Hadoop Architecture, Data Lake, and Apache Spark
Bài đăng này đã không được cập nhật trong 2 năm
Hadoop là gì và nó hoạt động như thế nào?
Hadoop là một nền tảng xử lý dữ liệu phân tán cung cấp các khả năng cốt lõi sau.
- YARN - Cluster Resource Manager
- Hadoop cluster Operating system: Hệ điều hành cho phép nhiều chương trình nằm trong bộ nhớ và chạy đồng thời. Và điều này đạt được bằng cách chia sẻ các tài nguyên như CPU, bộ nhớ và disk I/O.
- Thường được biết như là Hadoop Cluster Resource Manager
- Có ba thành phần chính:
- RM - Resource Manager
- NM - Node Manager
- AM - Application Master
Ví dụ, chúng ta muốn tạo một cụm hadoop với năm máy tính như dưới, chúng ta sẽ cài đặt và cấu hình Hadoop trên tất cả các máy tính này.
Hadoop sử dụng kiến trúc MASTER-WORKERS, nên một trong những máy này sẽ trở thành máy chủ và những máy còn lại sẽ đóng vai trò là nút công nhân. Cấu hình Hadoop cũng sẽ cài đặt dịch vụ quản lý tài nguyên YARN trên máy chủ.
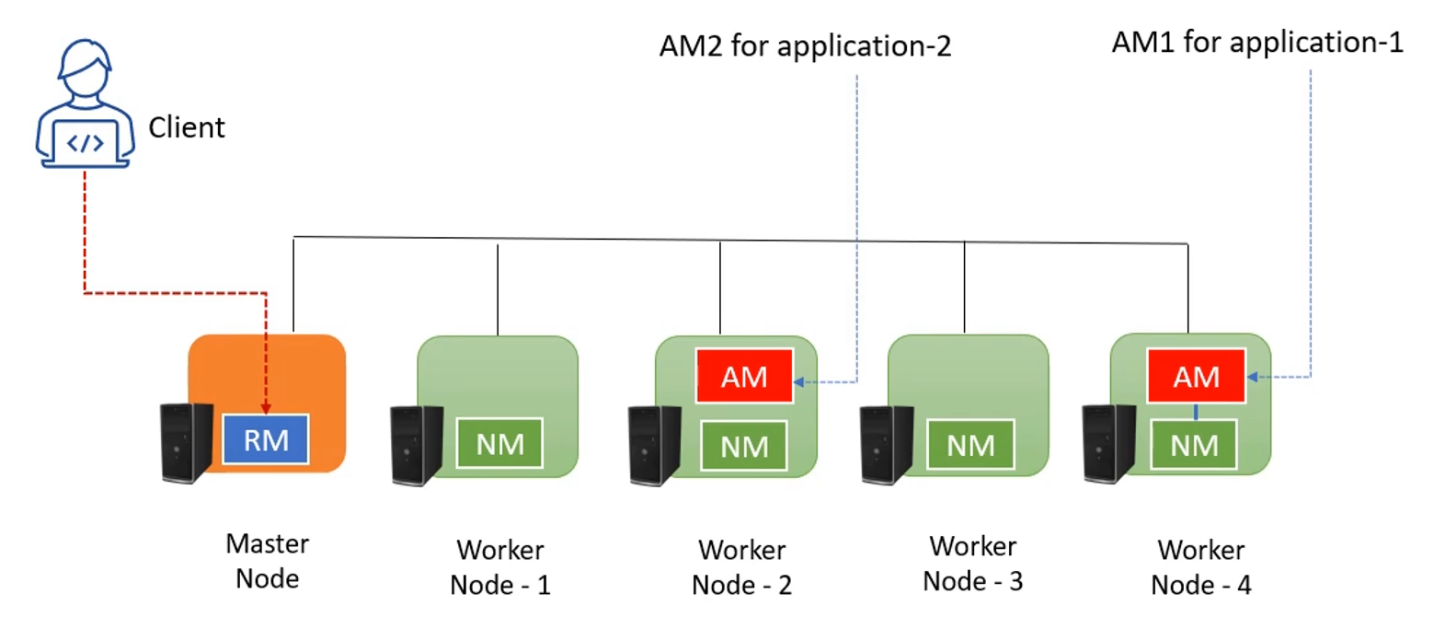
Như hình trên chúng ta có một cụm 5 nút, một nút đóng vai trò MASTER và chạy dịch vụ quản lý tài nguyên YARN. Bốn nút còn lại hoạt động như WORKERS. NM sẽ thường xuyên gửi báo cáo trạng thái nút cho RM.
Để chạy ứng dụng trên Hadoop, bạn phải gửi ứng dụng đó tới người quản lý tài nguyên (RM) YARN. Giả sử bạn đã gửi một ứng dụng Java tới YARN bằng dòng lệnh. Bây giờ RM sẽ yêu cầu một trong những NM để khởi động vùng chứa tài nguyên và chạy ứng dụng chính (AM) trong vùng chứa.
Vùng chứa (container) là gì ? Nó là một tập hợp các tài nguyên bao gồm bộ nhớ và CPU Ví dụ: Bộ chứa YARN có thể là một bộ gồm 2 lõi CPU và 4 GB bộ nhớ.
Do đó, bất cứ khi nào nhắc đến YARN Container, bạn có thể nghĩ đến một hộp CPU và bộ nhớ. Mỗi ứng dụng trên YARN chạy bên trong một vùng chứa AM khác nhau.
- HDFS - Hadoop Distributed File System (dfs)
- HDFS cho phép bạn lưu và truy xuất các tệp dữ liệu trong cụm Hadoop
- Có 2 thành phần chính:
- NN - Name Node
- DN - Data Node
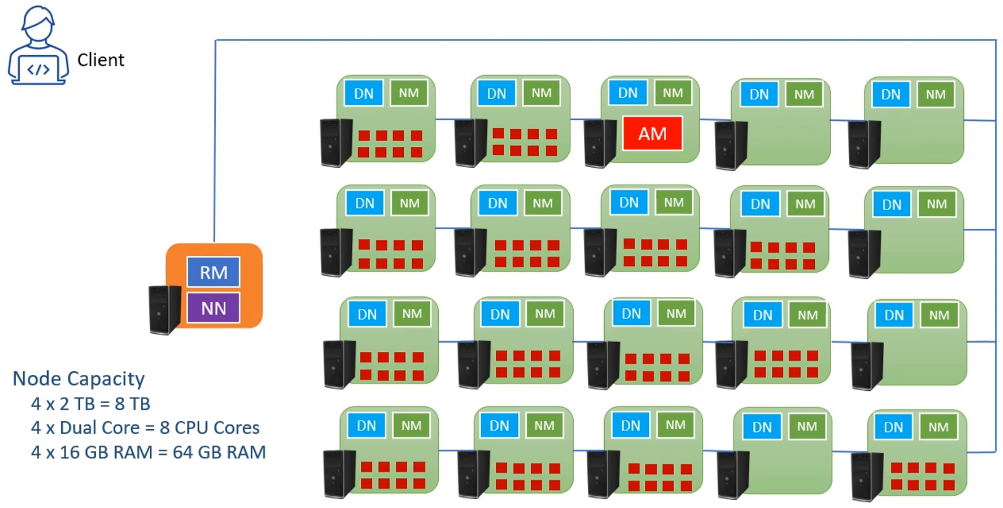
Quay trở lại cấu trúc cụm Hadoop như trên, Hadoop sẽ cài đặt dịch vụ NN trên MASTER và mỗi WORKERS chạy một dịch vụ DN. NN and DN tạo thành HDFS. Mục đích chinh của HDFS là cho phép lưu các tệp trên cụm Hadoop này và đọc chúng bất cứ khi nào cần thiết.
Nó xảy ra như thế nào ? Giả sử bạn muốn sao chép một tệp dữ liệu lớn trên cụm Hadoop -> yêu cầu sao chép tập tin sẽ đi đến nút tên (NN) -> NN sẽ chuyển hướng lệnh "Copy" tới một hoặc nhiều nút dữ liệu -> lệnh sao chép sẽ chia tệp của bạn thành các phần nhỏ hơn (mỗi phần được gọi là một khối)
- M/R - Hadoop Map Reduce Framework Map-Reduce là một programming model và framework
- Programming model: là một kỹ thuật hoặc một cách giải quyết vấn đề
- M/R Framework là một tập hợp các API và dịch vụ cho phép bạn áp dụng "map-reduce programming model"
- Thực hiển logic trong 2 hàm:
- Map Function
- Đọc các khối dữ liệu
- Áp dụng Logic ở cấp độ khối
- dữ liệu ra sẽ được gửi tới "Reduce Function"
- Reduce Function
- Nhận dữ liệu từ Map
- Hợp nhất kết quả
- Map Function
- Hadoop M/R framework thực thi map-reduce model.
- YARN quản lý việc phân bổ nguồn lực
- HDFS quả lý các khối dữ liệu (128 MB)
def map(file_block):
open file_block as fb_hd
for each_t_line in fb_hd.get_line():
n_count = n_count + 1
close fb_hd
return n_count
def reduce(list_counts):
for each_cnt in list_count:
total_count = total_count + cnt
print(total_count)
Data Lake vs Data Warehouse
| AREA | DATA LAKE | DATA WAREHOUSE |
|---|---|---|
Lưu trữ dữ liệu |
Có thể lưu trữ unstructured, semi-structured, and structured data ở dạng raw. A Data Lake lưu trữ tất cả các kiểu dữ liệu, không phân biệt nguồn và định dạng |
Chỉ có thể lưu trữ structured data. Một Data Warehouse lưu trữ dữ liệu trong số liệu định lượng với thuộc tính của chúng. Dữ liệu đã được biến đổi và lọc. |
Định nghĩa lược đồ |
Thông thường, lược đồ (schema) được định nghĩa sau khi dữ liệu được lưu trữ. Điều này mang lại sự linh hoạt và lưu trữ dữ liệu khá dễ dàng, nhưng yêu cầu hoạt động tại điểm kết thúc của quá trình (Schema-on-read) |
Thông thường, lược đồ được định nghĩa trước khi dữ liệu được lưu trữ. Nó yêu cầu hoạt động tại điểm bắt đầu của của quá trình, nhưng nó mang lại hiệu suất, tính bảo mật , và khả năng tích hợp (Schema-on-write) |
Chất lượng dữ liệu |
Bất cứ dữ liệu nào có thể được quản lý hoặc Không (ví dụ như raw data) |
Dữ liệu được quản lý chặt chẽ đóng vai trò là phiên bản trung tâm của sự thật |
Người dùng |
Một Data Lake là lý tưởng cho những người tham gia phân tích dữ liệu sâu như Data Scientists, Data Engineers, Data Analysts. |
Một Data Warehouse the lý tưởng cho người dùng hoạt động như Business Analysts bởi vì định dạng dữ liệu tốt và dễ dàng sử dụng và hiểu rõ. |
Giá và hiệu suất |
Chi phí lưu trữ thấp so sánh với DW, và kết quả truy vấn tốt hơn |
Chi phí lưu trữ cao, kết quả truy vấn tốn thời gian. |
Khả năng tiếp cận |
Một DL có ít hạn chế và dễ dàng truy cập. Dữ liệu có thể thay đổi và cập nhật nhanh chóng |
Một DW được cấu trúc theo thiết kế, điều khiến nó khó truy cập và điều khiển. |
-
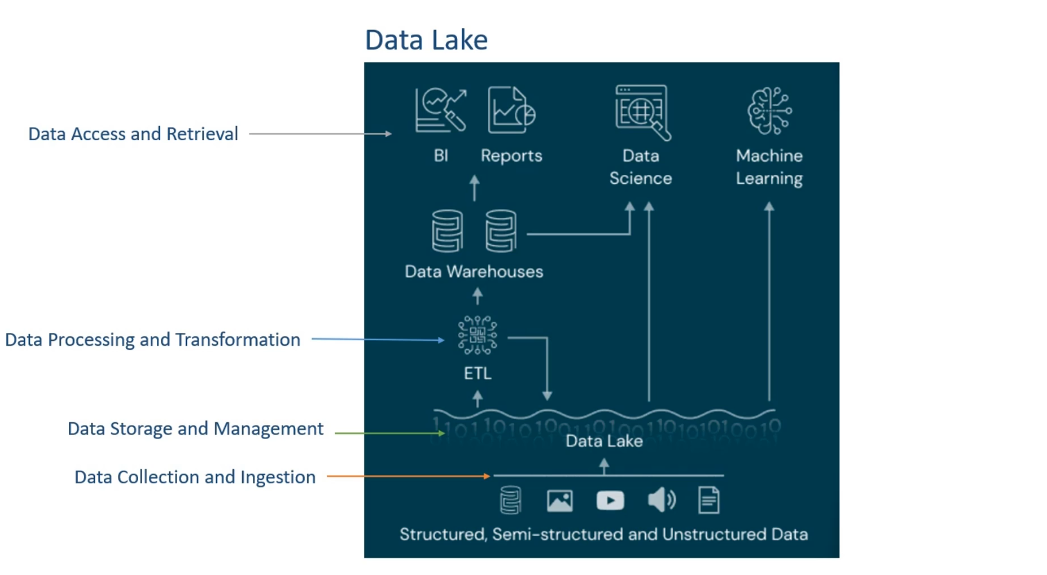
Data Storage and Management
- Bao gồm HDFS hoặc các đối tượng lưu trữ cloud như Amazon S3, Azure Blob, Azure Data Lake storage.
-
Data Collection and Ingestion
- Nhận dạng, thực thi và quản lý dữ liệu để mang dữ liệu từ hệ thống dữ liệu vào Data Lake
-
Data Processing and Transformation
- Khởi tạo kiểm tra chất lượng dữ liệu
- Chuyển đổi và chuẩn bị dữ liệu
- Tương quản, tổng hợp, phân tích và trích xuát dữ liệu
- Ứng dụng model học máy
Apache Spark
Apachec Spark là gì?
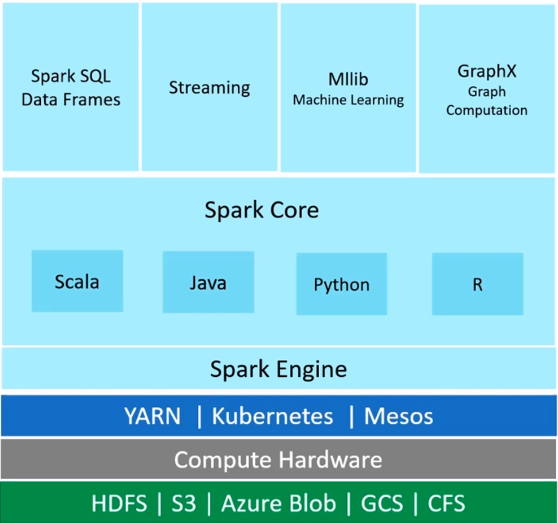
- Là một công cụ đa ngôn ngữ để thự hiện các công việc của Data Engineering, Data Science, và Machine Learning trên các máy hoặc cụm nút đơn.
Lợi thế hơn so với Hadoop
1. Hiệu suất
- Nhanh hơn từ 10 đến 100 lần so mới Hadoop M/R
2. Dễ dàng phát triển
- Spark SQL
- SQL engine hiệu suất cao
- Có thể kết hợp với các function API
3. Hộ trợ nhiều ngôn ngữ
- Java, Scala, Python và R
4. Lưu trữ
- HDFS Storage
- Cloud Storage (Azure blob storage, AWS S3)
5. Quản lý nguồn
- YARN, Mesos, Kubernetes.
All rights reserved
