Giới thiệu về Reinforcement Learning (RL)
Bài đăng này đã không được cập nhật trong 6 năm
Trong lĩnh vực trí tuệ nhân tạo nói chung và lĩnh vực học máy nói riêng thì Reinforcement learing (RL) là một cách tiếp cận tập trung vào việc học để hoàn thành được mục tiêu bằng việc tương tác trực tiếp với môi trường.
1. Reinforcement Learning (RL):
RL là học cái để thực hiện, tức là từ các tình huống thực tế để đưa ra các action nhất định, miễn là maximize được reward. Machine không được bảo về cái action để thực hiện mà thay vào đó phải khám phá ra action có thể tạo ra được nhiều reward nhất. Trong thế giới của RL thì chúng ta có khái niệm gọi là agent, nó có một chút gì đó hàm ý về một thực thể mà bạn mong muốn train nó để có thể làm được một task nào đó mà bạn giao phó (đương nhiên là nó sẽ thực hiện theo cách đạt được reward nhiều nhất).
Vì RL được ứng đụng rất nhiều trong robotic và game nên tôi sẽ lấy một ví dụ từ đây cho bạn hình dung. Dưới đây là 1 tựa mini game mà tôi muốn bạn xem qua. Cách chơi thì tôi nghĩ các bạn sẽ dễ dàng để hiểu được. Tên của nó là CoastRunners
Nhiệm vụ của bạn là hoàn thành được chặng đua thuyền một cách nhanh nhất và nếu có thể thì nên ở top trên. Giả sử như bạn muốn training một agent để nó có thể hoàn thành chặng đua nhanh nhất thì về cơ bản bạn phải thiết kế được một reward function và từ đó bạn sẽ train agent dựa trên reward function này. Bạn có thể xem nó là Loss function nhưng thay vì phải minimize hàm loss như trong các mạng Neural Network thông thương thì ở đây chúng ta sẽ phải maximize nó như tôi đã nói ở trên. Việc chọn ra một reward function thoạt nhìn trong khá đơn giản vì nó chỉ dựa trên các tiêu chí rất hiển nhiên của một task cụ thể, chẳng hạn như ở trò chơi ở trên thì ta có dựa trên tiêu chí là thời gian hoàn thành chặng đua chẳng hạn. (Việc thiết kế cụ thể tôi xin phép dời lại ở một bài viết khác về sau). Tuy nhiên, nếu như bạn đưa ra các tiêu chí không tốt thì sẽ agent mà bạn train có thể có các behavior tương đối kỳ lạ giống như thử nghiệm dưới đây mà team OpenAI đã trải qua khi reward mà họ chọn lại dưa trên tiêu chí của score trong game thay vì là thời gian hoàn thành chặng đua. Và đây là kết quả.
Agent không cần phải hoàn thành chặng đua nhưng vẫn có thể đạt được score cao.
Điều này thoạt nhìn qua cái vẻ khá "thú vị" trong bối cảnh của video game nhưng trong lĩnh vực tự động hoá hay robotics chẳng hạn thì các cái behavior này có thể gây ra những hành động không mong muốn hoặc thậm chí nguy hiểm. Rộng hơn, các agent này (được nhúng vào trong robot chẳng hạn) có thể có những hành vi không ổn định hoặc không tuân theo các nguyên lý cơ bản về mặt kỹ thuật nói chung mà có thể dãn đến các hiểm hoạ rất tiềm tàng.

Các bạn có thể tham khảo thêm về idea trong bài báo của OpenAI về cái mà họ gọi là Safety AI
2. Mô hình hoá toán học của RL:
Bây giờ tôi sẽ dẫn các bạn đi qua một chút về các khái niệm chính trong RL:| .
Các hình dưới đây tôi tham khảo từ khoá học 6.S191 intro deep learning của MIT
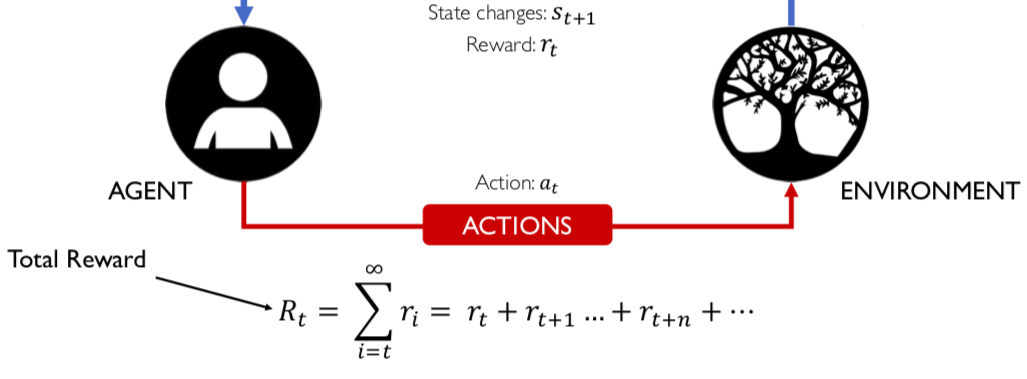
2.1 Đây là một ví dụ trực quan về Agent:

2.2 Enviroment xung quang của Agent, nơi mà agent tồn tại và tương tác:

2.3 Dựa trên State S(t) của enviroment hiện tại mà agent sẽ đưa ra action a(t):

2.4 Sau khi nhận được sự tương tác từ agent thì enviroment có sự chuyển đổi trạng thái đối với agent:
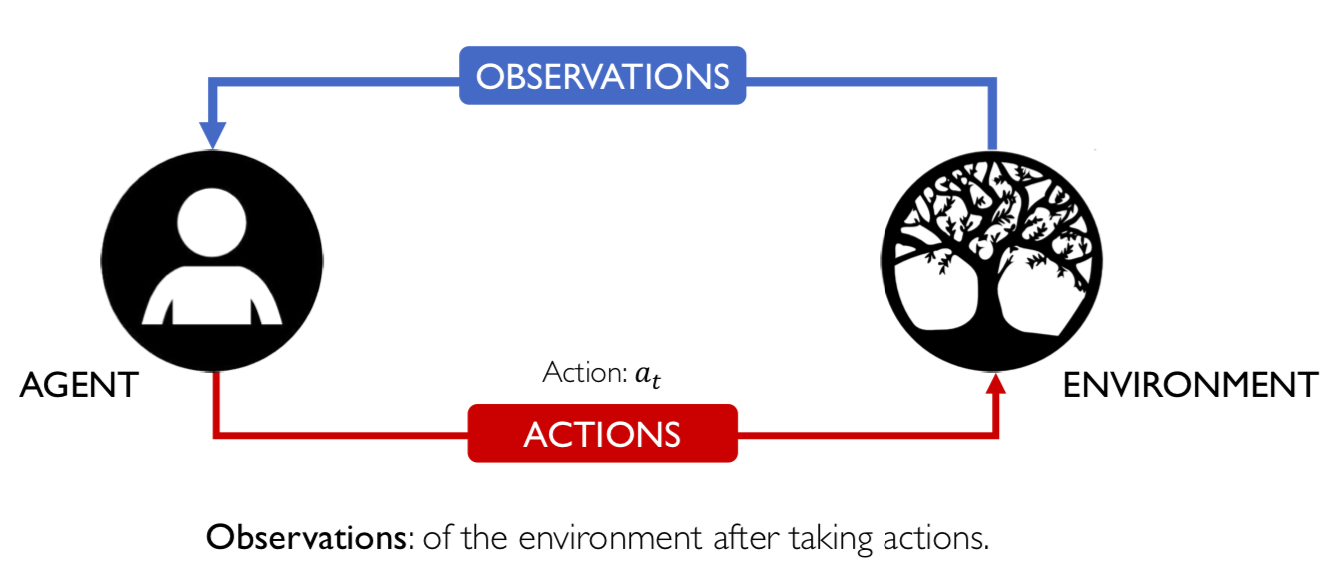
2.5 State lúc này của enviroment là S(t+1), tức ở thời điểm t+1:
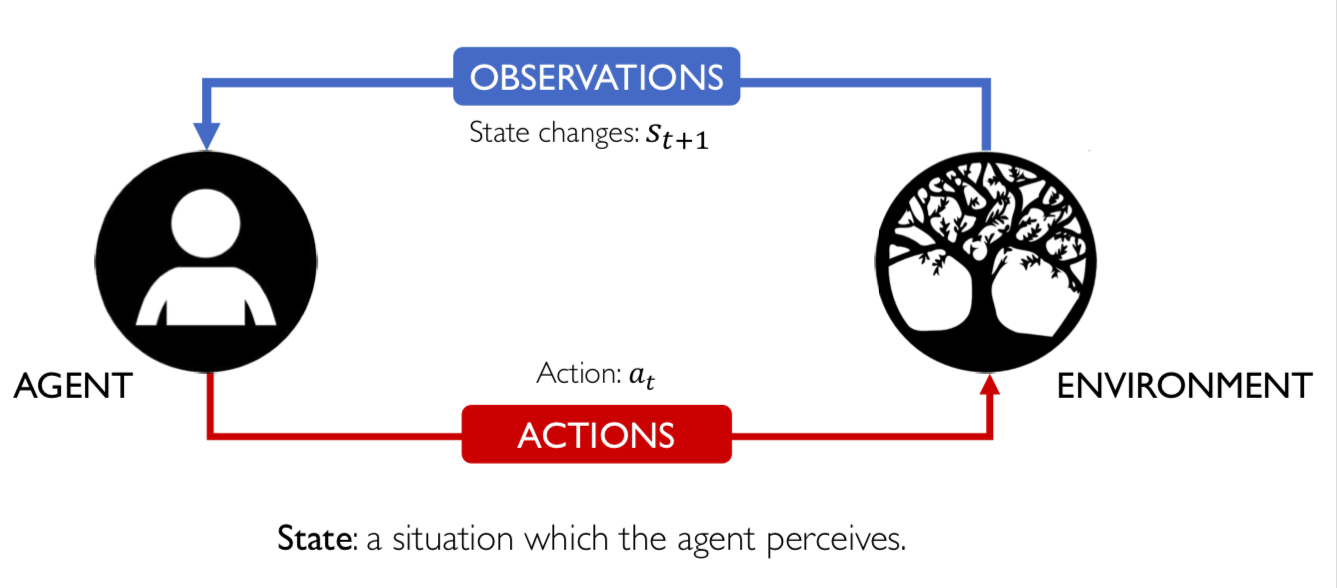
2.6 Lúc này, agent nhận được reward r(t). Reward này phụ thuộc vào action a(t) của agent và State S(t) của enviroment ở thời điểm trước đó, tức là ở thời điểm t:
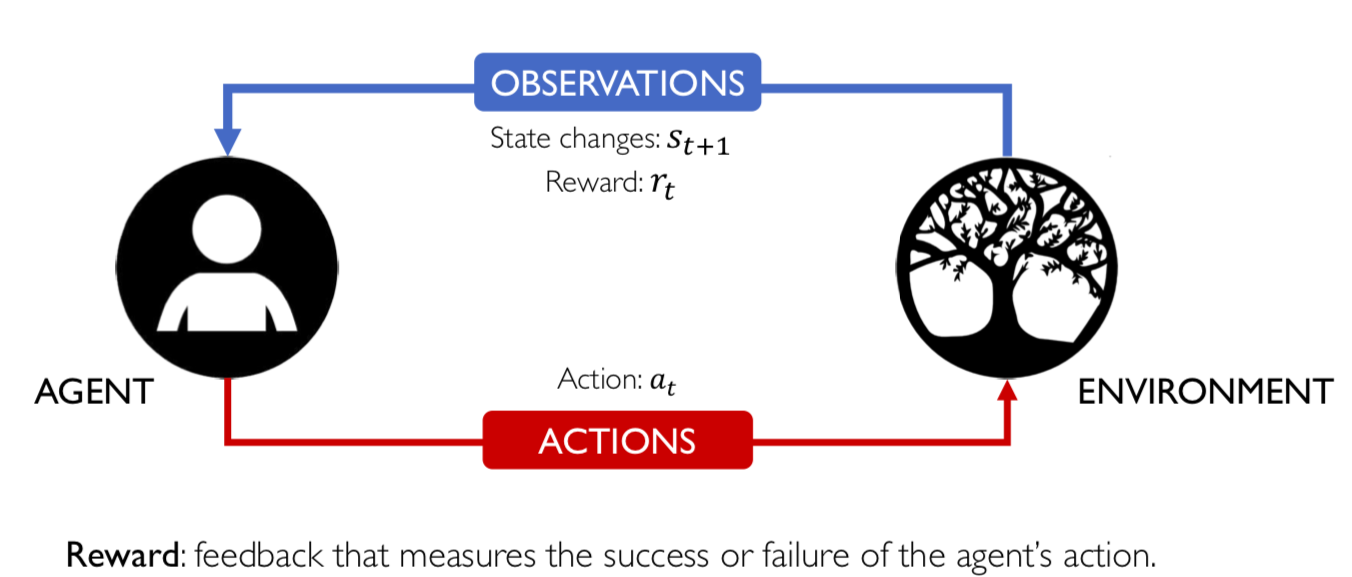
2.7 Vì ta không biết thời điểm kết thúc của sự lặp đi lặp lại này nên tổng reward sẽ là một chuỗi vô hạn của các reward thành phần tại các thời điểm khác nhau kể từ thời điểm t (lúc đầu):
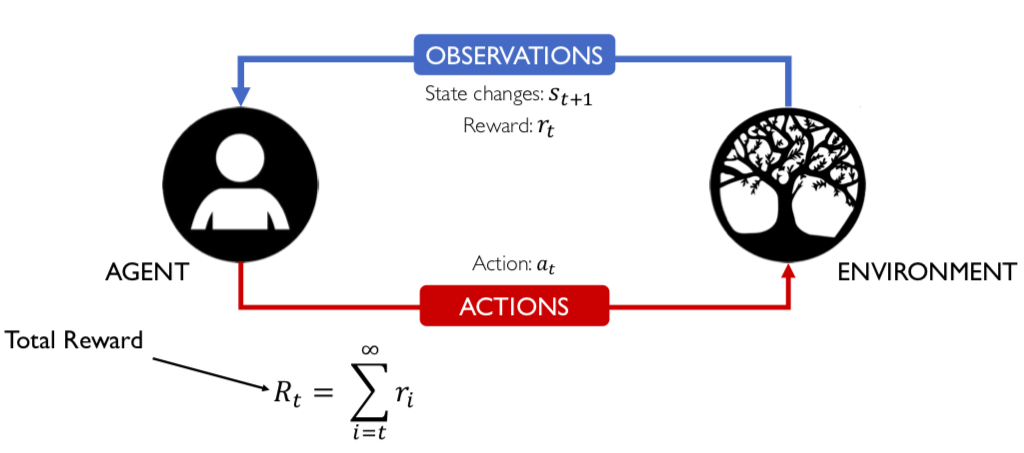
2.8 Chúng ta có thể khai triển chuỗi vô hạn này như sau:
2.9 Vì chuỗi này không thể nào hội tụ (convergence) được nên trên thực tế các nhà nghiên cứu có thể dùng một cái trick để chuỗi này có thể hội tụ được. Như hình dưới đây, họ đưa vào thêm một term thường được gọi là discount factor (discount rate) để làm cho chuỗi này hội tụ.
*Nên nhớ việc hội tụ là bắt buộc nếu bạn muốn train thành công một agent nói riêng hay một mạng Neural Network nào đó nói chung.
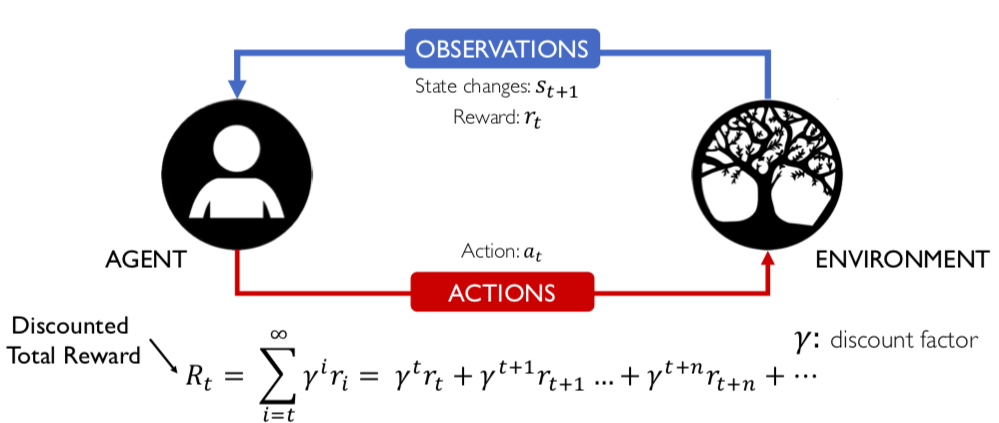
Tất cả những thứ mà mình vừa trình bày sơ qua nó dựa trên một framework được gọi là Markov Decision Processes (MDPs). Về cơ bản thì một MDP cung cấp một framework toán học cho việc modelling các tình huống decision-making. Ở đây, các kết quả (outcomes) xảy ra một cách ngẫu nhiên một phần và phần còn lại thì phụ thuộc trên các action của agent (hoặc decision maker) đã tạo ra trước đó. reward thu được bởi decision maker phụ thuộc trên action mà decision maker chọn và dựa trên cả hai State mới (S(t+1)) và cũ (S(t)) của enviroment.
Một reward thu được khi agent chọn action ở state và làm cho enviorment chuyển đổi từ state sang . Agent nó follow theo một policy . Cụ thể là sao cho với mỗi một state thì agent chọn cho nó một action . Vậy nên policy là thứ bảo với agent cái action nào nên được chọn trong mỗi state.
Để có thể train được agent thì mục tiêu của chúng ta là phải tìm được policy sao cho:
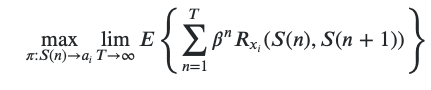
* là discount factor và < 1
Về cơ bản thì chúng ta đang cố gắng để maximize tổng của tất cả các reward (có tình đến discount factor như đã đề cập ở trên) ở mỗi state cụ thể từ lúc bắt đầu đến khi kết thúc (dẫu cho T , vì chúng ta chưa biết khi nào thì quá trình này kết thúc nên nó vẫn luôn là một chuỗi vô hạn), và đương nhiên là phải dựa trên policy vì agent của chúng ta base trên nó để chọn reward tốt nhất mà. Bản chất thì đây là một bài toán tối ưu (optimazation problem).
Ở trên là một tiêu chí mà chúng ta có thể dùng để optimize cho việc tìm ra nghịệm (optimal policy). Cụ thể chúng ta gọi tiêu chí này là infinite horizon sum reward criteria. Cũng có một vài reward criteria khác mà tôi tạm thời không gác lại trong khuôn khổ bài viết này.
Phụ thuộc vào các criteria khác nhau mà chúng ta sẽ có các algorithm khác nhau để tìm ra optimal policy. Với infinite horizon sum reward criteria thì chúng ta có thể sử dụng một thuật toán RL cũng khá kinh điển đó là Q-Learning để giải quyết (tôi sẽ nói về alogorithm này ở một bài viết khác).
Tôi xin tạm thời gác lại phần lý thuyết sơ bộ ở đây. Hẹn gặp lại bạn ở bài viết sau về Q-Learning và cách để impement nó.
3. Refercences:
- Reinforcement learning an introduction
- https://stats.stackexchange.com/questions/221402/understanding-the-role-of-the-discount-factor-in-reinforcement-learning
- https://openai.com/blog/faulty-reward-functions/
- http://introtodeeplearning.com/materials/2019_6S191_L5.pdf
- https://www.youtube.com/watch?v=JgvyzIkgxF0
All rights reserved
