[GPU in AI] Bài 6: Parquet format cho bài toán ML
Một trong những vấn đề khi chúng ta sử dụng GPU là OOM ( out of memory ) vậy nên ở bài này mình sẽ chỉ các bạn 1 tip để giảm thiểu khả năng bị OOM
Code thì chỉ có 1 dòng, nếu bạn muốn xem code thì có thể kéo xuống phía dưới cùng
Nguyên lý hoạt động của bộ nhớ
Trước khi đi vào bài thì chúng ta phải hiểu nguyên lý hoạt động của bộ nhớ, cách mà bộ nhớ của chúng ta lưu trữ và truy cập data.

Dưới góc nhìn của coder chúng ta ( hay còn gọi là logical view ) thì dữ liệu của chúng ta có thể tồn tại dưới dạng 1D, 2D, 3D,.. nhưng đối với máy tính thì chỉ là 1 dãy dài liên tục
Ví dụ: int a[3][3] thì chúng ta nhìn thấy nó là 1 ma trận gồm 3 hàng 3 cột nhưng bộ nhớ máy tính lại lưu trữ thành 1 dãy dài liên tục a[9]
Và ở đây máy tính có 3 cách phổ biến để lưu trữ dữ liệu đa chiều:
- Row-wise: dữ liệu sẽ được lưu trữ theo hàng
- Columnar: dữ liệu sẽ được lưu trữ theo cột
- Hybrid: dữ liệu không được lưu toàn bộ theo hàng hay theo cột, mà được chia thành từng block nhỏ
Ở đây mình sẽ không đi sâu vào Hybrid mà chỉ tập trung vào row -column
Phương pháp nào là tốt nhất cho ML
Đối với các bài toán ML thì dữ liệu chúng ta thường gặp là dữ liệu dạng bảng và khi xử lí chúng ta thường sẽ xử lí theo cột ( theo các features ) vậy nên columnar sẽ là lựa chọn phù hợp cho bài toán ML hơn là row.
Ở đây chúng ta sẽ phân tích sâu hơn tại sao columnar lại tốt hơn
Data sparsity
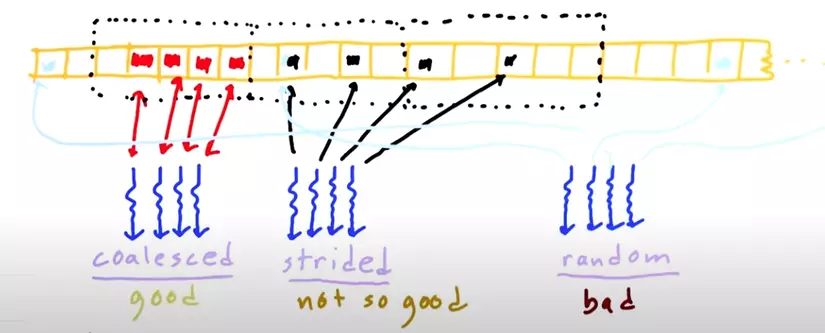
Trong hình minh họa có hai cách lưu trữ dữ liệu (màu đỏ và màu đen).
-
Ở màu đỏ, dữ liệu được lưu liên tiếp nhau.
-
Ở màu đen, dữ liệu được lưu cách nhau một khoảng.
Bài toán đặt ra là khi ta cần truy cập vào dữ liệu đỏ/đen:
-
Với trường hợp dữ liệu nằm liên tiếp → CPU/GPU có thể nạp cả một chunk (khối) vào cache, nên rất hiệu quả.
-
Với trường hợp dữ liệu bị cách quãng, mặc dù ta chỉ cần một vài phần tử, nhưng CPU/GPU buộc phải nạp toàn bộ các chunk chứa chúng. Nghĩa là thay vì lấy đúng 4 giá trị, bộ nhớ phải tải nhiều dữ liệu dư thừa → gây tốn băng thông và cache
-
Nếu dữ liệu nằm ngẫu nhiên → bộ nhớ phải truy cập rời rạc, hiệu năng rất kém.
Quay lại với bài toán của chúng ta, nếu chúng ta lưu trữ dữ liệu ở dạng column thì khi xử lí các cột sẽ tối ưu và tốt hơn khi lưu trữ ở dạng row
CSV không còn phù hợp
CSV sẽ lưu dữ liệu ở dạng hàng nên sẽ không phù hợp với bài toán ML của chúng ta nên thay vào đó hãy chuyển sang Parquet - 1 định dạng file lưu trữ dữ liệu ở dạng cột. Ngoài việc lưu trữ ở dạng cột, Parquet còn có cơ chế compression và encoding thông minh hơn và file parquet thường bé hơn rất nhiều so với CSV

Như hình các bạn có thể thấy chỉ với thay đổi định dạng file ( các thông tin không bị thay đổi ) mà dung lượng đã giảm đáng kể chỉ với 1 dòng code
import pandas as pd
df = pd.read_csv("data.csv")
df.to_parquet("data.parquet")
Chúng ta sẽ kết hợp parquet này vào GPU
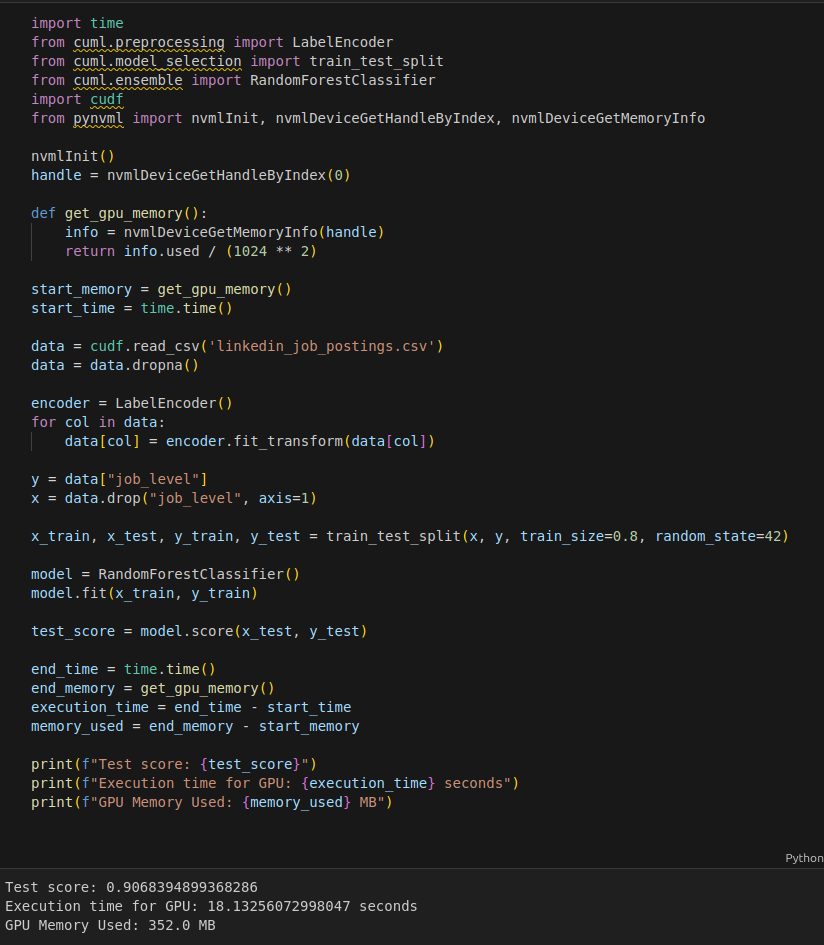
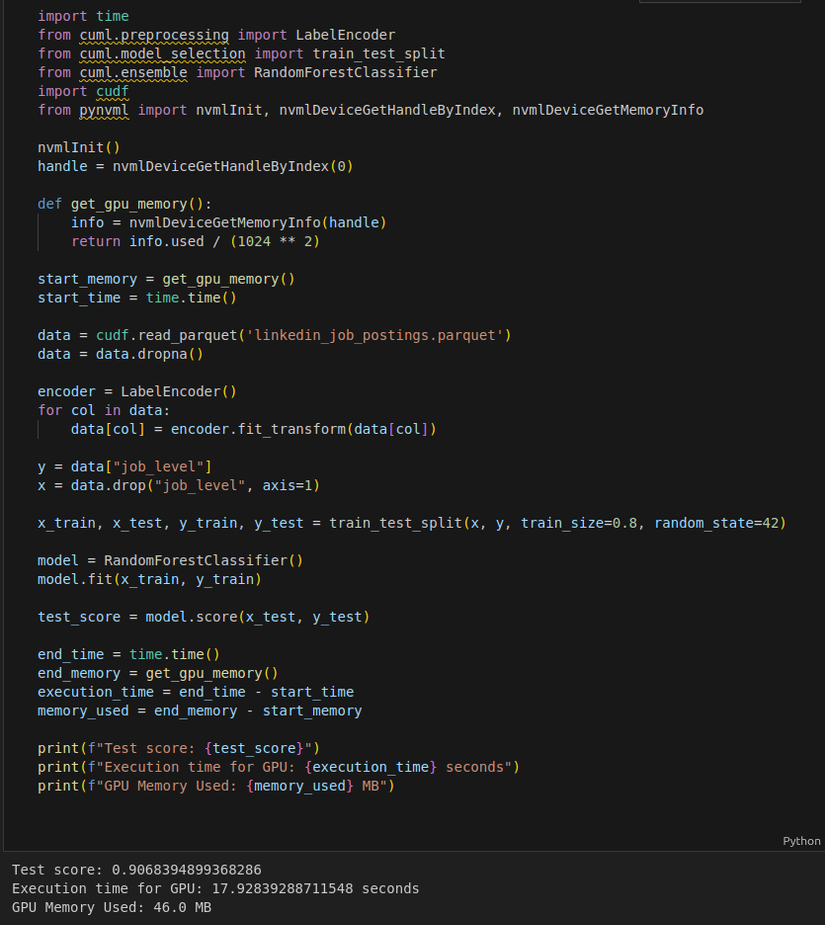
Cùng 1 độ chính xác nhưng bộ nhớ lại được cải thiện đáng kể.
All rights reserved
