[Góc nhìn Kiến trúc] Khi AI cũng phải tuân thủ SOLID
Giải mã kiến trúc Agent Teams từ vụ rò rỉ mã nguồn Claude Code và sự dịch chuyển vĩ đại biến mọi Developer thành System Architect.
Vụ rò rỉ mã nguồn Claude Code vào đầu tháng 4/2026 tạo ra khá nhiều tiếng ồn trong giới công nghệ. Phần lớn các tít báo đều xoáy vào chuyện repo bị clone lại bằng Python và Rust chỉ trong 24 giờ. Nhưng khi ngồi mày mò qua đống code obfuscated vừa được dịch ngược, tôi lại thấy một câu chuyện khác — ít drama hơn, nhưng thú vị hơn nhiều.
Từ trước đến nay, chúng ta hay coi AI Agent như một "hộp đen" huyền bí. Nhưng nhìn vào những gì có thể suy ra từ mã nguồn lõi này, thực tế lại rất... bình thường. Để một AI Agent chạy ổn định ở quy mô lớn, Anthropic đã phải áp dụng những nguyên lý thiết kế phần mềm cũ kỹ mà chúng ta học từ năm nhất đại học — đặc biệt là SOLID.
Nếu bạn đang vật lộn với những đoạn prompt dài dằng dặc mà AI vẫn cứ hallucinate, có lẽ vấn đề không nằm ở prompt. Có lẽ đã đến lúc nhìn AI dưới con mắt của một System Architect thay vì một Prompt Engineer.
Bối cảnh: Lỗi cấu hình "ngớ ngẩn" và sự sụp đổ của bức màn bí mật
Cái đáng mỉa mai là một trong những công ty AI hàng đầu thế giới lại vấp ngã bởi lỗi mà bất kỳ junior dev nào cũng từng được cảnh báo. Theo các báo cáo bảo mật, một kỹ sư đã cấu hình sai file .npmignore, vô tình đẩy Source Map lên NPM registry. File .map này cho phép cộng đồng dịch ngược code obfuscated về gần với bản gốc.
Từ đây, kiến trúc Agent Teams bên trong Claude Code bắt đầu lộ diện. Và những gì được tái dựng lại cho thấy: để AI hoạt động đáng tin cậy, SOLID không phải lý thuyết học thuật — nó là kỷ luật vận hành.
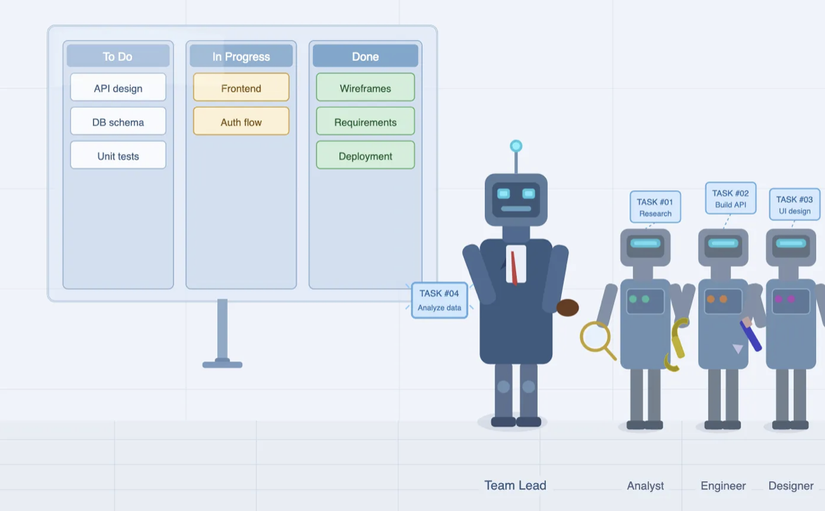
1. SRP (Single Responsibility Principle) và sự sụp đổ của "God Prompt"
Thói quen phổ biến nhất — và tai hại nhất — khi dùng AI là tạo ra những God Prompt. Nhồi vào một context window đủ thứ: phân tích code, tìm bug, fix lỗi, viết test. Tưởng hiệu quả, thực ra đang tự bắn vào chân mình.
Trong lập trình truyền thống, một class ôm đồm quá nhiều việc sẽ sớm muộn sụp đổ — đó là lý do SRP tồn tại. Với LLM, cơ chế tương tự xảy ra ở cấp độ attention: khi context quá tải và mục tiêu mâu thuẫn nhau, model bắt đầu "chọn bên" — tối ưu phần này, vô tình phá phần kia. Kết quả là code được refactor rất đẹp nhưng business logic cũ biến mất không dấu vết.
Kiến trúc được tái dựng từ Claude Code cho thấy Anthropic giải quyết vấn đề này bằng cách phân tầng rõ ràng:
- Team Leader Agent: chỉ làm một việc — lắng nghe yêu cầu, lập kế hoạch, chia nhỏ task. Không viết một dòng code nào.
- Worker Agents: mỗi worker nhận đúng một nhiệm vụ với context vừa đủ để hoàn thành nó. Worker A đọc log tìm root cause; Worker B nhận kết quả từ A để fix; Worker C viết test để bẻ gãy code của B.
Khi mỗi Agent chỉ có một lý do để thay đổi, context của nó sạch, tập trung, và kết quả ổn định hơn nhiều. Bonus: hệ thống tiết kiệm token đáng kể vì không cần dump toàn bộ source code vào mọi tác vụ nhỏ.
2. Tránh Race Condition: Mediator Pattern và bài toán đa luồng
Cho 5 Worker Agent chạy song song và bạn sẽ sớm gặp một vấn đề quen thuộc từ môn Hệ điều hành năm hai: race condition.
Agent A phát hiện bug trong router.ts, bắt đầu ghi fix. Cùng lúc đó, Agent B đang dọn dẹp unused imports cũng ghi vào đúng file này. Ai ghi sau thắng, ai ghi trước mất. File trở thành một mớ hỗn độn không ai chịu trách nhiệm.
Theo những gì có thể phân tích được, Claude Code xử lý vấn đề này bằng Mediator Pattern kết hợp Mutex Lock:
- Các Worker không giao tiếp trực tiếp với nhau — tất cả báo cáo về Team Leader.
- Team Leader giữ vai trò Mediator, nắm quyền phân phối lock. Nếu Agent A đang giữ write lock trên một file, request của Agent B sẽ vào hàng chờ cho đến khi lock được nhả.
Thú vị ở chỗ: bài toán điều phối một bầy AI năm 2026 lại được giải quyết bằng đúng những khái niệm mà chúng ta từng "trầy da tróc vẩy" trong giờ Concurrency trên giảng đường. Semaphore, mutex, critical section — chúng không hề lỗi thời, chỉ đang có thêm một domain mới để áp dụng.

3. OCP thông qua Model Context Protocol (MCP)
OCP nói rằng một hệ thống nên mở để mở rộng, đóng để sửa đổi. Nghe thì đơn giản, nhưng vi phạm nó lại dễ đến mức đáng sợ — đặc biệt khi bạn đang xây AI agent.
Hãy hình dung bạn vừa deploy một agent lên production. Tuần đầu nó làm việc tốt. Tuần sau product manager yêu cầu agent phải biết kéo dữ liệu từ database nội bộ. Bạn mở core prompt ra, thêm vài dòng hướng dẫn. Tuần tiếp theo lại cần đọc log từ Slack. Lại mở ra, lại thêm. Một tháng sau, core prompt của bạn là một văn bản 3000 từ chằng chịt điều kiện, agent bắt đầu hallucinate vì context quá tải, và không ai trong team dám sửa vì không biết sửa chỗ nào sẽ vỡ chỗ nào.
Đây là hệ quả điển hình của việc mỗi lần mở rộng năng lực lại phải sửa vào core. Bạn đang vi phạm OCP không phải một lần mà liên tục, và technical debt tích lũy theo cấp số nhân.
MCP — thứ Anthropic đã public từ trước, và theo code được tái dựng cũng là backbone bên trong Claude Code — giải quyết đúng bài toán này bằng một ranh giới kiến trúc rất rõ ràng:
Core (phần đóng): Reasoning loop của Agent — cái vòng lặp nhận thức, suy luận, ra quyết định — được đóng gói và không đổi. Nó không biết database của bạn là PostgreSQL hay MongoDB. Không biết Slack hay Mattermost. Không biết hệ thống nội bộ của bạn có bao nhiêu API. Và quan trọng là: nó không cần biết. Core chỉ biết một việc — nhận task, suy luận, gọi tool nếu cần, trả kết quả.
Tools (phần mở): Muốn Agent biết làm thêm một việc mới? Bạn viết một MCP Server độc lập — một service chạy riêng, hoàn toàn tách biệt khỏi agent — và cắm vào. Agent tự khám phá tool mới qua JSON Schema, đọc mô tả, hiểu input/output, rồi tự quyết định khi nào nên gọi nó.
Cái đẹp ở đây không chỉ là technical — nó còn là organizational. Team backend có thể viết MCP Server để expose database mà không cần biết AI agent hoạt động ra sao. Team AI có thể thêm tool mới mà không cần đụng vào reasoning core. Hai team làm việc song song, trên hai phần của hệ thống, không dẫm chân nhau. Plugin architecture không phải khái niệm mới — VS Code làm vậy từ lâu, Vim có vậy từ thập kỷ trước — nhưng đưa nó vào AI agent một cách có kỷ luật thì lại là thứ ít người nghĩ đến.
Điều này cũng giải thích tại sao hệ sinh thái MCP bên ngoài lại nổ ra nhanh đến vậy. Khi core và tool được tách biệt hoàn toàn, bất kỳ ai cũng có thể viết tool mà không cần quyền truy cập vào agent. Cộng đồng tự nhiên hình thành một marketplace của các MCP Server — tool cho GitHub, tool cho Jira, tool cho database, tool cho bất cứ thứ gì bạn cần. Agent ngày càng mạnh hơn mà core không hề thay đổi.
Đó chính xác là định nghĩa của OCP: hệ thống phát triển theo chiều ngang, không phải chiều sâu.
4. DIP và bài toán tối ưu chi phí
DIP: module cấp cao không nên phụ thuộc trực tiếp vào module cấp thấp — cả hai nên phụ thuộc vào abstraction.
Dịch sang ngôn ngữ AI năm 2026: nếu bạn hardcode claude-opus-4-6 vào mọi chỗ trong codebase, bạn đang tự trói mình. Khi hóa đơn API phình to hoặc có model mới tốt hơn ra đời, bạn sẽ phải lật tung toàn bộ source code.
Kiến trúc trong Claude Code cho thấy Orchestrator không bao giờ gọi thẳng vào một model cụ thể — nó chỉ biết đến interface IAgent. Model thực sự được inject tại runtime tùy theo độ phức tạp của task:
- Team Leader — cần suy luận sâu, lập kế hoạch, xử lý ambiguity → inject Opus.
- Worker Agents — parse file, grep log, format code → inject Sonnet hoặc Haiku, nhanh hơn và rẻ hơn nhiều.
Kết quả là kiến trúc sư hệ thống có thể hot-swap model bên dưới mà luồng vận hành bên trên không hề hay biết. Đây là cách tối ưu chi phí một cách có hệ thống, không phải kiểu cắt xén thủ công từng chỗ.
💡 Thế còn chữ L và chữ I thì sao?
Để bài viết không biến thành giáo trình khô khan, tôi xin tóm gọn hai chữ cái còn lại trong góc nhìn Agent:
- I (Interface Segregation): Agent QA chỉ nên thấy tool
run_test, không cần biếtdrop_databasetồn tại. Tiết kiệm token, giảm bề mặt tấn công, và tránh để AI "nhìn thấy" những thứ nó không nên dùng. - L (Liskov Substitution): Dù inject Haiku hay Opus, output trả về phải tuân thủ cùng một JSON Schema. Tráo model mà format vỡ — bạn đã vi phạm chữ L và cả pipeline sẽ chết theo.
Tương lai: Asynchronous Agents và kỷ nguyên AI/CD
Phần thú vị hơn trong code được tái dựng — dù chưa thể xác minh hoàn toàn — là hai tính năng ẩn mang tên Kairos và Dream Mode. Nếu những gì phân tích được là chính xác, đây là bước chuyển từ agent synchronous (bạn gõ lệnh, ngồi chờ) sang agent asynchronous chạy như daemon ngầm.
Hình dung thế này: bạn kết thúc ngày làm việc lúc 6 giờ tối, gập laptop. Đến đây Dream Mode mới bắt đầu. Nó rà lại toàn bộ code bạn vừa viết, kiểm tra log trên staging, chạy vòng lặp tự sửa lỗi. Sáng hôm sau trên bàn làm việc là một Pull Request gọn gàng — bạn review, approve, đi pha cà phê.
Đây là bước tiến logic từ CI/CD truyền thống sang thứ có thể gọi là AI/CD — pipeline không chỉ phát hiện lỗi mà còn tự đề xuất cách sửa, thậm chí tự sửa luôn. Chúng ta đang đi theo hướng đó, dù con đường còn khá dài.
Lời kết: Design Pattern không chết — nó đang được kiểm tra lại từ đầu
Có một điều trớ trêu mà tôi cứ nghĩ mãi sau vụ rò rỉ này. Suốt nhiều năm qua, SOLID thường tồn tại trong codebase của chúng ta ở dạng... nửa vời. Chúng ta trích dẫn nó trong code review, rồi lặng lẽ phớt lờ nó khi deadline đến gần, bởi máy tính vốn không phàn nàn. Hậu quả của kiến trúc tồi nhiều khi mất hàng tháng mới bộc lộ.
Nhưng với AI Agent, cái giá của việc vi phạm thiết kế thường phải trả ngay lập tức. Ép quá nhiều context? AI rất dễ bị "Attention Dilution" và sinh ra ảo giác. Quản lý tài nguyên lỏng lẻo? Race condition có thể làm hỏng file ngay lần chạy đầu tiên.
Nếu compiler truyền thống bắt lỗi cú pháp, thì AI lại vô tình đóng vai trò như một "trình biên dịch kiến trúc" (architecture compiler). Nó có xu hướng khuếch đại những lỗ hổng trong thiết kế của bạn ra ánh sáng ngay tại runtime. Hóa ra, nỗ lực dùng SOLID để uốn nắn AI lại trở thành bài kiểm tra xem chúng ta có thực sự hiểu và áp dụng kỷ luật kiến trúc hay không.
Vì vậy, nỗi lo "bị AI thay thế" có lẽ cần được nhìn nhận lại. AI có thể thay thế thói quen gõ code cơ bắp hay vá víu bằng if/else, nhưng nó lại phụ thuộc vào những kỹ sư biết cách vạch ra ranh giới hệ thống, quản lý đồng thời và phân quyền.
Lần tới, khi AI agent của bạn làm ra một mớ hỗn độn, đừng vội chê nó "ngáo". Hãy nhìn lại kiến trúc bạn vừa giao cho nó và tự hỏi:
Mình đang thiết kế AI, hay chính cỗ máy này đang ép mình thiết kế một hệ thống đủ tốt để nó "được phép" thông minh?
Tài liệu tham khảo & Nguồn đọc thêm
- Don't be 10x Engineer: Lessons from Claude Code Leak — Phân tích chi tiết về việc repo clone bằng Python/Rust đạt 130k stars trong 24 giờ.
- Learn 90% Of Claude Code Agent Teams — Hướng dẫn chi tiết cách quản lý Agent Teams, phân quyền Model và cấu hình Tmux.
- Leaked Claude Code source spawns GitHub's fastest repo — Báo cáo bảo mật từ CyberNews.
- Anthropic Claude Code Leak | ThreatLabz (Zscaler) — Phân tích kỹ thuật về lỗi cấu hình file
.maptrên NPM Registry.
All rights reserved
