Giới Thiệu về Mem0: Xây dựng AI Agents với Long-term Memory
1. Giới Thiệu
Các Large Language Models (LLMs) như GPT-4, Claude, hay Gemini đã cho thấy sức mạnh vượt trội trong việc tạo ngôn ngữ tự nhiên. Tuy nhiên, một điểm yếu cố hữu vẫn tồn tại: chúng không có trí nhớ dài hạn thực sự. Mỗi khi vượt quá giới hạn context window (cửa sổ ngữ cảnh) vượt quá giới hạn chúng sẽ trở nên quá tải, dẫn đến suy giảm hiệu suất và tính mạch lạc, thậm chí mọi thông tin trước đó đều bị “reset” . Điều này khiến AI agents trở nên đãng trí, không thể duy trì sự nhất quán trong các cuộc trò chuyện kéo dài nhiều ngày hay nhiều phiên. Hãy hình dung thế này: bạn đang trò chuyện với một người bạn mới. Bạn kể rằng mình ăn chay và không dùng sữa. Một lát sau, khi bạn hỏi về gợi ý bữa tối, người bạn đó lại đề xuất món gà rán. Điều này không chỉ gây khó chịu mà còn phá vỡ lòng tin. Đó chính xác là những gì xảy ra với các tác nhân AI hiện tại thiếu bộ nhớ dài hạn, bền bỉ. Thông tin quan trọng về người dùng bị "quên" khi nó trôi ra khỏi cửa sổ ngữ cảnh, dẫn đến trải nghiệm người dùng không nhất quán và thiếu tin cậy. Để giải quyết vấn đề này chúng ta sẽ nghĩ tới giải pháp chỉ cần dùng context window lớn là được mà tuy nhiên giải pháp không chỉ đơn giản là một cửa sổ ngữ cảnh rộng hơn hay một hệ thống RAG tốt hơn mà là một sự suy nghĩ lại cơ bản về cách một tác nhân AI ghi nhớ, học hỏi và thích nghi.
2. Tại Sao "Cửa Sổ Ngữ Cảnh Dài Hơn" Không Phải Là Giải Pháp Ưu Tiên?
Chắc hẳn nhiều người sẽ nghĩ: "Vậy thì hãy làm cho cửa sổ ngữ cảnh dài hơn!". Đúng là các mô hình như GPT-4 (128K tokens), Claude 3.7 Sonnet (200K), hay Gemini (10M) đã mở rộng đáng kể giới hạn này. tuy nhiên điều này sẽ chỉ là làm chậm lại chứ không giải quyết được vấn đề cơ bản. Có hai lý do chính giải thích cho điều này:
- Khả năng mở rộng: Trong thực tế, các cuộc trò chuyện ý nghĩa có thể kéo dài hàng tuần hoặc hàng tháng. Lịch sử trò chuyện này chắc chắn sẽ vượt quá ngay cả những giới hạn ngữ cảnh lớn nhất.
- Tính liên tục và chọn lọc: Ví dụ một người dùng có thể đề cập sở thích ăn chay của mình, sau đó trò chuyện hàng giờ về các nhiệm vụ lập trình, rồi mới quay lại câu hỏi về bữa tối. Trong tình huống này, thông tin quan trọng sẽ bị "chôn vùi" giữa hàng ngàn token không liên quan. Hơn nữa, việc chỉ đơn thuần trình bày ngữ cảnh dài hơn không đảm bảo rằng LLM sẽ truy xuất hoặc sử dụng thông tin cũ một cách hiệu quả, vì cơ chế Attention của chúng có thể suy giảm đối với các token ở xa.
Để thực sự xây dựng các tác nhân AI đáng tin cậy, chúng ta cần các hệ thống bộ nhớ có khả năng chọn lọc, lưu trữ, củng cố và truy xuất thông tin quan trọng một cách thông minh, giống như cách bộ não con người hoạt động. Đây chính là lý do khiến các memory framework ra đời.
3. Một Số Memory Framework phổ biến
Mình sẽ giới thiệu qua về một số memory framework phổ biến để các bạn nắm được tư tưởng , ưu nhược điểm của các framework :
3.1 Memp – Trí nhớ thủ tục (Procedural Memory)
Phát triển bởi Đại học Chiết Giang và Alibaba. Memory được xây dựng từ “trajectories” (kịch bản hành vi), lưu dưới dạng từng bước hoặc script. Khi gặp nhiệm vụ mới, agent truy xuất kinh nghiệm cũ để tham khảo. Cuối cùng Agent sẽ cập nhật memory dựa trên các thất bại: học từ sai, sửa, tránh phải làm lại từ đầu.
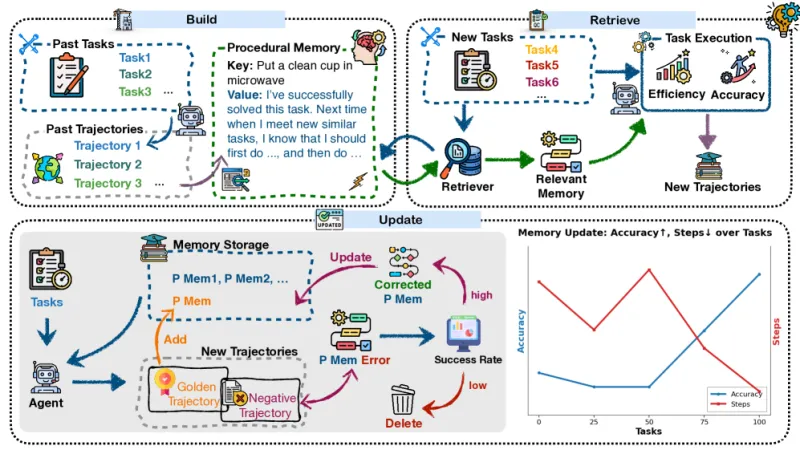
Ý tưởng:
- Procedural Memory xây dựng trên tư tưởng chính là “làm thế nào” để hoàn thành một tác vụ.
- Thay vì chỉ nhớ thông tin tĩnh, Memp cho agent khả năng học hỏi từ kinh nghiệm trước đó.
- Mỗi lần tác nhân thực hiện một nhiệm vụ, toàn bộ quá trình (trajectory) được lưu lại:
- Có thể là từng bước hành động chi tiết.
- Hoặc được trừu tượng hóa thành một script cấp cao.
- Điểm mạnh: Memp có cơ chế học từ thất bại – agent sửa và cập nhật memory, giúp agent thích ứng nhanh hơn.
Cơ chế hoạt động:
- Build (Xây dựng): tạo memory từ các hành động đã thực hiện.
- Retrieve (Truy xuất): khi gặp nhiệm vụ mới, agent tìm lại trajectory phù hợp để tham khảo.
- Update (Cập nhật): nếu thất bại, agent điều chỉnh memory để tránh lặp lại sai lầm.
Ưu điểm:
- Học từ sai lầm → không cần “làm lại từ đầu” mỗi lần.
- Khả năng chuyển giao: procedural memory có thể tạo bằng model mạnh rồi dùng lại cho model nhỏ hơn giúp tiết kiệm chi phí.
Nhược điểm:
- Chỉ tập trung vào “cách làm”, chưa mạnh trong việc lưu lại thông tin ngữ cảnh dài hạn (ai, cái gì, khi nào).
3.2. Mem0 – Trí nhớ khai báo (Declarative Memory)
Tập trung vào việc nhớ “điều gì đã xảy ra". Mục tiêu để duy trì sự nhất quán trong hội thoại và theo dõi trạng thái kiến thức của người dùng. Hoạt động theo pipeline gồm 2 giai đoạn:
- Extraction: trích xuất “candidate facts” từ hội thoại mới.
- Update: so sánh với memory hiện có, rồi quyết định ADD, UPDATE, DELETE, NOOP.
Ưu điểm
- Bộ nhớ có cấu trúc, dễ truy vấn.
- Hiệu quả chi phí: giảm token cost so với full-context.
- Nhanh: latency giảm
Hạn chế
- Phụ thuộc nhiều vào chất lượng LLM trong bước update (nếu LLM đánh giá sai, memory sẽ bị lỗi).
- Mạnh về thông tin tĩnh, nhưng chưa tối ưu cho procedural tasks (cách làm).
3.3. A-MEM – Trí nhớ tự tổ chức (Self-Organizing Memory)
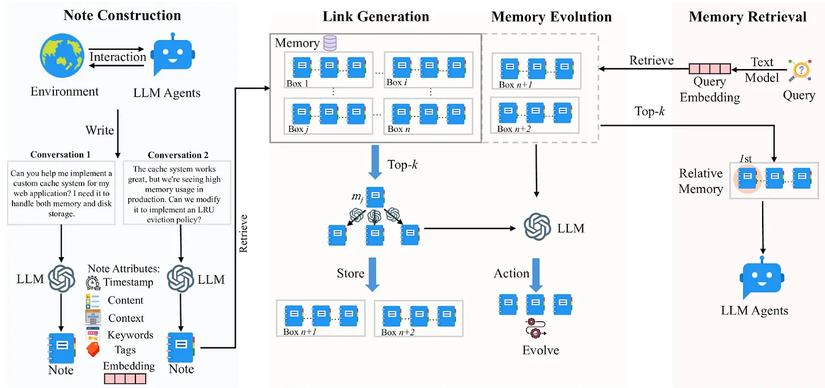 Ý tưởng:
Ý tưởng:
-
A-MEM đưa trí nhớ lên một cấp độ mới: agent tự tổ chức kiến thức mà không cần quy tắc cứng nhắc.
-
Giống như bộ não con người: liên tục ghi chú, phân loại, và tìm ra mối liên hệ mới.
Cơ chế hoạt động:
- Tạo memory note:
- Mỗi tương tác → sinh ra một “ghi chú” chứa thông tin + metadata (thời gian, từ khóa).
- Liên kết memory (2 bước):
- Embedding retrieval: tìm các memory có liên quan.
- LLM reasoning: phân tích nội dung để quyết định liên kết nào quan trọng → không chỉ dựa vào cosine similarity.
Kết quả: memory tự động hình thành các knowledge graph.
Ưu điểm:
- Khả năng khám phá pattern cao cấp khi memory phình to.
- Tự động thích ứng mà không cần luật cố định.
- Kết hợp ưu điểm của cả procedural và declarative memory.
Hạn chế:
- Chi phí xử lý cao hơn (do cần LLM reasoning mỗi khi liên kết memory).
- Độ phức tạp lớn → khó triển khai ở quy mô lớn nếu chưa tối ưu.
3.4. Zep – Temporal Knowledge Graph Memory
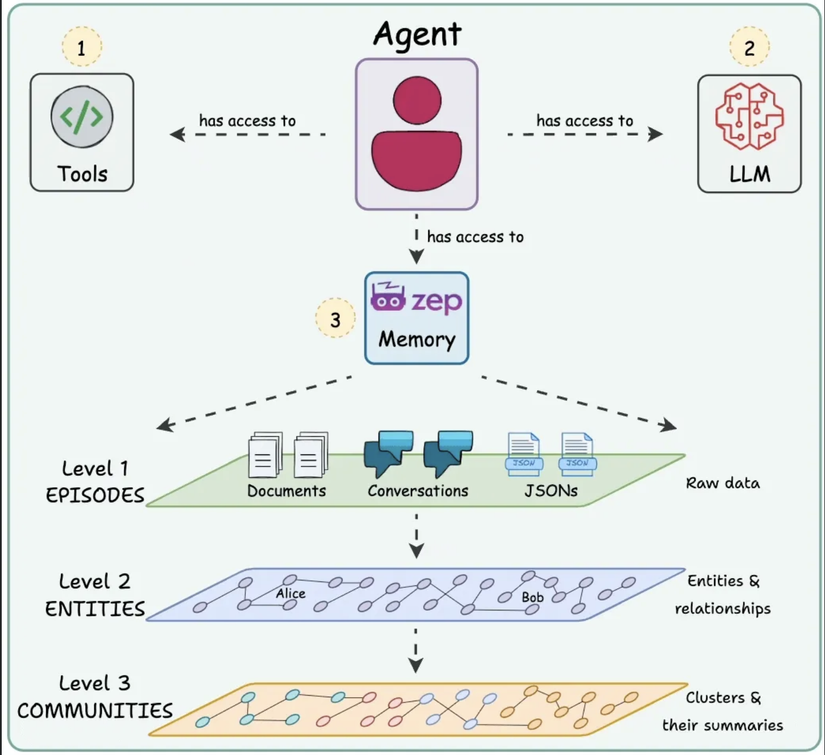
Ý tưởng:
- Nếu Mem0 tập trung vào “chuyện gì đã xảy ra” và Memp tập trung vào “làm thế nào để làm”, thì Zep nhắm tới câu hỏi: “Điều này xảy ra khi nào và nó đã thay đổi ra sao theo thời gian?”
- Nói cách khác, Zep là một kiến trúc trí nhớ dạng đồ thị tri thức có yếu tố thời gian (Temporal Knowledge Graph).
- Nó không chỉ lưu thông tin (facts), mà còn gắn kèm mốc thời gian, trạng thái hiệu lực, và lịch sử thay đổi của những facts đó.
Cơ chế hoạt động:
-
Graphiti Engine (trái tim của Zep):
- Khi agent thu thập dữ liệu (hội thoại, dữ liệu doanh nghiệp), Graphiti sẽ xây dựng một knowledge graph.
- Các entity (người, vật, sự kiện) là node.
- Các quan hệ (sống ở, làm việc tại, thay đổi trạng thái) là edge.
- Mỗi quan hệ đều gắn thêm temporal tag → biết nó bắt đầu khi nào, kết thúc khi nào, và thay thế bởi điều gì.
-
Cập nhật theo thời gian thực:
- Không chạy theo lô (batch) mà cập nhật ngay khi có thông tin mới. Ví dụ: “Lan sống ở Hà Nội từ 2018 đến 2022” → “Lan sống ở TP.HCM từ 2022 đến nay”.
- Graph lưu cả lịch sử lẫn trạng thái hiện tại, nên agent có thể trả lời được cả câu hỏi quá khứ và hiện tại.
-
Truy xuất nhanh:
- Nhờ cấu trúc đồ thị, Zep có thể tìm thông tin theo ngữ cảnh dài hạn với độ trễ <200 ms, phù hợp cho voice assistant hoặc agent thời gian thực. Ưu điểm:
- Nhận thức thời gian (temporal awareness): Lưu giữ lịch sử, không “ghi đè” làm mất dữ liệu cũ.
- Hỗ trợ reasoning phức tạp: Trả lời được câu hỏi như “Ai giữ chức vụ này vào năm 2021?” hay “Quan hệ giữa A và B đã thay đổi thế nào trong 5 năm qua?”.
- Đa dạng nguồn dữ liệu: Kết hợp dữ liệu hội thoại (unstructured) và dữ liệu nghiệp vụ (structured).
- Hiệu suất cao: Benchmark cho thấy Zep vượt MemGPT và baseline trên cả DMR và LongMemEval, giảm tới 90% độ trễ.
Hạn chế:
- Phức tạp triển khai hơn so với Mem0 → cần hạ tầng graph DB mạnh (như Graphiti).
- Chi phí lưu trữ và quản lý cao khi dữ liệu temporal lớn.
- Chưa tối ưu cho procedural tasks (cái này Memp làm tốt hơn).
Như vậy, Zep bổ sung một mảnh ghép rất quan trọng: temporal reasoning, biến agent từ chỗ chỉ “nhớ sự kiện” thành có khả năng theo dõi, phân tích và phản ứng dựa trên sự thay đổi của thế giới theo thời gian được ứng dụng trong các hệ thống Customer Support, Enterprise Agent, Reasoning theo thời gian ví dụ truy vấn multi-hop → “Ai phê duyệt ngân sách năm 2023, và ai thay thế họ trong 2024?”.
==> Tóm lại:
Memp: Trí nhớ thao tác động → thích hợp cho tác vụ thao tác động (procedural tasks), nơi agent cần “biết cách làm” và học từ sai lầm.
Mem0: Trí nhớ khai báo -> agent nhớ “điều gì đã xảy ra”, mạnh trong ghi nhớ dài hạn hội thoại, giúp agent duy trì sự nhất quán qua thời gian dài.
A-MEM: Trí nhớ tự tổ chức → agent tự động phát hiện mối liên hệ và pattern ẩn, nơi memory của agent có thể tự tổ chức và tiến hóa, gần giống cách bộ não con người.
Zep: Trí nhớ theo dòng thời gian → agent không chỉ biết sự kiện, mà còn biết sự kiện đó xảy ra khi nào, kéo dài bao lâu, và thay đổi ra sao theo thời gian.
Do bài viết này mình hướng tới Mem0 là chính nên ở các phần sau mình sẽ chỉ tập trung viết về kiến trúc cũng như cách hoạt động của mem0 nhé.
4. Mem0: Kiến Trúc Bộ Nhớ Khai Báo
Gần đây, Paper Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory đưa ra một giải pháp mới: Mem0 và Mem0g – hai kiến trúc memory-centric cho phép AI agents lưu giữ, tổ chức, và truy xuất trí nhớ lâu dài một cách hiệu quả và có thể triển khai thực tế.

4.1. Mem0: Cơ chế hoạt động
Mem0 là một kiến trúc tập trung vào bộ nhớ có khả năng trích xuất, củng cố và truy xuất thông tin nổi bật một cách linh hoạt từ các cuộc trò chuyện đang diễn ra. Nó nhằm mục đích duy trì tính nhất quán trong các cuộc đối thoại kéo dài qua nhiều phiên. Kiến trúc Mem0 hoạt động theo mô hình xử lý tăng dần, tích hợp liền mạch vào các cuộc trò chuyện. Mem0 được thiết kế như một pipeline gồm hai giai đoạn chính:
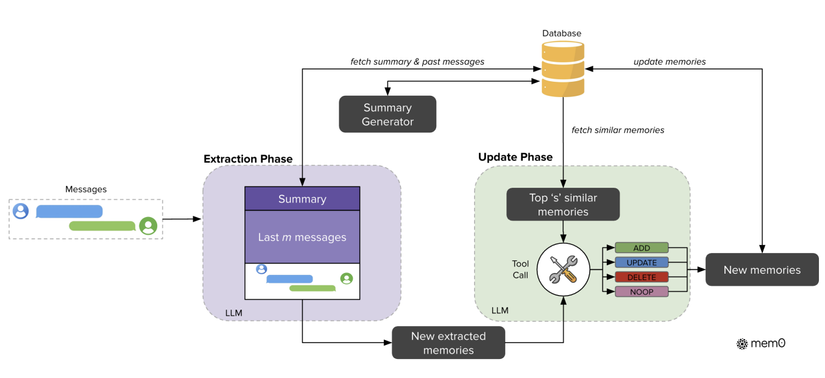
- Extraction Phase (Giai đoạn Trích xuất)
- Đầu vào: Hệ thống bắt đầu từ một cặp tin nhắn mới, gồm tin nhắn trước đó và tin nhắn hiện tại (ví dụ: người dùng hỏi và trợ lý trả lời). Đây được coi là một đơn vị hội thoại hoàn chỉnh.
- Ngữ cảnh: Để hiểu rõ tình huống, hệ thống không chỉ nhìn vào cặp tin nhắn mới mà còn tham chiếu thêm:
- Conversation summary (S): Được cập nhật định kỳ, gói gọn nội dung chính của toàn bộ lịch sử trò chuyện.
- A sequence of recent messages: Một chuỗi các tin nhắn gần đây {mt−m, mt−m+1, ..., mt−2} từ lịch sử cuộc trò chuyện, với m là một siêu tham số kiểm soát cửa sổ thời gian.
- Quá Trình hoạt động: Hệ thống kết hợp cả ba nguồn thông tin (tóm tắt, chuỗi tin nhắn gần đây, và cặp hội thoại mới) thành một prompt đầu vào toàn diện cho LLM.
- LLM sẽ phân tích và trích xuất những “facts” quan trọng từ đoạn hội thoại này.
- Kết quả là một tập hợp “ký ức ứng cử viên” (candidate memories) – những mảnh thông tin có tiềm năng được thêm vào kho trí nhớ lâu dài của agent.
- Update Phase( Giai đoạn Cập nhật)
-
Mục tiêu: Sau khi trích xuất được các “facts ứng cử viên”, hệ thống cần quyết định nên thêm mới, cập nhật, hay loại bỏ chúng trong bộ nhớ để giữ cho cơ sở tri thức vừa nhất quán vừa gọn gàng.
-
Quá trình hoạt động:
- Đánh giá và truy xuất: Với mỗi fact mới, hệ thống tìm trong kho memory hiện tại những bộ nhớ gần nhất về mặt ngữ nghĩa (top-s, ở đây s = 10). Việc này dùng vector embedding để đảm bảo tìm kiếm nhanh và chính xác.
- Thao tác với LLM: Những memory tương tự cùng với fact mới được đưa vào LLM (GPT-4o-mini).LLM sẽ tự suy luận và chọn một trong bốn hành động:
- ADD: Tạo một memory mới nếu chưa có gì tương tự.
- UPDATE: Bổ sung hoặc chỉnh sửa memory cũ để thêm thông tin mới.
- DELETE: Xóa memory cũ nếu nó bị thông tin mới phủ nhận.
- NOOP: Không làm gì nếu fact mới không thật sự quan trọng.
- Thực thi: Kết quả quyết định của LLM được áp dụng vào cơ sở tri thức, đảm bảo memory luôn sạch, chính xác, và cập nhật theo thời gian.
4.2. Mem0g: Bộ nhớ dạng đồ thị tri thức
Mem0g là một phiên bản nâng cao của Mem0, trong đó toàn bộ trí nhớ của agent được tổ chức dưới dạng đồ thị tri thức có nhãn (knowledge graph). Cách tiếp cận này cho phép agent không chỉ lưu giữ sự kiện, mà còn hiểu rõ mối quan hệ giữa các thực thể và cách chúng thay đổi theo thời gian.
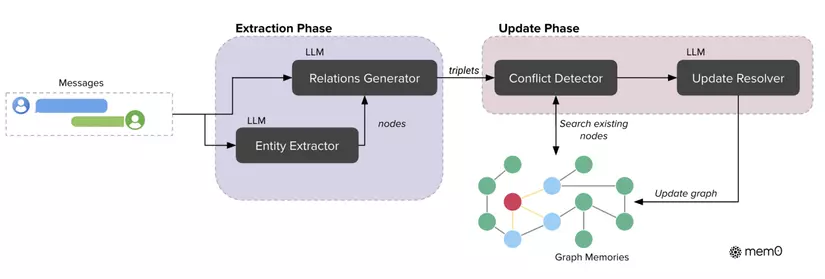
4.2.1 Biểu diễn bộ nhớ
- Nút (Nodes): đại diện cho các thực thể trong hội thoại (người, địa điểm, sự kiện…). Mỗi nút lưu loại thực thể (ví dụ: “Alice” – Con người, “San Francisco” – Thành phố), vector embedding mô tả ý nghĩa ngữ nghĩa, và metadata như timestamp.
- Cạnh (Edges): đại diện cho các quan hệ giữa thực thể, được lưu dưới dạng bộ ba (source, relation, target), ví dụ: (Alice – lives_in → San Francisco).
- Nhãn (Labels): giúp phân loại và gắn ý nghĩa cho các nút, tăng tính rõ ràng trong truy vấn.
4.2.2 Quy trình trích xuất
Mem0g sử dụng LLM để chuyển hội thoại thành đồ thị có cấu trúc qua 2 bước:
- Bước 1: Trích xuất thực thể: Xác định các thực thể quan trọng (người, địa điểm, khái niệm, thuộc tính…).
- Bước 2: Tạo quan hệ: Xây dựng các mối liên kết giữa thực thể, gán nhãn quan hệ phù hợp (ví dụ: “sống ở”, “thích”, “làm việc tại”). Quá trình này kết hợp cả thông tin trực tiếp lẫn ngụ ý từ ngữ cảnh.
4.2.3 Cập nhật và quản lý bộ nhớ
- Với mỗi quan hệ mới, hệ thống kiểm tra xem các nút tương ứng đã tồn tại chưa, sau đó cập nhật hoặc thêm mới.
- Mem0g có cơ chế phát hiện xung đột: nếu thông tin mới phủ nhận thông tin cũ, LLM sẽ đánh dấu quan hệ cũ là “không còn hợp lệ” thay vì xóa hẳn, giúp duy trì khả năng suy luận theo thời gian.
4.2.4 Truy xuất bộ nhớ
Mem0g triển khai hai cách tiếp cận để truy xuất thông tin:
-
Entity-centric: Bắt đầu từ các thực thể trong truy vấn → tìm các nút liên quan trong graph → mở rộng thành subgraph chứa thông tin ngữ cảnh cần thiết.
-
Semantic triplet: Mã hóa toàn bộ truy vấn thành embedding → so khớp với các quan hệ (triplet) trong graph → trả về những quan hệ phù hợp nhất theo mức độ tương tự.
5. Vector Storage & Scalability
Ngoài pipeline trích xuất – cập nhật, Mem0 còn có 2 đặc điểm quan trọng giúp nó phù hợp triển khai thực tế:
- Vector-based Storage: Tất cả memories được lưu dưới dạng vector trong không gian ngữ nghĩa. Điều này cho phép Mem0 nhanh chóng tìm kiếm và truy xuất các thông tin liên quan dựa trên mức độ tương tự, thay vì phải đọc lại toàn bộ lịch sử hội thoại.
- Scalability & Selectivity:
- Khả năng mở rộng: Mem0 chỉ lưu các sự kiện nổi bật (selective extraction), cập nhật không đồng bộ để tránh làm chậm hội thoại, và sử dụng vector DB tối ưu cho dữ liệu lớn.
- Tính chọn lọc: Hệ thống liên tục lọc bỏ thông tin dư thừa, hợp nhất những memory trùng lặp, và điều chỉnh động theo dòng hội thoại. Nhờ vậy, memory luôn gọn gàng và chính xác theo thời gian.
=> Nhờ những đặc tính này, Mem0 vừa nhanh, vừa tiết kiệm chi phí, nhưng vẫn đảm bảo agent có trí nhớ dài hạn đáng tin cậy.
6. Tài Liệu Tham Khảo
All rights reserved
