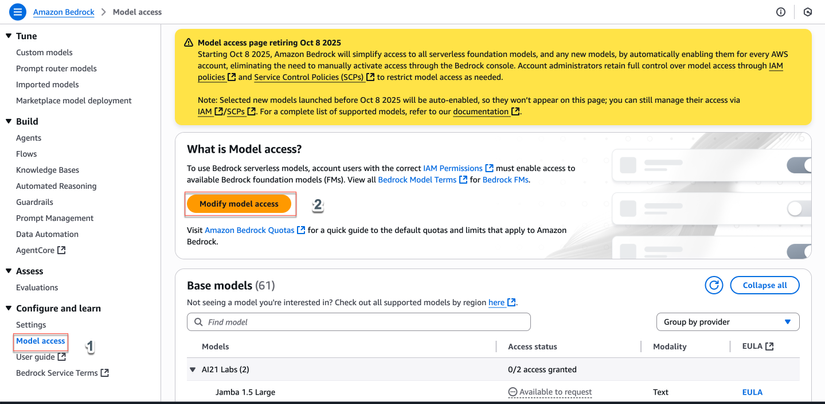
- Truy cập Model Access
- Ở menu bên trái (hoặc navigation menu), click vào Model access
- Click nút Modify model access
-
Chọn Models
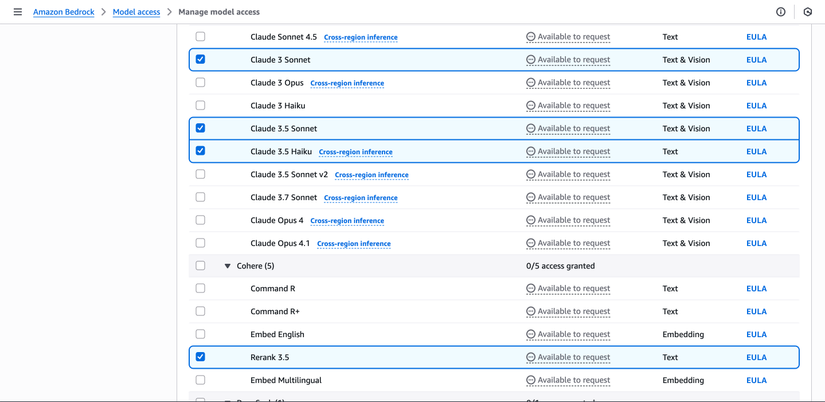
Trong danh sách models, chọn các models sau:
Amazon Models:
- Tick chọn tất cả Amazon models (hoặc chọn "Select all Amazon")
Claude Models (by Anthropic):
- Tick Claude 3.5 Haiku
- Tick Claude 3 Sonnet
- Tick Claude 3.5 Sonnet
Cohere Models:
- Tick Cohere Rerank 3.5
- Submit Request
- Click nút Next ở góc dưới bên phải
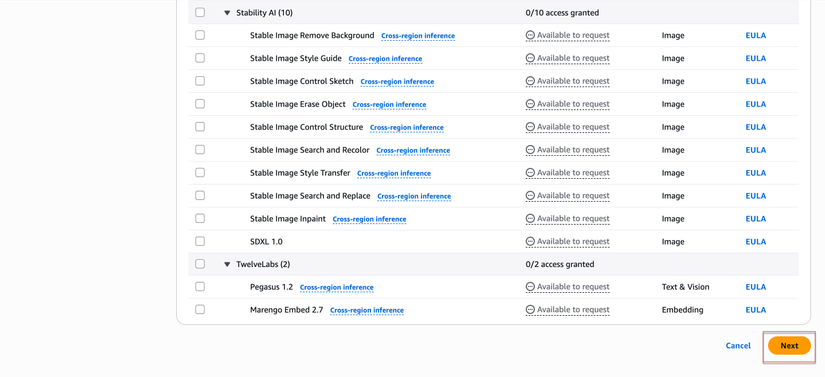
- Review lại các models đã chọn
- Click Submit để request access
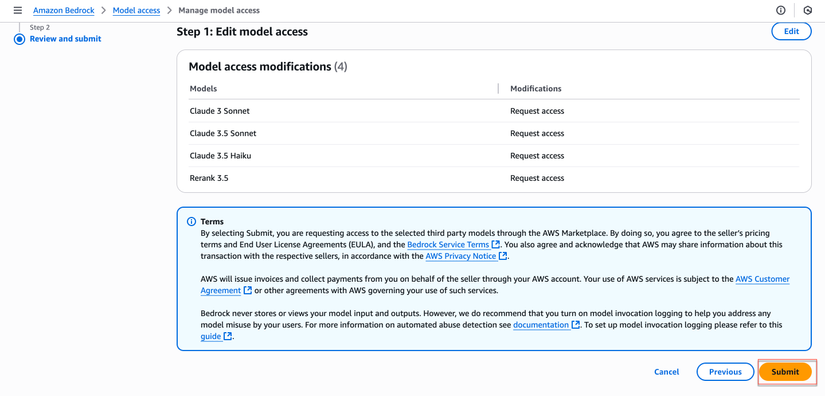
- Chờ Approval
- Hầu hết models sẽ được approve ngay lập tức (status: Access granted)
- Một số models có thể cần vài phút để provisioning
- Refresh trang để xem status update
- Khi tất cả models hiển thị status "Access granted", bạn đã sẵn sàng tiếp tục.
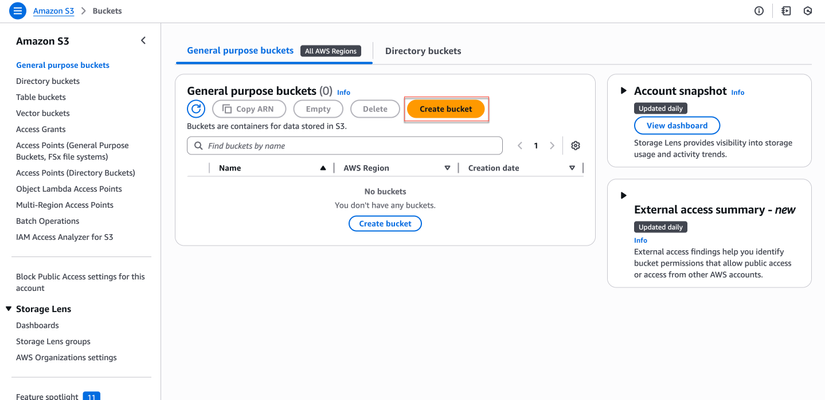
Bước 1.2: Tạo S3 Buckets
Mục đích: Tạo các S3 buckets để lưu trữ tài liệu đầu vào và kết quả đầu ra.
- Đăng nhập vào AWS Management Console
- Tìm kiếm và chọn dịch vụ S3
- Click nút Create bucket
Tạo Input Bucket:
- Nhập thông tin:
- Bucket name:
bda-workshop-input-demo-xyz789(thayxyz789bằng một chuỗi ngẫu nhiên của bạn để đảm bảo tên bucket là duy nhất) - Block Public Access settings: Giữ nguyên (Block all public access)
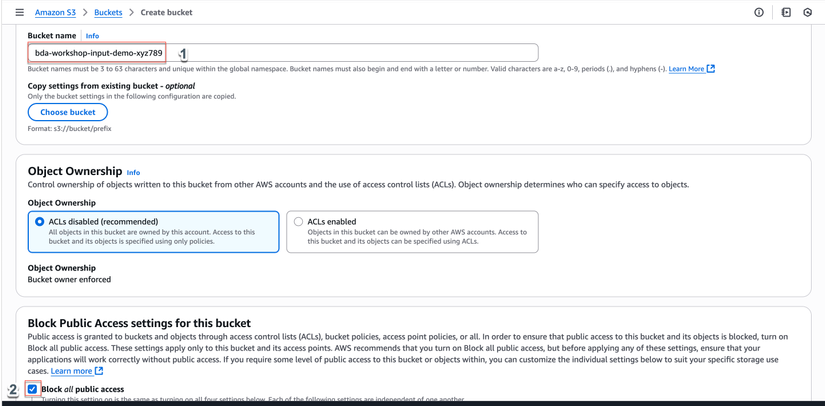
- Scroll xuống và click Create bucket
Tạo Output Bucket:
- Lặp lại các bước 3-5 với:
- Bucket name:
bda-workshop-output-demo-xyz789(dùng cùng suffix với input bucket) - Các cấu hình khác giữ nguyên
Bước 1.3: Tạo IAM Role cho Lambda
Mục đích: Tạo IAM role với đủ quyền để Lambda có thể truy cập S3 và Bedrock.
- Trong AWS Console, tìm kiếm và chọn IAM
- Trong menu bên trái, chọn Roles
- Click nút Create role
Chọn Trusted Entity:
- Trusted entity type: Chọn AWS service
- Use case: Chọn Lambda
- Click Next
Gán Permissions:
-
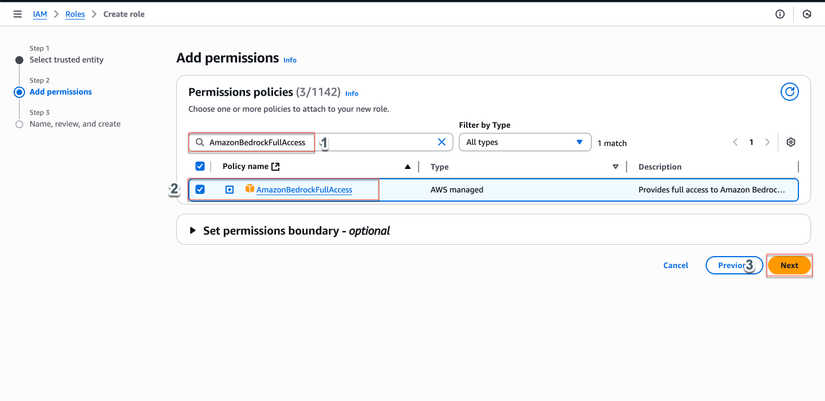
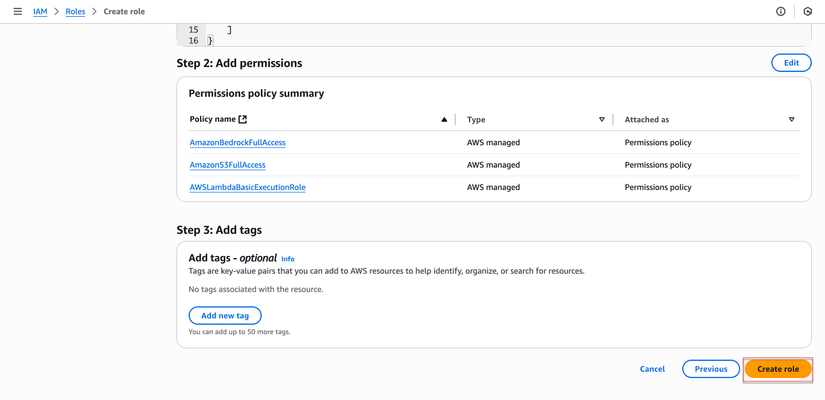
Trong ô tìm kiếm policies, tìm và chọn các policies sau (tick vào checkbox):
AWSLambdaBasicExecutionRole(cho CloudWatch Logs)AmazonS3FullAccess(để đọc/ghi S3)AmazonBedrockFullAccess(để sử dụng Bedrock BDA)
-
Click Next
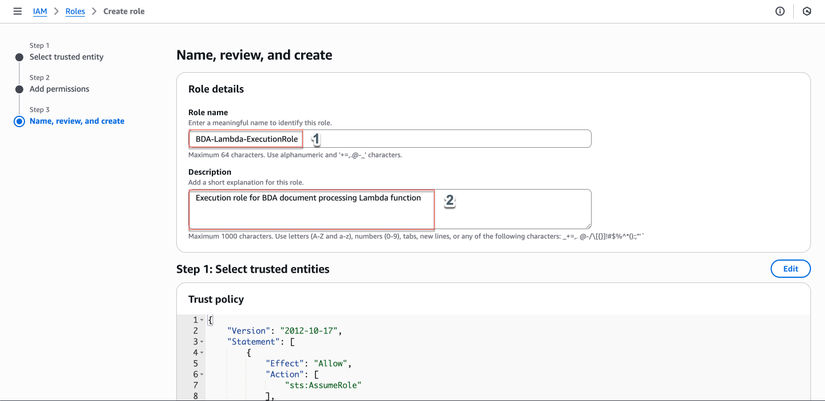
Đặt tên và tạo Role:
- Role name:
BDA-Lambda-ExecutionRole - Description:
Execution role for BDA document processing Lambda function
- Scroll xuống và click Create role
Bước 1.4: Tạo BDA Project
Mục đích: Tạo BDA project để cấu hình cách xử lý tài liệu.
- Trong AWS Console, tìm kiếm và chọn Amazon Bedrock
- Trong menu bên trái, chọn Data Automation > Set-up Project
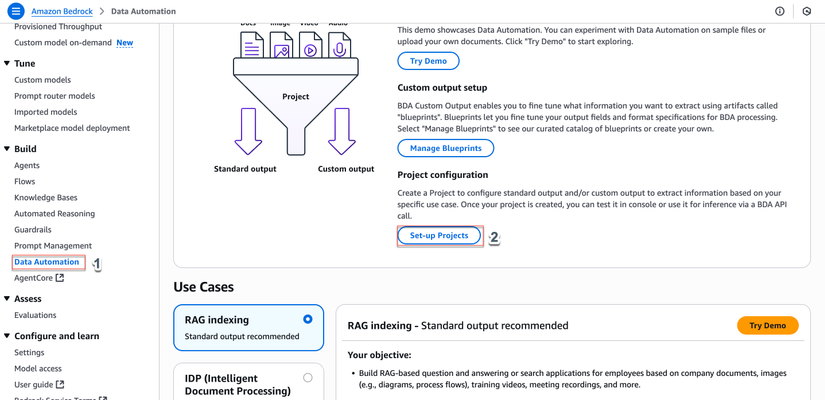
- Click nút Create project
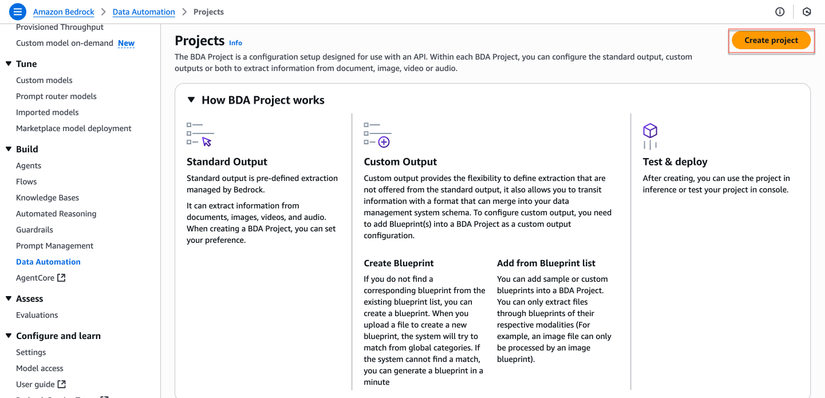
Cấu hình Project:
- Nhập thông tin:
- Project name:
document-processing-project - Chọn Create Project
- Project name:
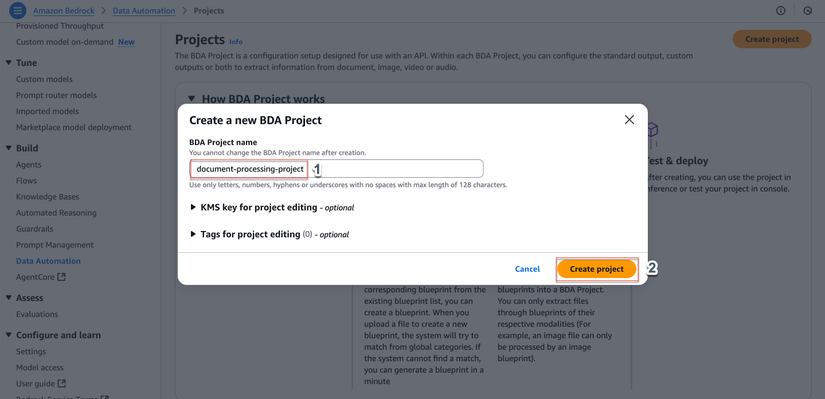
Cấu hình Standard Output:
- Trong phần Standard output, cấu hình:
- Chọn Edit
- Granularity:
- Tick DOCUMENT
- Tick PAGE
- Tick ELEMENT
- Bounding box: Chọn ENABLED
- Generative field: Chọn ENABLED
- Text format types:
- Tick MARKDOWN
- Additional file format: Chọn ENABLED
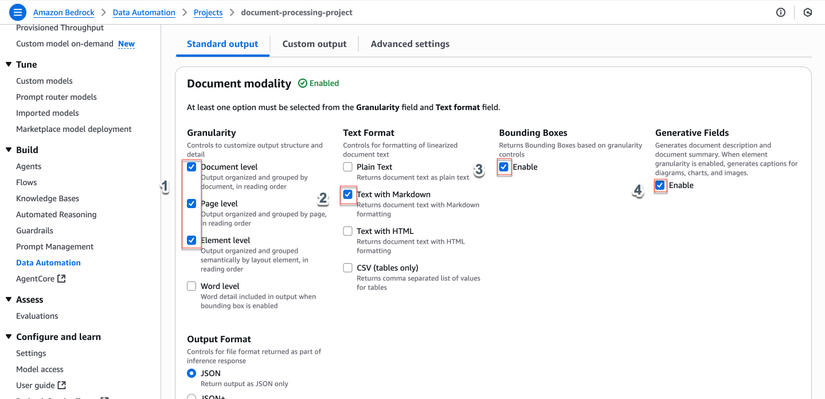
- Click Save changes
-
Chờ project được tạo (status chuyển sang Completed)
-
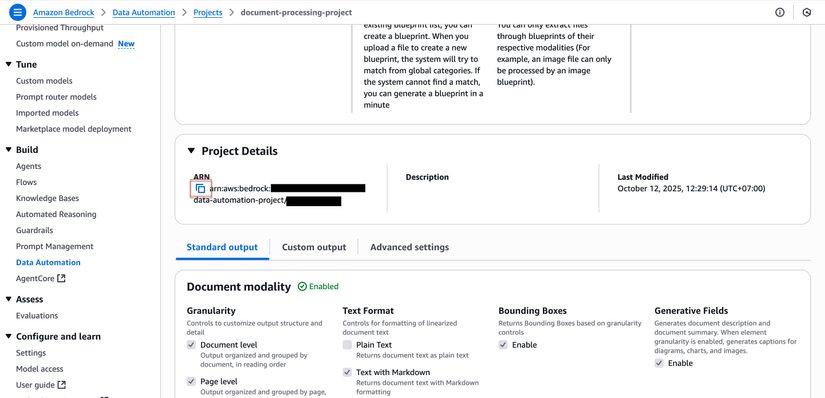
Sao chép và lưu lại Project ARN (sẽ cần dùng trong bước cấu hình Lambda)
- Click vào project name để xem chi tiết
- Copy ARN từ trang chi tiết project
- Ví dụ ARN:
arn:aws:bedrock:us-east-1:111111111111:data-automation-project/abc123xyz
Phần 2: Tạo Lambda Function
Bước 2.1: Tạo Lambda Function
- Trong AWS Console, tìm kiếm và chọn Lambda
- Click nút Create function
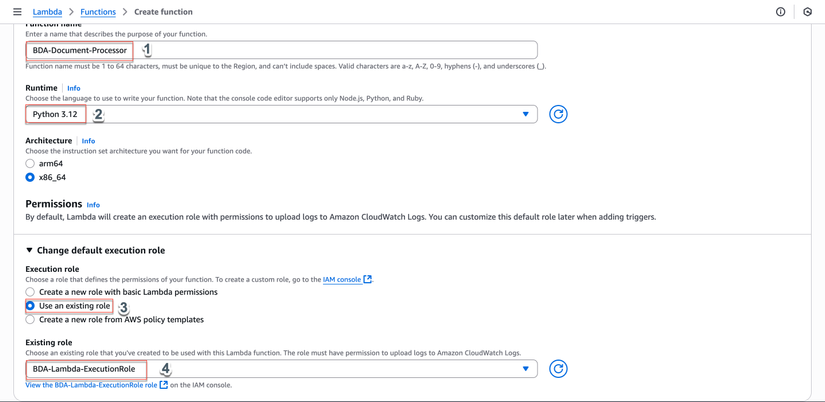
Cấu hình cơ bản:
- Chọn Author from scratch
- Nhập thông tin:
- Function name:
BDA-Document-Processor - Runtime: Chọn Python 3.12
- Architecture: Chọn x86_64
- Function name:
Permissions:
- Trong phần Permissions, chọn Use an existing role
- Existing role: Chọn
BDA-Lambda-ExecutionRole(role đã tạo ở bước 1.2)
- Click Create function
Bước 2.2: Cấu hình Lambda Function
Tăng Timeout và Memory:
- Trong trang Lambda function, chọn tab Configuration
- Chọn General configuration > Click Edit
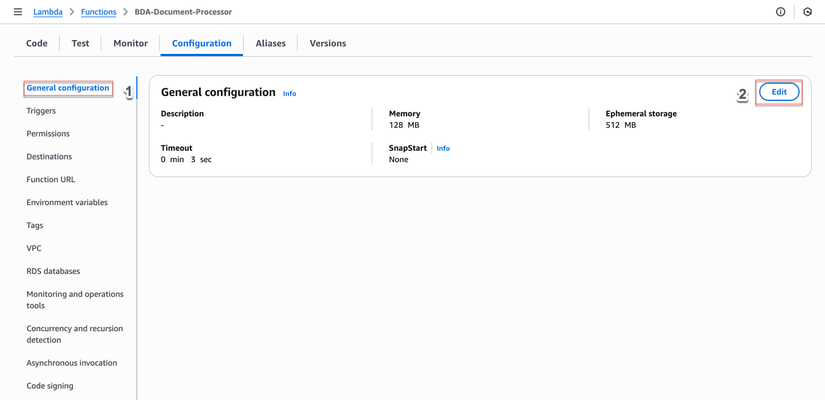
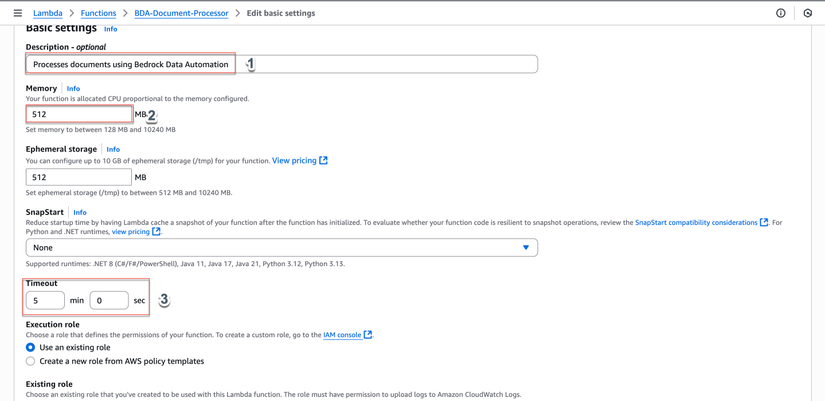
- Cấu hình:
- Memory:
512 MB - Timeout:
5 min(5 phút) - Description:
Processes documents using Bedrock Data Automation
- Click Save
Thêm Environment Variables:
- Vẫn trong tab Configuration, chọn Environment variables
- Click Edit > Click Add environment variable
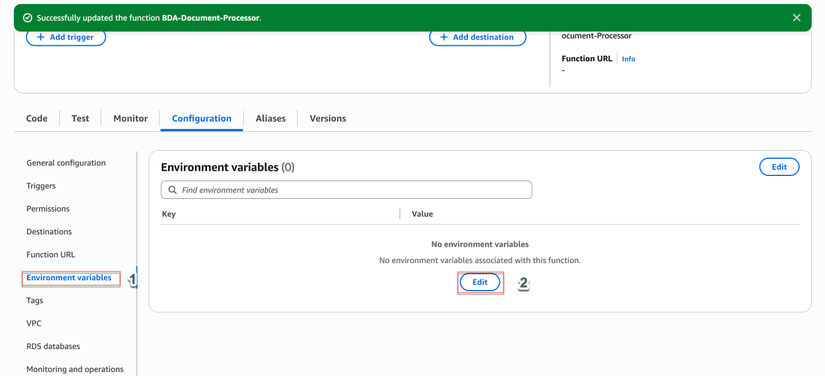
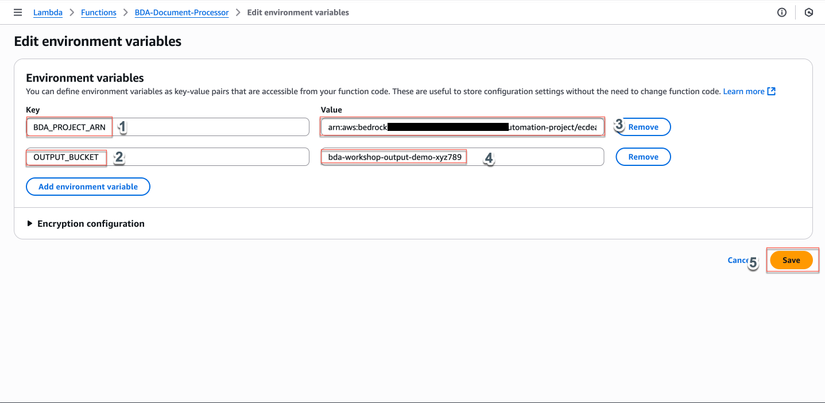
- Thêm các biến sau:
| Key | Value | Mô tả |
|---|---|---|
BDA_PROJECT_ARN |
Paste ARN đã lưu ở bước 1.3 | ARN của BDA project đã tạo |
OUTPUT_BUCKET |
bda-workshop-output-demo-xyz789 |
Tên output bucket (thay bằng tên bucket output của bạn) |
- Click Save
Bước 2.3: Viết Lambda Code
- Quay lại tab Code
- Trong editor, xóa code mẫu và thay bằng code sau:
import json
import boto3
import os
import time
from datetime import datetime
from urllib.parse import unquote_plus
# Initialize AWS clients
s3_client = boto3.client('s3')
bda_runtime_client = boto3.client('bedrock-data-automation-runtime')
sts_client = boto3.client('sts')
# Get configuration from environment variables
BDA_PROJECT_ARN = os.environ['BDA_PROJECT_ARN']
OUTPUT_BUCKET = os.environ['OUTPUT_BUCKET']
# Get region and account ID dynamically (Lambda provides these automatically)
AWS_REGION = os.environ['AWS_REGION'] # Lambda provides this automatically
account_id = sts_client.get_caller_identity()['Account']
# Construct BDA Profile ARN dynamically
BDA_PROFILE_ARN = f"arn:aws:bedrock:{AWS_REGION}:{account_id}:data-automation-profile/us.data-automation-v1"
def lambda_handler(event, context):
"""
Lambda handler function to process documents with BDA.
Triggered by S3 upload events.
"""
try:
# Extract S3 bucket and key from event
s3_event = event['Records'][0]['s3']
input_bucket = s3_event['bucket']['name'].lower() # Ensure lowercase
# URL decode the key (S3 event has URL-encoded keys)
document_key = unquote_plus(s3_event['object']['key'])
print(f"Processing document: s3://{input_bucket}/{document_key}")
# Validate bucket name format (BDA requirement)
if not input_bucket.replace('-', '').replace('.', '').isalnum():
raise ValueError(f"Invalid bucket name format: {input_bucket}. Must contain only lowercase letters, numbers, dots, and hyphens.")
# Construct S3 URIs
input_s3_uri = f"s3://{input_bucket}/{document_key}"
# Generate output path with timestamp
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
file_name = document_key.split('/')[-1]
output_prefix = f"processed/{timestamp}_{file_name}"
output_s3_uri = f"s3://{OUTPUT_BUCKET}/{output_prefix}"
# Invoke BDA to process the document
print("Invoking Bedrock Data Automation...")
response = bda_runtime_client.invoke_data_automation_async(
inputConfiguration={
's3Uri': input_s3_uri
},
outputConfiguration={
's3Uri': output_s3_uri
},
dataAutomationConfiguration={
'dataAutomationProjectArn': BDA_PROJECT_ARN,
'stage': 'LIVE'
},
dataAutomationProfileArn=BDA_PROFILE_ARN
)
invocation_arn = response['invocationArn']
print(f"BDA Invocation ARN: {invocation_arn}")
# Wait for processing to complete (with timeout)
max_wait_time = 240 # 4 minutes (leave 1 min for cleanup)
wait_interval = 10
elapsed_time = 0
while elapsed_time < max_wait_time:
status_response = bda_runtime_client.get_data_automation_status(
invocationArn=invocation_arn
)
status = status_response['status']
print(f"Current status: {status}")
if status == 'Success':
result_s3_uri = status_response['outputConfiguration']['s3Uri']
print(f"Processing completed successfully!")
print(f"Results saved to: {result_s3_uri}")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Document processed successfully',
'input': input_s3_uri,
'output': result_s3_uri,
'invocationArn': invocation_arn
})
}
elif status in ['ClientError', 'ServiceError']:
error_msg = f"Processing failed with status: {status}"
print(error_msg)
return {
'statusCode': 500,
'body': json.dumps({
'error': error_msg,
'invocationArn': invocation_arn
})
}
# Wait before checking again
time.sleep(wait_interval)
elapsed_time += wait_interval
# Timeout reached
print(f"Processing still in progress after {max_wait_time} seconds")
return {
'statusCode': 202,
'body': json.dumps({
'message': 'Processing initiated but not completed within Lambda timeout',
'invocationArn': invocation_arn,
'note': 'Check BDA console for final status'
})
}
except Exception as e:
error_msg = f"Error processing document: {str(e)}"
print(error_msg)
return {
'statusCode': 500,
'body': json.dumps({
'error': error_msg
})
}
- Click Deploy để lưu code
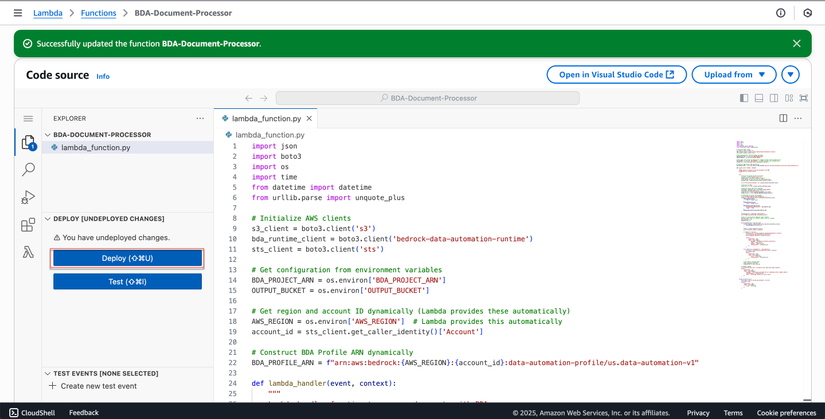
Phần 3: Cấu hình S3 Trigger (10 phút)
Bước 3.1: Thêm S3 Trigger cho Lambda
Mục đích: Cấu hình để Lambda tự động chạy khi có file mới được upload lên S3.
- Trong trang Lambda function, chọn tab Configuration
- Chọn Triggers trong menu bên trái
- Click Add trigger
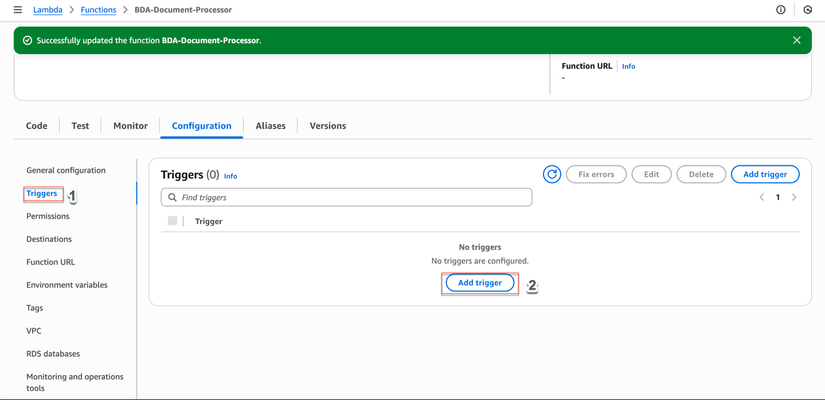
Cấu hình Trigger:
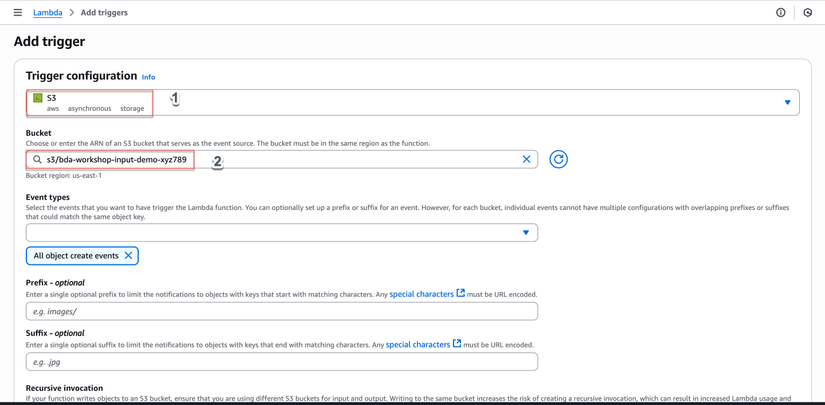
- Select a source: Chọn S3
- Bucket: Chọn
bda-workshop-input-demo-xyz789(bucket input đã tạo ở bước 1.1) - Event type: Chọn All object create events
- Prefix (optional): Để trống (xử lý tất cả files) hoặc nhập
documents/nếu chỉ muốn xử lý files trong folder documents - Suffix (optional): Nhập
.pdfnếu chỉ muốn xử lý PDF files
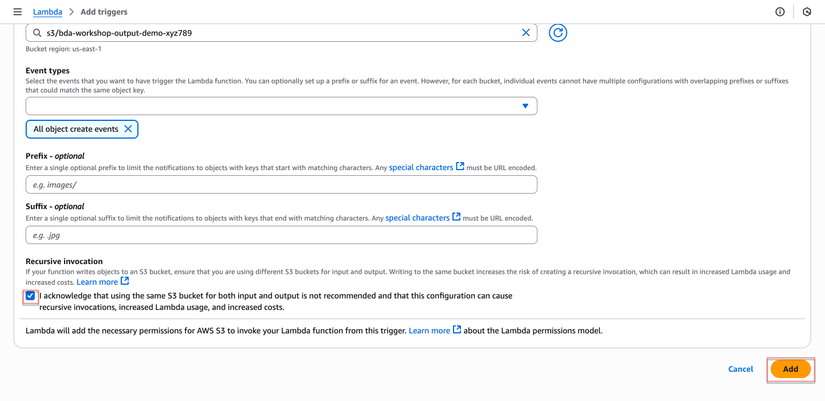
- Tick vào checkbox I acknowledge that using the same S3 bucket...
- Click Add
Phần 4: Testing và Deployment
Bước 4.1: Chuẩn bị Test Document
- Tải một file PDF mẫu về máy (hoặc sử dụng file có sẵn)
Quan trọng - Đặt tên file:
- Tên file nên chỉ chứa: chữ cái (a-z, A-Z), số (0-9), dấu gạch ngang (-), dấu gạch dưới (_), dấu chấm (.)
- Không nên dùng: khoảng trắng, ký tự đặc biệt, ký tự tiếng Việt
- Ví dụ tên file tốt:
document-test.pdf,report_2024.pdf- Ví dụ tên file nên tránh:
báo cáo.pdf,document (1).pdf
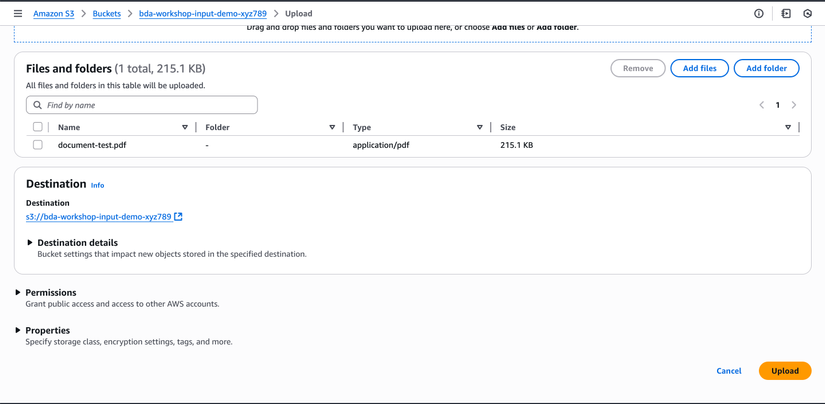
Bước 4.2: Upload và Test
- Mở S3 Console
- Vào bucket bda-workshop-input-demo-xyz789 (input bucket của bạn)
- Click Upload
- Click Add files và chọn file PDF test
- Click Upload
Bước 4.3: Kiểm tra Lambda Execution
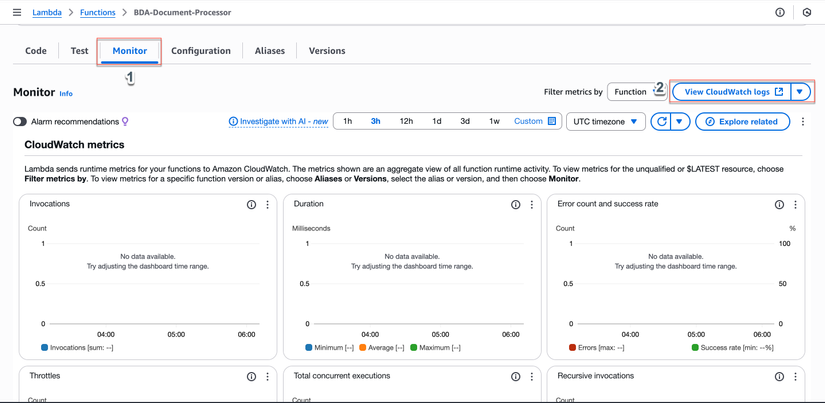
- Quay lại Lambda Console
- Chọn function BDA-Document-Processor
- Chọn tab Monitor
- Click View CloudWatch logs
Trong CloudWatch:
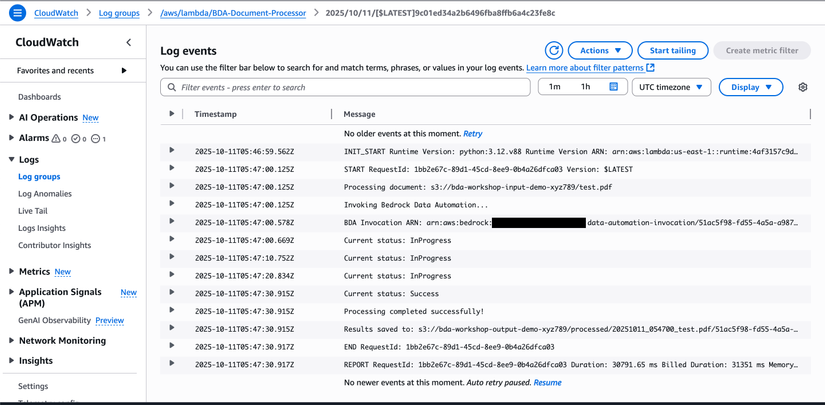
- Click vào log stream mới nhất (thời gian gần nhất)
- Xem logs để kiểm tra:
- Lambda đã được trigger
- Document đang được xử lý
- BDA invocation thành công
- Processing hoàn thành
Bước 4.4: Kiểm tra Output
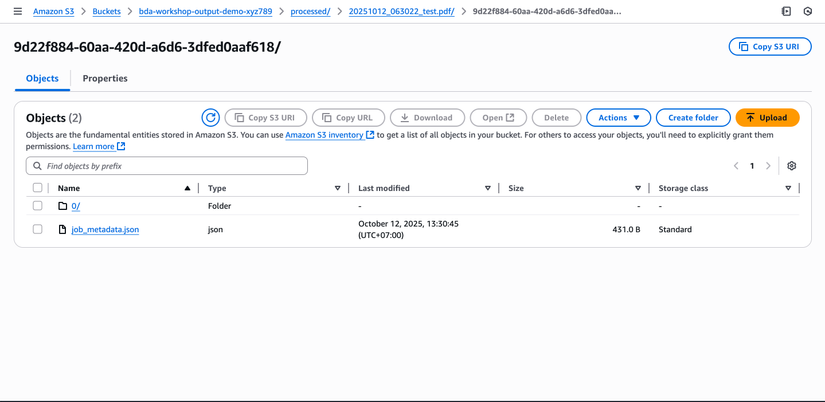
- Mở S3 Console
- Vào bucket bda-workshop-output-demo-xyz789 (output bucket của bạn)
- Vào folder processed/
- Bạn sẽ thấy folder với timestamp và tên file
- Trong folder đó sẽ có:
job_metadata.json- metadata về jobstandard-output.json- kết quả xử lý chính- Các files khác như markdown, CSV (nếu có)
- Download
standard-output.jsonvà mở xem kết quả:- Document summary
- Extracted tables
- Figures
- Page-level information
- Element details
Real-World Example: Government Birth Certificate Processing
Use Case từ AWS Blog
Một ví dụ thực tế từ AWS Machine Learning Blog minh họa cách IDP với generative AI giải quyết vấn đề thực tế:
Bài toán
Cơ quan chính phủ phát hành giấy khai sinh nhận đơn xin qua nhiều kênh:
- Đơn online
- Form điền tại địa điểm vật lý
- Đơn giấy gửi qua bưu điện
Quy trình thủ công hiện tại:
- Scan đơn giấy
- Nhân viên đọc và nhập thủ công vào hệ thống
- Kiểm tra và validation
- Lưu vào database
Vấn đề:
- Tốn rất nhiều thời gian
- Chi phí nhân lực cao
- Dễ sai sót khi nhập liệu thủ công
- Không mở rộng được khi volume tăng
- Phức tạp nếu form bằng nhiều ngôn ngữ (tiếng Anh, tiếng Tây Ban Nha, v.v.)
Giải pháp với BDA
Với architecture tương tự workshop này, nhưng có thêm:
- SQS Queue: Buffer để xử lý messages reliably
- DynamoDB: Lưu trữ extracted data
- Multi-language Support: Tự động dịch và extract
Upload Form → S3 → Lambda → BDA → SQS → Lambda → DynamoDB
↓
Auto-detect language
Extract all fields
Translate if needed
Kết quả đạt được
Trước:
- 15-20 phút/đơn (thủ công)
- Chi phí nhân lực cao
- 85-90% độ chính xác (human error)
Sau (với BDA):
- < 1 phút/đơn (tự động)
- Tiết kiệm 60-70% chi phí
- 95%+ độ chính xác
- Xử lý được nhiều ngôn ngữ
- Scale được hàng nghìn đơn/ngày
Fields được trích xuất tự động
BDA có thể extract các thông tin phức tạp:
- Thông tin người nộp đơn (tên, địa chỉ, liên hệ)
- Thông tin người được cấp giấy khai sinh
- Thông tin cha mẹ
- Thông tin thanh toán lệ phí
- Chữ ký và ngày tháng
- Bonus: Tự động translate từ Spanish sang English
💡 Mở rộng Solution
Bạn có thể mở rộng giải pháp này theo các hướng sau:
- Thêm SQS Queue: Buffer processing và retry logic
- Thêm DynamoDB: Lưu trữ structured data
- Custom Extraction: Định nghĩa fields cần extract cho domain cụ thể
- Multi-language: Xử lý documents bằng nhiều ngôn ngữ
- Human-in-the-loop: Validation cho critical data
Dọn dẹp Resources (Optional)
Nếu bạn không muốn tiếp tục sử dụng và tránh phát sinh chi phí:
Xóa Lambda Function:
- Lambda Console > Chọn function > Actions > Delete
Xóa S3 Buckets:
- S3 Console > Chọn bucket > Empty (xóa tất cả objects)
- Sau đó chọn bucket > Delete
Xóa IAM Role:
- IAM Console > Roles > Chọn role > Delete
Xóa BDA Project:
- Bedrock Console > Data Automation > Projects > Chọn project > Delete
Tài liệu tham khảo
AWS Documentation:
- AWS Lambda Developer Guide - Hướng dẫn đầy đủ về Lambda
- Amazon Bedrock Data Automation - Official BDA documentation
- Amazon Bedrock User Guide - Tổng quan về Bedrock
- S3 Event Notifications - Cấu hình S3 triggers
- Standard Output in BDA - Chi tiết về output configuration
API References:
- BDA CreateDataAutomationProject API
- BDA InvokeDataAutomationAsync API
- BDA GetDataAutomationStatus API
- Lambda Invoke API
AWS Blogs và Case Studies:
BDA-Specific:
- Simplify multimodal generative AI with Amazon Bedrock Data Automation - Giới thiệu BDA
- Unleashing the multimodal power of Amazon Bedrock Data Automation - Advanced BDA use cases
- Get insights from multimodal content with Amazon Bedrock Data Automation - GA announcement
IDP with Generative AI:
- Intelligent document processing using Amazon Bedrock and Anthropic Claude - Real-world IDP example (direct Bedrock API approach)
- Scalable intelligent document processing using Amazon Bedrock - Scalability patterns
- Building serverless document processing workflows - Serverless architecture patterns
Advanced Topics:
- Building a multimodal RAG application with BDA - RAG với BDA
- New Amazon Bedrock capabilities enhance data processing - Latest features
Solution Guidance:
- Guidance for Multimodal Data Processing Using Amazon Bedrock Data Automation - AWS Solutions Library
Product Pages:
- Amazon Bedrock Data Automation Product Page - Features và pricing
- Amazon Bedrock - Main Bedrock page
- AWS Lambda - Lambda features
Video Resources:
- AWS re:Invent Sessions on Bedrock - Conference talks
- AWS Online Tech Talks - Technical webinars
Community và Support:
- AWS re:Post - Bedrock - Community Q&A
- AWS Architecture Center - Reference architectures
Kết luận
Chúc mừng! Bạn đã hoàn thành và tạo thành công một serverless document processing pipeline với AWS Lambda và Amazon Bedrock Data Automation!
Tóm tắt những gì đã học
Trong bài viết này, chúng ta đã cùng nhau:
Hiểu về BDA và IDP: Tìm hiểu về Intelligent Document Processing với generative AI và lợi ích của Amazon Bedrock Data Automation
Xây dựng Infrastructure: Tạo S3 buckets, IAM roles, và BDA project qua AWS Console
Phát triển Lambda Function: Viết Python code để tích hợp với BDA API
Event-Driven Architecture: Thiết lập S3 event triggers cho automated processing
Testing & Monitoring: Deploy, test và giám sát solution với CloudWatch
Troubleshooting: Xử lý các issues thường gặp và best practices
Bước tiếp theo
Giờ đây bạn đã có foundation vững chắc, hãy tiếp tục khám phá:
- Mở rộng sang multimodal: Thử xử lý images, audio, và video với BDA
- Tích hợp downstream systems: Kết nối với DynamoDB, API Gateway, hoặc business applications
- Advanced patterns: Implement human-in-the-loop workflows, model evaluation
- Production readiness: Error handling, DLQ, cost optimization, security hardening
- Explore RAG: Xây dựng multimodal RAG applications với BDA và Knowledge Bases
Lời cảm ơn
Cảm ơn bạn đã đọc bài viết! Hy vọng hướng dẫn này giúp bạn bắt đầu hành trình với Amazon Bedrock Data Automation. Chúc bạn thành công trong việc xây dựng các intelligent document processing solutions!
All rights reserved
