Google Dork với Python
Bài đăng này đã không được cập nhật trong 6 năm

Trong bài Cách tìm kiếm với Google, tôi có giới thiệu một vài hướng tìm kiếm nâng cao với Google. Kỹ thuật tìm kiếm đó được gọi là Google Dork hay Google hacking.
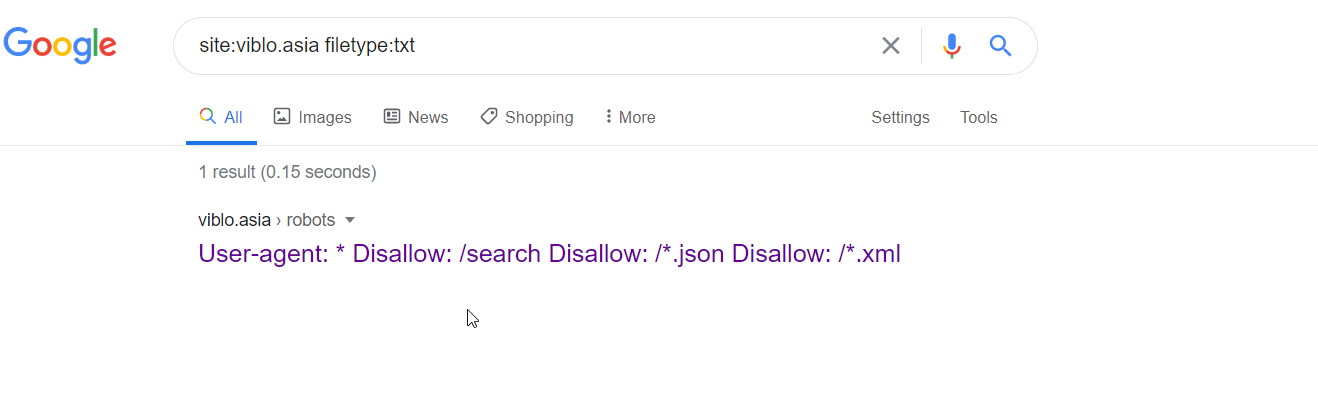
Cách tìm kiếm này rất hiệu quả trong việc tìm kiếm thông tin mà ta cần. Nó tăng độ chính xác cho từ khóa tìm kiếm, giảm thời gian tìm kiếm, vân vân và mây mây.
Nhưng có một vấn đề đặt ra nếu kết quả có nhiều việc thủ công xem xét từng trang một là không hiệu quả. Nếu có một cách nào đó tự động lấy được tất cả các link trên sẽ giảm thời gian của ta đi rất nhiều.
Vì vậy, tôi đã tìm trên Google cách để giải quyết vấn đề đang gặp phải. Và phát hiện ra một bài hướng dẫn How To Scrape Google With Python. Bài hướng dẫn này rất cơ bản và dễ hiểu cho người mới.
Hãy bắt đầu code nào!!!
1. Chuẩn bị môi trường
- Hệ điều hành: Chọn hệ điều hành nào tùy thích, tôi dùng subsystem Ubuntu 18.04
- Python: Cài đặt python2 hoặc python3, tôi dùng python3
- Cài đặt pip: Windows, Ubuntu
sudo apt install python3-pip -y. Nếu sử dụng Python2sudo apt install python-pip -y - IDE: Chọn IDE hoặc trình soạn thảo ưa thích, tôi dùng vim
Note: python2 đã không còn được hỗ trợ sửa lỗi từ nhà phát triển nữa.
2. Bắt đầu code
Cài đặt thư viện cần thiết
Đầu tiên cần cài đặt các thư viện cần thiết cho chương trình. Tạo một file requirements.txt và chèn vào nội dung sau:
requests
bs4
Sau đó chạy lệnh
# Python3
pip3 install -r requirements.txt
# Python2
pip install -r requirements.txt --user
Thêm thư viện
Để chương trình sử dụng được các hàm từ thư viện, ta cần import chúng vào trong chương trình.
import urllib
import requests
from bs4 import BeautifulSoup
Chuẩn bị câu truy vấn
Google sử dụng phương thức GET để nhận dữ liệu từ người dùng nhập vào ô tìm kiếm. Vì vậy ta cần phải tạo ra một địa chỉ URL (URI) tương tự khi ta tìm kiếm trên trình duyệt. Nội dung của từ khóa tìm kiếm được truyền cho tham số q.
query = 'site:viblo.asia cach tim kiem voi google'
query = urllib.parse.quote(query)
URL = f"https://google.com/search?q={query}"
Google trả kết quả có sự khác biệt khi ta sử dụng PC/Laptop hoặc mobile. Làm sao Google biết được điều này, đó là nhờ vào User-Agent. Vì vậy, ta cần chỉ định User-Agent cho mỗi request tìm kiếm.
# desktop user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:65.0) Gecko/20100101 Firefox/65.0'
# mobile user-agent
MOBILE_USER_AGENT = 'Mozilla/5.0 (Linux; Android 7.0; SM-G930V Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.125 Mobile Safari/537.36'
Sau khi đã User-Agent tiếp theo cần làm là chèn vào Header của HTTP. Tại sao lại cần chèn vào Header HTTP? Đó là bởi vì nếu không chèn vào thì lúc ta gửi đi sẽ không có thông tin đó.
headers = {'User-Agent': USER_AGENT}
Thực thi
Đến đây, ta đã có đủ thông tin cần thiết cho việc gửi một GET HTTP requests và nhận lại kết quả tương ứng từ Google.
resp = requests.get(URL, headers=headers)
print(resp.text)
Khi chạy lên ta thu được kết quả như ảnh dưới.
Không phải lúc nào ta cũng nhận được kết quả như mong muốn (tức là server phải hồi với HTTP status code 200). Vì vậy, ta cần phải kiểm tra kết quả trước khi thực hiện phân tích mã nguồn HTML. Kiểm tra rằng nếu server trả về 200 thì mới tiến hành phân tích HTML thông qua Beautiful Soup.
if resp.status_code == 200:
soup = BeautifulSoup(resp.content, "html.parser")
Sau khi có kết quả phản hồi từ Google, ta tiến hành tìm kiếm các link kết liên kết đến kết quả mong muốn. Công việc phân tích HTML để lấy ra kết quả được sự trợ giúp của Beautiful Soup sẽ giảm bớt gánh nặng cho ta. Khi lặp qua toàn bộ code HTML trích xuất kết quả và lưu vào trong một mảng.
results = []
for g in soup.find_all('div', class_='r'):
anchors = g.find_all('a')
if anchors:
link = anchors[0]['href']
title = g.find('h3').text
item = {
'title': title,
'link': link}
results.append(item)
for result in results:
print(result['link'])
Vậy là xong phần phân tích và lưu kết quả. Bây giờ cùng chạy thử nghiệm.
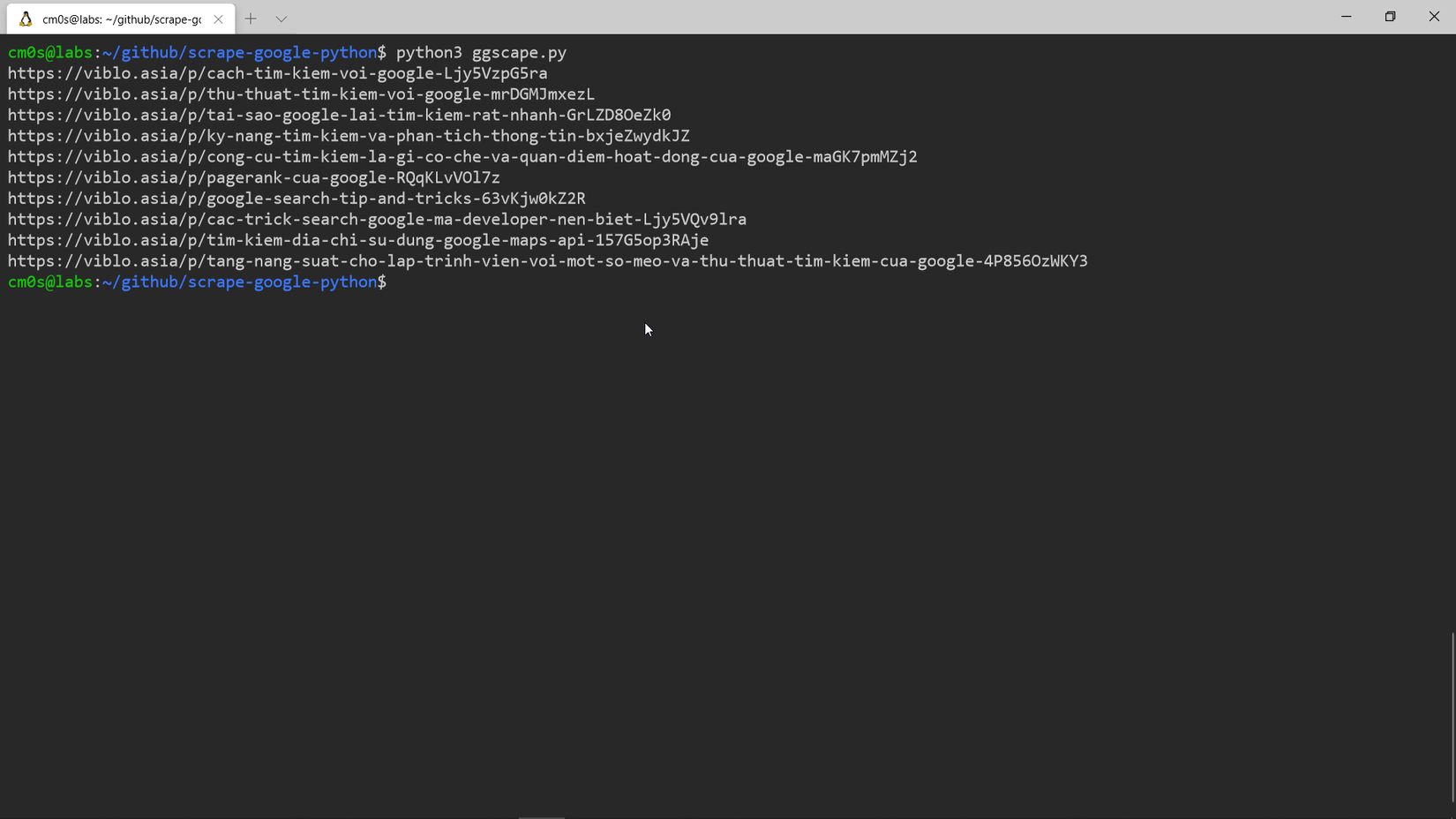
OK! Vậy là ngon lành cành đào rồi.
Đến đây ta có thể cài tiến thêm một chút là từ khóa tìm kiếm được nhập vào hoặc lấy từ tham số.
Hãy thêm chút code cho nó ngon hơn 'cành đào' nhé!
All rights reserved
