Giới thiệu/hướng dẫn về Crawler với Scrapy Framework
Bài đăng này đã không được cập nhật trong 4 năm
Hơn 2 năm làm việc với ngôn ngữ Python cũng là ngần đó thời gian mình làm việc với Scrapy Framwork - một framwork mạnh về thu thập dữ liệu. Nói tới đây có thể sẽ có bạn hỏi thu thập dữ liệu là gì, để làm gì, sao phải dùng Scrapy để thu thập dữ liệu? Để giải thích dễ dàng thì mình sẽ đặt ra một bài toán sau: "Bạn cần xây một trang web/ứng dụng tổng hợp những tin tức thời sự được đăng trên các trang báo như Vnexpress, Dantri, Genk... tương tự như thằng Baomoi ấy". Vậy để giải bài toán này thì chúng ta cần có đầu vào là các bài báo được đăng trên các trang kia, khi đó, chúng ta cần dùng Scrapy để thu thập các bài báo. Để viết được một ứng dụng thu thập dữ liệu bằng Scrapy thì trước tiên chúng ta nên tìm hiều qua về Scrapy có những thành phần gì, cách thức hoạt động của nó.
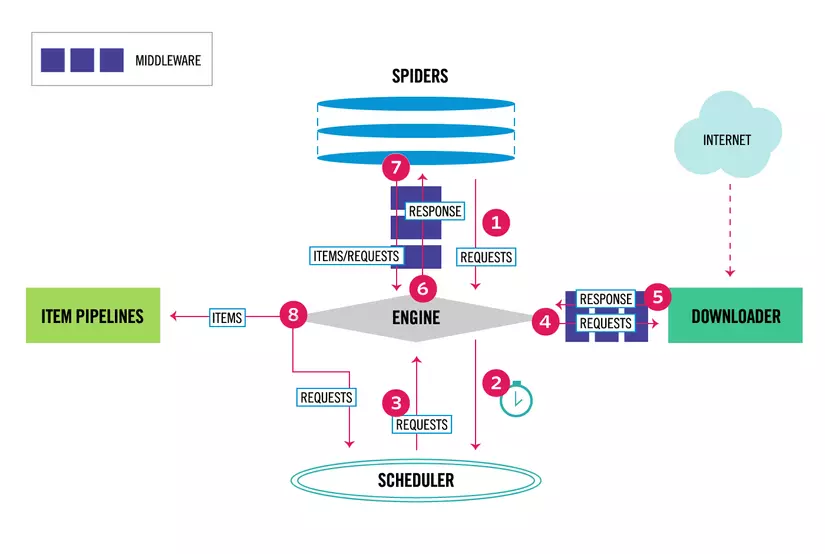
1. Thành phần
Scrapy Engine
Scrapy Engine có trách nhiệm kiểm soát luồng dữ liệu giữa tất cả các thành phần của hệ thống và kích hoạt các sự kiện khi một số hành động xảy ra
Scheduler
Giống như một hàng đợi (queue), scheduler sắp xếp thứ tự các URL cần download
Dowloader
Thực hiện dowload trang web và cung cấp cho engine
Spiders
Spiders là class được viết bởi người dùng, chúng có trách nhiệm bóc tách dữ liệu cần thiết và tạo các url mới để nạp lại cho scheduler qua engine.
Item Pipeline
Những dữ liệu được bóc tách từ spiders sẽ đưa tới đây, Item pipeline có nhiệm vụ xử lý chúng và lưu vào cơ sở dữ liệu
Các Middlewares
Là các thành phần nằm giữa Engine với các thành phần khác, chúng đều có mục địch là giúp người dùng có thể tùy biến, mở rổng khả năng xử lý cho các thành phần. VD: sau khi dowload xong url, bạn muốn tracking, gửi thông tin ngay lúc đó thì bạn có thể viết phần mở rộng và sửa lại cấu hình để sau khi Dowloader tải xong trang thì sẽ thực hiện việc tracking.
a. Spider middlewares
Là thành phần nằm giữa Eninge và Spiders, chúng xử lý các response đầu vào của Spiders và đầu ra (item và các url mới).
b. Dowloader middlewares
Nằm giữa Engine và Dowloader, chúng xử lý các request được đẩy vào từ Engine và các response được tạo ra từ Dowloader
c. Scheduler middlewares
Nằm giữa Engine và Scheduler để xử lý những requests giữa hai thành phần
2. Luồng dữ liệu
- Khi bắt đầu crawl một website, Engine sẽ xác định tên miền và tìm vị trí của spider đó và yêu cầu spider đó tìm các urls đầu tiên để crawl
- Engine nhận danh sách các urls đầu tiên từ spider, gửi cho Scheduler để sắp xếp
- Engine yêu cầu danh sách cách urls tiếp theo từ Scheduler
- Engine nhận danh sách các url tiếp theo từ Scheduler vào gửi đến Dowloader (requests)
- Downloader nhận request và thực hiện việc tải trang, sau khi tải xong sẽ tạo một response và gửi lại Engine
- Respone từ Dowloader sẽ được Engine đẩy qua Spiders để xử lý
- Tại Spiders, khi nhận được response, chúng bóc tách thông tin từ response (tilte, content, author, date publish...) và những url có khả năng để crawl và đẩy lại cho Engine (requests)
- Ở bước này, Engine nhận được kết quả từ Spiders sẽ thực hiện 2 công việc: đẩy những dữ liệu đã được bóc tách tới Item Pipeline để xử lý và lưu vào Databases, đẩy những url mới (requests) mới về Scheduler và quay về bước 3
3. Kết luận
Trên đây là bài đầu tiên trong loạt bài: Giới thiệu/hướng dẫn về Crawler với Scrapy Framework. Trong phần tiếp theo của kỳ tới mình sẽ hướng dẫn cách cài đặt và sử dụng Scrapy. Nguồn tham khảo: https://doc.scrapy.org/en/0.10.3/topics/architecture.html
All rights reserved
