Giới thiệu về DynamoDB (Phần 1)
Bài đăng này đã không được cập nhật trong 4 năm

Giới thiệu
-
DynamoDB là môt dịch vụ quản lý NoSQL có khả năng đáp ứng hiệu suất cao và nhanh kèm theo khả năng mở rộng. Nếu bạn là một nhà phát triển, bạn có thể sử dụng DynamoDB để tạo ra một bảng có khả năng lưu trữ và truy xuất bất kỳ số lượng dữ liệu, mà vẫn có thể phục vụ cho bất kỳ mức độ request traffic.
-
DynamoDB tự động phân tán dữ liệu và traffic của một bảng ra một số lượng server vừa đủ để có thể xử lý request capacity đặt ra bơi khách hàng và lượng dữ liệu lưu trữ, và đồng thời đảm bảo hiệu suất nhanh và đồng nhất. Tất cả dự liệu được lưu trữ trên SSD và tự động được sao chép ra các vùng sẵn sằng (Availability Zones) trong một khu vực (Region) để cung cấp độ sẵn sàng cao và độ bền của dữ liệu (high availablity and data durability)
-
Nếu bạn là một nhà quản lý dữ liệu, bạn có thể tạo một bảng dữ liệu mới, mở rộng hay thu hẹp request capacity mà không bị giảm hiệu suất, và có thể thây được các thông số qua AWS Management Console. Với DynamoDB, bạn có thể phó thác gánh nặng quản lý và mở rộng dữ liệu cho AWS và không phải lo lắng về việc cung cấp hardware, thiết lập và cài đặt, sao chép dữ liệu.
Làm việc với DynamoDB
1. Bảng trong DynamoDB
- Khi bạn tạo một bảng trong Amazon DynamoBD, bạn cần cung cấp tên bảng (dĩ nhiên rồi) (haha), primary key và giá trị read write throughput. Mỗi item trong bảng có thể có bao nhiêu attributes tùy ý, tuy nhiên có giới hạn 400KB cho dung lượng một item.
- Chỉ định Primary Key: Khi tạo một bảng, thì ngoài việc khai báo tên bảng bạn cần chỉ rõ primary key . Primary key để đảm bảo rằng không có hai items nào trong bảng có cùng primary key. DynamoDB hỗ trợ hai loại primary key sau:
- Hash Primary Key: Chỉ cần một attribute để tạo ra primary key. DynamoDB xây dựng hash index không được sắp xếp cho primary key attribute.
- Hash và Range Primary Key: Cần 2 attributes để tạo ra primary key. Attribute đầu tiền là hash attribute và attribute còn lại là range attribute. DynamoDB xây dựng hash index không được sắp xếp cho hash attribute và range index được sắp xếp cho range attribute. Mỗi item được định danh bởi cặp primary key này. Điều này cho phép 2 items có cùng hash attribute nhưng khác range attribute cùng tồn tại trong một bảng.
- Trong quá trình tạo bảng, bạn chỉ rõ mức têu thụ (throughput) yêu cầu theo đơn vị là capacity unit. Bạn có thể thay đổi (tăng hoặc giảm) chỉ số này qua UpdateTable request
- Strongly consistent: đảm bảo dữ liệu lấy ra là dữ liệu mới nhất
- Eventually consistent: đảm bảo rằng sau này dữ liệu sẽ đồng bộ hết trên phân vùng nhưng không đảm bảo dự liệu trả về vào một thời điểm nhất định là mới nhất
- Read capacity unit - Con số phản ánh số lượng đọc strongly consitent của các item không quá 4KB
- Write capacity unit - Số lượng những lần ghi có dung lượng 1KB mỗi giây. Có nghĩa rằng nếu bạn yêu cầu 10 write capacity units là bạn đang yêu cầu mức tiêu thụ 10 writes với dung lượng 1 KB mỗi giây của bảng đó
DynamoDB sử dụng những capacity unit này để cung cấp tài nguyên đầy đủ cho lượng tiêu thụ yêu cầu.
Một strongly consistent read tương đương 2 evenly consitent read. Xem bảng sau để hiểu hơn
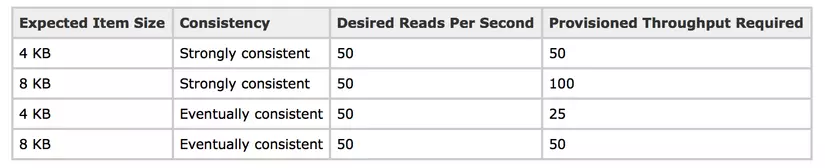
2. Read/Write capacity
-
Nếu bạn không sử dụng
#batch_get_itemthì không thể nhóm các item cho 1 lần đọc dữ liệu. Ví dụ:Bạn sẽ phải mất 10 lần đọc cho 10 item có dung lượng 3KB (tự động làm tròn đến 4KB) nếu sử dụng
#get_itemnhưng nếu sử dụng#batch_get_itemthì sẽ lấy tổng số dung lượng của 10 item và chia cho 4KB, ở đây sẽ là 3KB x 10 / 4KB làm tròn là 8 reads -
Tương tự với write thì cũng có hai hàm để ghi là
#put_itemvà#batch_write_itemnhưng 1 write chỉ nhận 1KB dữ liệu.
3. Secondary index
Để giúp cho việc truy cập dữ liệu, Amazon DynamoDB tạo và quản lý index cho primary key. Việc này giúp cho hệ thống truy cập dữ liệu khá nhanh khi chỉ định primary key. Tuy nhiên, nhiều hệ thống có lẽ sẽ hưởng lợi từ việc có một hoặc hai key thay thế (alternate). Để tăng tốc độ truy cập bạn có thể tạo ra secondary index.
Một secondary index là một cấu trúc dữ liệu chứa tập con của các attributes trong một bảng, cùng với một key thay thế để hỗ trợ cho Query operation. Với một secondary index, các query sẽ không bị giới hạn khi chỉ sử dụng được primary key; bạn có thể truy vấn dữ liệu bằng việc sử dụng key thay thế từ secondary index. Một bảng có thể có nhiều secondary index để hỗ trợ cho nhiều query pattern.
DynamoDB hỗ trợ hai loại index:
- Global secondary index: một loại index có hash và range key khác với hash và range key từ bảng gốc.
- Local secondary index: một loại index mà có hash key trùng với hash key từ bảng gốc và range key là một attribute khác.
4. Query/Scan
- Query:
-
Để thực hiện một query operation bạn cần có primary key và không bắt buộc kèm theo điều kiện cho range key. Query có thể thực hiện trên một bảng hoặc secondary index.
Lưu ý rằng: điều kiện so sánh không thực hiện trên hash key được.
-
Range key phải được thực hiện so sánh như sau:
-
a = b — true if the attribute a is equal to the value b
a < b — true if a is less than b
a <= b — true if a is less than or equal to b
a > b — true if a is greater than b
a >= b — true if a is greater than or equal to b
a BETWEEN b AND c — true if a is greater than or equal to b, and less than or equal to c.
- Tất cả item được trả về sẽ được tính chung là 1 query operation, có nghĩa là với 100 1KB item thì bạn chỉ cần 100 x 1KB / 4KB = 25 reads thay vì 100 reads (yeah)
- Scan:
- Một scan operation có thể thực hiển trên cả bảng và secondary index. Giá trị trả về mặc định của một scan operation là toàn bộ dữ liệu (sohai). Vì vậy hãy thận trọng khi sử dụng scan.
Một số lưu ý về Scan và Query:
- Cả 2 operation đều có dung lượng trả về tối đa là 1MB.
- Query hỗ trợ strongly consistent và eventually consistent trong khi đó Scan chỉ hỗ trợ eventually consistent
- Hãy tránh việc Scan một bảng hoặc index có dung lượng lớn.
- Theo thời gian dung lượng tăng lên thì Scan operation sẽ càng chậm
Dynamodb local
Nếu mà không muốn đăng ký sử dụng DynamoDB bạn có thể sử dụng dynamodb-local để phát triển ứng dụng.
Thêm vào Gemfile:
gem "dynamodb-local"
Nên sử dụng Aws-sdk v2 để phát triển (yeah)
Sau đó mở dynamodb-local bằng terminal
dynamodb-local
Tiếp đến là config để Aws-sdk kết nối tới dynamodb-local
Tạo một file config đặt trong initializers
#config/initializers/
Aws.config.update({
access_key_id: x,
secret_access_key: y,
region: "localhost",
dynamodb: {
endpoint: "localhost:8000"
}
})
Giờ đến việc tạo bảng: Chúng ta sẽ sử dụng #create_table của Dynamodb client trong Aws sdk
#create_table.rb
def create_table
dynamodb = Aws::DynamoDB::Client.new
table_name = "users"
dynamodb.create_table(
table_name: table_name,
attribute_definitions: [
{
attribute_name: :user_id,
attribute_type: :S,
},
{
attribute_name: :city,
attribute_type: :S
}
],
key_schema: [
{
attribute_name: :user_id,
key_type: :HASH
},
{
attribute_name: :city,
key_type: :RANGE
}
],
provisioned_throughput: {
read_capacity_units: 10,
write_capacity_units: 10
}
)
end
Bảng tạo ra có tên là users cùng với:
- hash key là
user_idvà loại dữ liệu là String - range key là
cityvà loại dữ liệu là String - các chỉ số
throughputlà 10 reads/s và 10 writes/s
Đến đây là kết thúc phần 1. Phần tới mình sẽ chia sẽ các best practices khi làm việc với dynamodb (yeah)
References
[1] http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html [2] http://docs.aws.amazon.com/sdkforruby/api/Aws/DynamoDB/Client.html
All rights reserved
