Giới Thiệu về PaliGemma: Open Vision-Language Model
Bài đăng này đã không được cập nhật trong 2 năm
1. PaliGemma là gì ?
PaliGemma là một mô hình ngôn ngữ thị giác (VLM) được phát triển và phát hành bởi Google với các khả năng đa tác vụ. Không giống như các VLM khác, chẳng hạn như GPT-4 của OpenAI, Google Gemini và Claude 3, những mô hình này gặp khó khăn với việc phát hiện và phân đoạn đối tượng, PaliGemma có nhiều khả năng đa dạng và có thể tinh chỉnh để đạt hiệu suất tốt hơn trong các nhiệm vụ cụ thể. PaliGemma, được ra mắt tại sự kiện Google I/O 2024, là một mô hình đa phương thức kết hợp từ hai mô hình nghiên cứu của Google: SigLIP (mô hình thị giác) và Gemma (mô hình ngôn ngữ lớn). Mô hình này bao gồm hai phần: một phần giải mã Transformer cho ngôn ngữ và một phần mã hóa hình ảnh Vision Transformer. PaliGemma có thể nhận đầu vào là hình ảnh và văn bản, sau đó tạo ra văn bản làm đầu ra.
PaliGemma xây dựng dựa trên thành phần chính bao gồm :
- mô hình thị giác SigLIP
- mô hình ngôn ngữ Gemma
=> Do được kết hợp từ cả 2 model ngôn ngữ-thị giác nên PaliGemma chấp nhận cả đầu vào văn bản và hình ảnh. Điều này cho phép mô hình thực hiện hàng loạt các nhiệm vụ như phát hiện và phân đoạn đối tượng, trả lời câu hỏi trực quan, tạo chú thích cho hình ảnh và video ngắn, và đọc văn bản.
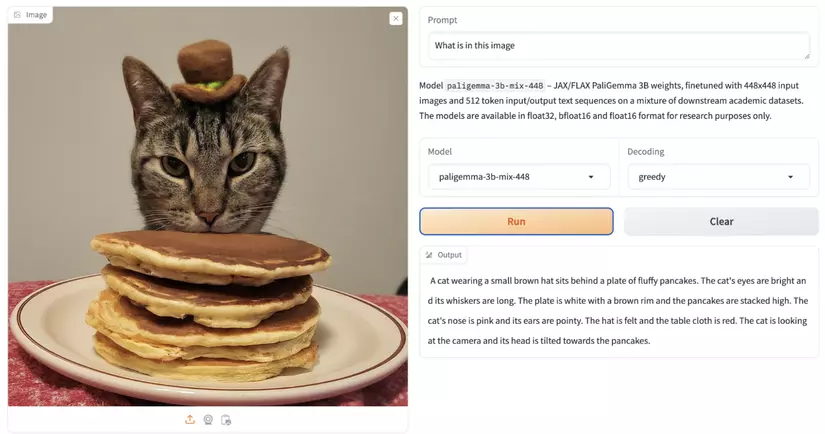
PaliGemma đã được huấn luyện trước trên các tập dữ liệu WebLI, CC3M-35L, VQ²A-CC3M-35L/VQG-CC3M-35L, OpenImages, và WIT.
Google cho biết mô hình này “không được thiết kế để sử dụng trực tiếp, mà để chuyển giao (bằng cách finetuning) cho các nhiệm vụ cụ thể sử dụng cấu trúc gợi ý tương tự.” Điều này có nghĩa là hiệu suất cơ bản mà chúng ta có thể quan sát được từ trọng số của mô hình chỉ đủ để dùng ở một khía cạnh nhất định nào đó, để sử dụng cho một nhiệm vụ nào đó chuyên biệt chúng ta nên Finetuning lại model để mô hình cho ra hiệu suất tốt nhất.
2. Kiến trúc
Như đã nói ở phần giới thiệu PaliGemma sử dụng hai thành phần chính:
- bộ mã hóa hình ảnh SigLIP : Đây là một bộ mã hóa hình ảnh mạnh mẽ, được huấn luyện bằng cách so sánh đối chiếu (contrastively trained). SigLIP cạnh tranh với CLIP của OpenAI bằng cách sử dụng hàm mất mát sigmoid thay vì hàm mất mát softmax cross entropy như CLIP. Do sigmod đơn giản hơn và chi phí tính toán ít hơn nên SigLIP lựa chọn sigmod thay cho cross entropy.
- Mô hình ngôn ngữ Gemma 2B : Đây là một mô hình chỉ có bộ giải mã, khích thước nhỏ gọn. Được sử dụng để mã hóa văn bản đầu vào và xử lý tất cả các token. Bộ mã hóa của Gemma có 256.000 token và PaliGemma mở rộng từ vựng này :
- 1024 mục đại diện cho tọa độ trong không gian hình ảnh chuẩn hóa (ví dụ: loc0000, …, loc1023)
- 128 mục (ví dụ: seg000, …, seg127) từ bộ mã hóa hình ảnh (vector quantized visual auto-encoder) dùng để phân đoạn ảnh.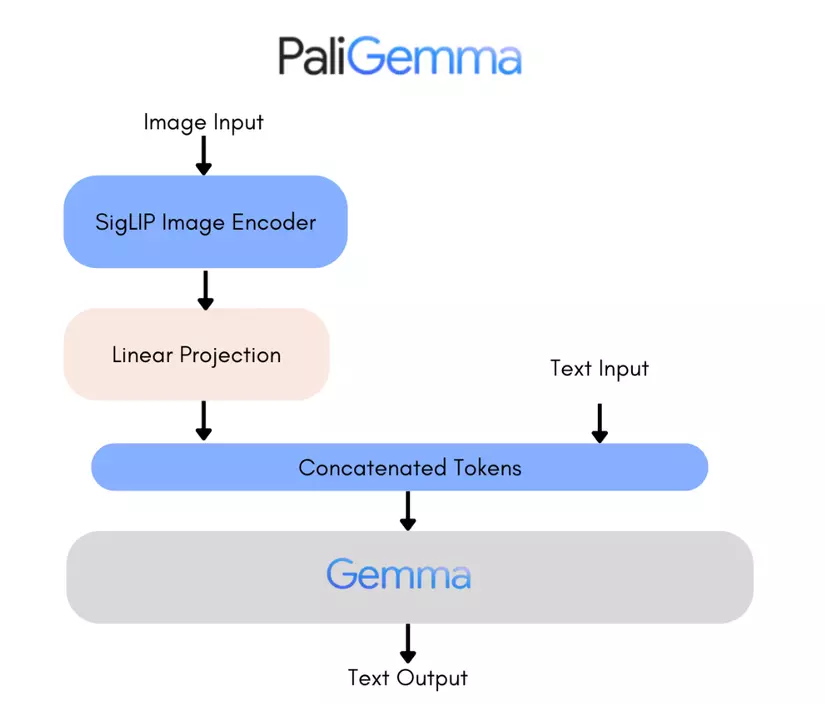
2. Cách hoạt động của PaliGemma
PaliGemma sử dụng bộ giải mã dựa trên transformer của Gemma, tương tự như bộ giải mã transformer gốc của Vaswani (2017), nhưng có một số cải tiến hiện đại:
- Multi-head/multi-query Attention: Giúp mô hình tập trung vào nhiều phần khác nhau của đầu vào.
- Rotary positional embeddings: Giúp mô hình hiểu vị trí của các từ hoặc token trong câu.
- GeGLU thay thế ReLU
- Chuẩn hóa RMS (RMSNorm): Giúp mô hình ổn định hơn trong quá trình huấn luyện.
Quy trình hoạt động của PaliGemma:
- Đầu vào : Mô hình nhận đầu vào là một hoặc nhiều hình ảnh và một đoạn văn bản.
- Xử lý hình ảnh: Hình ảnh được chuyển đổi thành các "soft tokens" (dạng biểu diễn số) bằng bộ mã hóa SigLIP.
- Xử lý văn bản: Đoạn văn bản (gọi là "prefix") được chuyển đổi thành các token (đơn vị nhỏ hơn của văn bản) bởi bộ mã hóa của Gemma.
- Kết hợp: Các token văn bản và các token hình ảnh được nối lại với nhau, với token văn bản ở phía trước.
- Giải mã: Tất cả các token này được đưa vào bộ giải mã Gemma, bộ giải mã này sẽ tạo ra văn bản đầu ra (gọi là "suffix") theo kiểu tự hồi quy, tức là từng bước dự đoán từ tiếp theo dựa trên những từ đã có
Nói cách khác, PaliGemma có thể nhận đầu vào là hình ảnh và văn bản, sau đó kết hợp chúng lại để tạo ra văn bản đầu ra bằng cách hiểu và phân tích cả hai loại đầu vào đó.
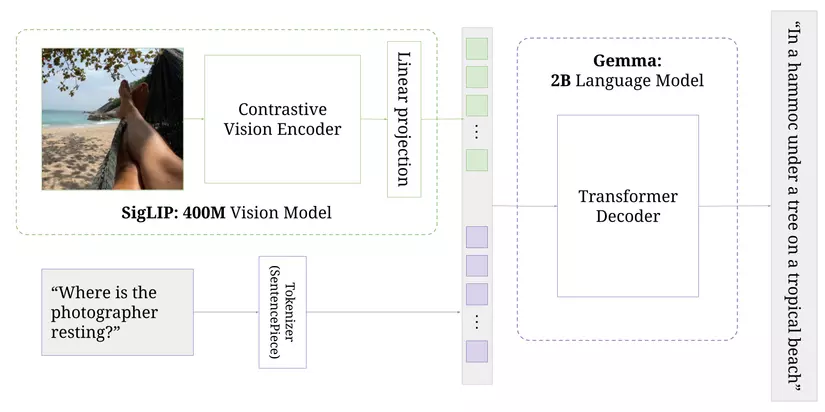
3. Quy trình huấn luyện
Quá trình huấn luyện của PaliGemma bao gồm nhiều giai đoạn, tương tự như PaLI-3. Dưới đây là cách mô tả về từng giai đoạn:
- Uni-Modal Pre-Training: PaliGemma sử dụng các mô hình SigLIP và Gemma đã được huấn luyện trước trên dữ liệu chỉ về hình ảnh hoặc văn bản.
- Multi-Modal Pre-Training: Sau đó, mô hình combined PaliGemma được huấn luyện trên dữ liệu chứa cả hình ảnh và văn bản. Ở giai đoạn này, hình ảnh đầu vào có độ phân giải 224x224 và văn bản có độ dài 128 token. Kết quả mô hình cơ bản đã được huấn luyện và sẵn sàng cho bước kế tiếp.
- High-Resolution Pre-Training: Mô hình cơ bản từ giai đoạn trước được huấn luyện thêm với hình ảnh có độ phân giải cao hơn (448x448 và 896x896) và văn bản dài hơn (512 token). Dữ liệu huấn luyện vẫn giống như trước, nhưng tập trung nhiều hơn vào các hình ảnh có độ phân giải và text có độ dài chuỗi lớn.
- Fine-Tuning: Mô hình sau khi huấn luyện ở hai giai đoạn trước được điều chỉnh để phù hợp với các nhiệm vụ cụ thể.
4. Hướng dẫn Finetuning PaliGemma
4.1 Dataset format
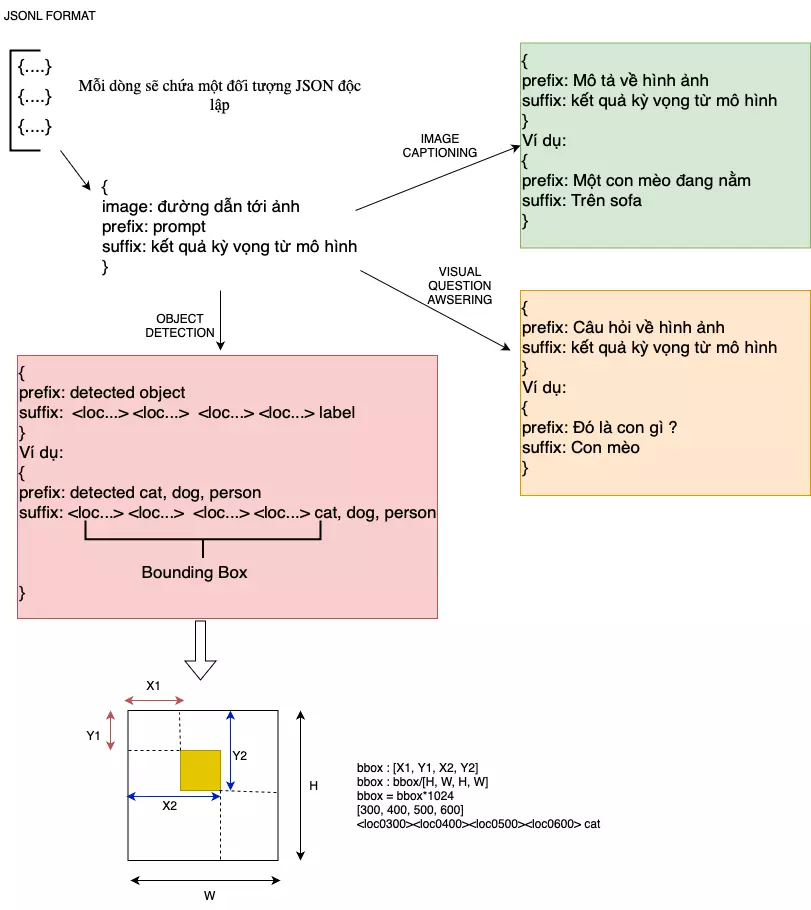
Để finetuning PaliGemma cho tập dữ liệu cụ thể, trước tiên bạn cần chuyển đổi các tập anotation của thành tệp JSON Lines (.jsonl), trong đó mỗi dòng văn bản chứa một đối tượng JSON với các cặp key-value :
Image : đường dẫn tới ảnh.
Prefix (prompt): là đoạn văn bản được cung cấp trước khi mô hình bắt đầu tạo ra phản hồi. Nó thiết lập ngữ cảnh cho mô hình và cung cấp thông tin cần thiết để mô hình hiểu và tiếp tục văn bản một cách hợp lý.
Suffix (expected respone/ground truth description): là đoạn văn bản xuất hiện sau khi mô hình tạo ra một đoạn văn bản nào đó. Nó có thể được sử dụng để cung cấp thêm ngữ cảnh hoặc kiểm tra độ chính xác của văn bản được tạo ra.
Tuỳ vào đặc thù của mỗi bài toán prefix và suffix sẽ được hiểu theo một nghĩa sao cho thích hợp, mình đã vẽ hình tổ chức dữ liệu của Paligemma như hình dưới cho mọi người dễ hình dung về 2 khái niệm này :
4.2 Caption-based dataset
Để tinh chỉnh PaliGemma nhằm trích xuất văn bản cho các trường hợp sử dụng như tạo chú thích cho hình ảnh (image captioning) hoặc trả lời câu hỏi (visual question-answering - VQA), bạn cần sử dụng các "prefix" và "suffix" tương ứng để mô hình học . Dưới đây là hướng dẫn chi tiết với từng tác vụ :
1. Image Captioning:
Prefix: Đây là phần đầu của câu mô tả, thiết lập nhiệm vụ mà bạn muốn mô hình thực hiện. Đối với việc tạo chú thích cho hình ảnh, bạn có thể chuẩn hóa prefix thành "caption". Nếu tập dữ liệu của bạn là đa ngôn ngữ, bạn có thể thêm ngôn ngữ vào prefix, ví dụ: "caption en" cho chú thích tiếng Anh.
Suffix: Chứa các chú thích chính xác mà bạn mong muốn mô hình tạo ra.

2. Visual Question-Answering (VQA)
Prefix: Trong VQA, prefix có thể chứa câu hỏi về hình ảnh. Điều này giúp mô hình biết rằng nhiệm vụ là trả lời câu hỏi dựa trên nội dung hình ảnh.
Suffix: Chứa câu trả lời đúng cho câu hỏi dựa trên hình ảnh.
3. Thách thức Khi huấn luyện các mô hình như PaliGemma việc sử dụng token loss đôi khi khiến mô hình có thể không học được một cách hiệu quả từ dữ liệ, đó là khi các chú thích hay câu trả lời có sự tương đồng cao ở mức từng từ (token), nhưng lại khác nhau về ý nghĩa quan trọng.
Ví dụ: Trong VQA, một câu trả lời có thể là "phía trên-bên phải" và câu trả lời khác có thể là "phía dưới-bên trái". Mặc dù chúng có những từ giống nhau nhưng ý nghĩa lại hoàn toàn khác nhau. Token loss có thể không nhận diện được sự khác biệt quan trọng này và do đó mô hình có thể dự đoán sai về các chi tiết mang ý nghĩa về không gian, vì nó chỉ quan tâm đến việc đúng một phần token chứ không phải ý nghĩa toàn bộ câu trả lời.
=> Do token loss không đủ nhạy cảm để phân biệt các sự khác biệt ý nghĩa, mô hình có thể dễ dàng bị dẫn sai hướng và chỉ tập trung vào các mẫu token phổ biến thay vì hiểu sâu hơn về nội dung cụ thể mà nó cần học.
4.3 Object detection dataset
Trong tác vụ phát hiện đối tượng, bạn có thể chuẩn hóa các prefix như là "detect |CLASS|", với dấu chấm phẩy phân tách các lớp trong trường hợp đa lớp - "detect |CLASS1| ; |CLASS2| ; …". Suffix sẽ bao gồm một tập hợp bốn token vị trí mô tả tọa độ bounding box và một token cho mỗi tên lớp đối tượng mà mỗi đối tượng cần phát hiện trong hình ảnh, với định dạng như sau:
"<locXXXX><locYYYY><locXXXX><locYYYY> |CLASS|".

1. Thách thức
PaliGemma hoạt động tốt trong những trường hợp mà mỗi hình ảnh chỉ có một hoặc một vài đối tượng cần phát hiện. Tuy nhiên, Khi tăng số đối tượng được gán nhãn trên mỗi hình ảnh thì hiệu suất của mô hình giảm đáng kể. Điều này có thể được giải thích bởi sự khác biệt về hàm mất mát giữa PaliGemma và các mạng CNN truyền thống. Trong tác vụ phát hiện đối tượng điển hình sử dụng CNN, hàm mất mát tính đến các yếu tố như sự chồng chéo (IoU) giữa các hộp giới hạn thực tế và dự đoán. Trong trường hợp của PaliGemma, hàm mất mát của token được sử dụng, trong đó các token <loc> được so sánh giữa thực tế và dự đoán. Do vị trí của token ảnh hưởng đáng kể đến hàm mất mát của token, hàm mất mát của mô hình (trong trường hợp này là token loss) sẽ tăng lên đáng kể mặc dù đã nhận diện đúng và chính xác tất cả các trường hợp.
Ví dụ, nếu độ dài token tối đa đặt là 256, mô hình chỉ có thể đầu ra tối đa 42 đối tượng. Đối với nhiệm vụ phân đoạn, nó chỉ có thể tạo ra tối đa 11 mặt nạ đối tượng. Do đó, nếu các chú thích thực tế vượt quá giới hạn token này, mô hình không thể tái tạo kết quả đó một cách chính xác trong dự đoán của nó. Một giải pháp đơn giản là tăng độ dài token đầu ra tối đa. Tuy nhiên, điều này đi kèm với một số hạn chế: nó đáng kể tăng tiêu thụ VRAM (bộ nhớ video) của mô hình. Sự tăng nhu cầu tài nguyên này không phù hợp với việc triển khai thực tế và các trường hợp giới hạn bộ nhớ.
4.4 Segmentation dataset
Việc finetuning PaliGemma cho các nhiệm vụ phân đoạn có cấu trúc tổng thể tương đối giống với các nhiệm vụ phát hiện đối tượng. Mỗi đối tượng trong các ví dụ huấn luyện được gán một lớp hoặc định danh riêng, cùng với bốn mã thông báo vị trí mô tả tọa độ của hộp giới hạn của đối tượng. Sự khác biệt chính nằm ở việc mô hình phải học thêm 16 mã thông báo phân đoạn, biểu thị mặt nạ nhị phân phù hợp trong hộp giới hạn được mô tả bởi 4 mã thông báo vị trí. Có 128 mã thông báo phân đoạn có thể được sử dụng.
Các mã thông báo được mã hóa từ bộ mã hóa có thể được ánh xạ thành các mã thông báo phân đoạn theo định dạng sau:
Đối với mỗi đối tượng có mask, định dạng sẽ có dạng như sau, được phân tách bằng dấu chấm phẩy:
<locXXXX><locXXXX><locXXXX><locXXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX><segXXX> [CLASS]
Trong đó:
- <locXXXX> biểu thị các token biểu diễn vị trí bounding box.
- <segXXX> biểu thị các token phân đoạn biểu diễn binary mask.
- [CLASS] cho biết lớp của đối tượng.

1. Thách thức
-
Tính mất mát và tính black box của quá trình mã hóa và giải mã binary mask: Quá trình này không chỉ đơn giản là ánh xạ từ token sang binary mask và ngược lại mà nó còn mất mát thông tin. Không có cách rõ ràng để hiểu được cách các token ẩn tương tác với nhau và cách từng token đóng góp vào việc tạo ra binary mask. Do đó, PaliGemma học để tạo ra các mặt nạ phân đoạn không có sự hiểu biết cơ bản về không gian thị giác máy tính.
-
Giới hạn của codebook ẩn: Codebook ẩn trong PaliGemma được thiết kế và lựa chọn dựa trên các thử nghiệm thực tế, không có đảm bảo rằng nó sẽ chính xác tái tạo lại các binary mask ban đầu. Việc giải mã từ các token lại binary mask có thể dẫn đến kết quả gần đúng nhưng thường không hoàn toàn chính xác. Điều này có thể dẫn đến lỗi pixel và nhiễu xung quanh binary mask ban đầu khi được chuyển đổi thành và từ các token phân đoạn.
Note : codebook được sử dụng để biểu diễn các đặc trưng của mặt nạ nhị phân (binary masks). Codebook ở đây là một tập hợp các vector, mỗi vector đại diện cho một binary mask có thể có. Khi một binary mask được mã hóa, nó sẽ được ánh xạ tới một trong các vector trong codebook để biểu diễn. Quá trình này giúp giảm thiểu dung lượng lưu trữ và tối ưu hóa các phép tính khi xử lý dữ liệu mask trong các tác vụ phân đoạn hình ảnh.
Sau khi bạn đã tạo được tệp JSONL chứa các annotation và các hình ảnh huấn luyện bạn đã có thể tiến hành finetuning mô hình PaliGemma theo notebook này: https://github.com/google/generative-ai-docs/blob/main/site/en/gemma/docs/paligemma/fine-tuning-paligemma.ipynb
All rights reserved
