Giới thiệu về coroutines trong Kotlin
Bài đăng này đã không được cập nhật trong 7 năm
Bài viết này mô tả coroutine là gì, vấn đề gì coroutine đang cố gắng giải quyết, và làm thế nào coroutine thực hiện trong bản phát hành 1.1 của Kotlin JVM.
Vấn đề chúng ta đang cố gắng giải quyết là gì?
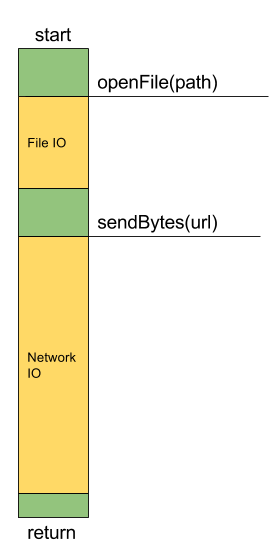
Để giải thích vấn đề là gì và tại sao nó nên được giải quyết, hãy xem xét một ứng dụng web đơn giản. Ứng dụng này chỉ nhận được yêu cầu, đọc tệp cục bộ, tải tệp lên một số máy chủ và trả về URL máy khách của tệp được tải lên. Tất nhiên, đây không phải là một ứng dụng thực sự, nhưng hãy tập trung vào ý tưởng chứ không phải là chức năng. Hình ảnh dưới đây cho thấy ứng dụng giả định của chúng tôi có thể hoạt động như thế nào trong chế độ một luồng. Màu xanh lục cho thấy chuỗi đang chạy, màu vàng - chuỗi đang chờ. Trong trường hợp của chúng tôi, chờ đợi có nghĩa là chờ đợi cho tập tin đọc và chờ đợi để tải lên tập tin. Cho đến nay mọi thứ có vẻ rất tốt, tuy nhiên nó chỉ hoạt động cho một yêu cầu đồng thời. Khi luồng làm việc bận với yêu cầu xử lý A, nó sẽ không thể trả lời yêu cầu B.
Để mở rộng quy mô này, chúng ta có thể tạo luồng mới cho mỗi yêu cầu - nhưng như chúng ta đã biết, tạo luồng là tốn kém và cách tiếp cận này có giới hạn tự nhiên - số lượng luồng OS có thể quản lý đồng thời. Một giải pháp khác là giới thiệu nhóm các quy trình làm việc và sau đó phân phối các yêu cầu giữa chúng. Hình ảnh dưới đây cho thấy cách nhóm 4 luồng xử lý bốn yêu cầu đồng thời bắt đầu với một số độ trễ từ mỗi yêu cầu khác. Vấn đề ở đây xuất hiện khi có yêu cầu thứ 5. Chỉ đơn giản là không có luồng có sẵn để sử dụng mặc dù tất cả 4 luồng trong nhóm đang đợi. Vì vậy, trong tình huống này, toàn bộ hệ thống bị chặn và khách hàng cần đợi lại.
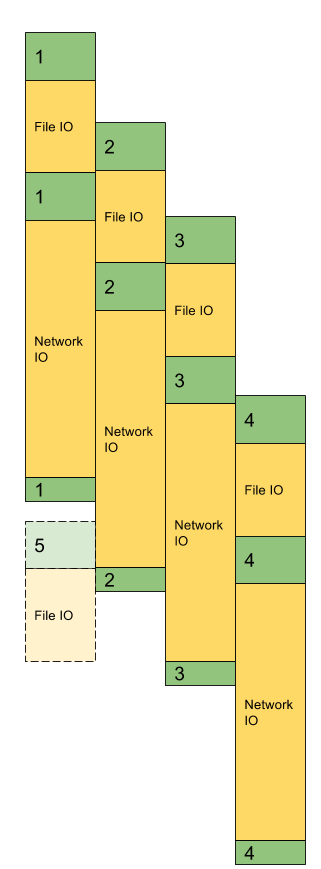
Nhưng nếu chúng ta nghĩ nhiều hơn một chút, câu hỏi chúng ta có thể hỏi - nếu luồng không làm gì ngoài chờ đợi một hoạt động I/O (file hoặc network) - tại sao không chỉ sử dụng lại nó trong một thời gian? Nếu chúng ta chỉ cố gắng loại bỏ tất cả thời gian chờ đợi và sau đó nhóm tất cả các mã thực thi vào đường ống đơn giản, hình ảnh có thể trông như thế này:
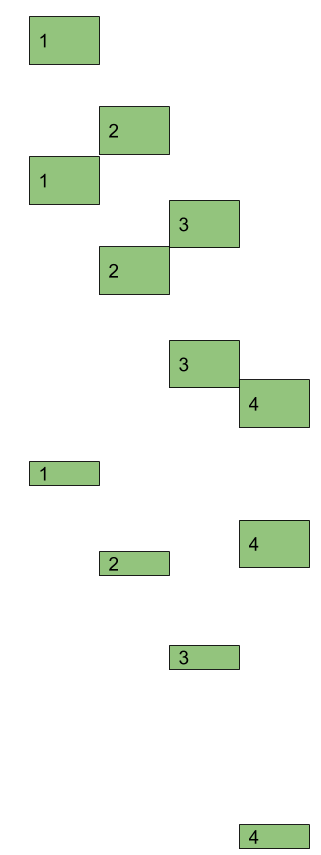
Về cơ bản, mã ứng dụng của chúng tôi cho 4 yêu cầu đồng thời có thể chạy trong một luồng duy nhất.

Lưu ý rằng có hai điểm quan trọng được đánh dấu trong vòng đời của trình xử lý yêu cầu của chúng tôi - yield và continue. Chức năng của chúng tôi bây giờ chia thành nhiều phần và nó có thể giải phóng luồng sau khi chạy một đoạn. Sau đó, nó có thể tiếp tục đoạn tiếp theo sau khi kết quả cần thiết đã sẵn sàng (tệp được đọc hoặc được viết, yêu cầu mạng được gửi hoặc nhận, v.v.). Ngoài ra, chức năng của chúng tôi quyết định khi thực sự mang lại lợi tức - tức là kiểm soát trả lại chuỗi hiện tại cho người khác. Điều này khác với cách hoạt động của lịch trình luồng OS - OS chỉ lấy lại luồng mà không yêu cầu chức năng quá nhiều (đa nhiệm trước). Nhưng các chức năng của chúng tôi đang hợp tác để sử dụng chuỗi có hiệu quả và do đó cách tiếp cận được gọi là đa nhiệm hợp tác hoặc không được ưu tiên. Và nếu bạn vẫn còn ngồi với tôi cho đến thời điểm này - xin chúc mừng, chúng tôi chỉ phát minh ra coroutines! Vì vậy, coroutine là một cơ chế để tối ưu hóa và sau đó thực thi một hàm (chương trình con) theo cách đa nhiệm không được ưu tiên.
Vì vậy, câu trả lời cho câu hỏi trong tiêu đề là - coroutines đang cố gắng giải quyết vấn đề sử dụng hiệu quả tài nguyên (luồng) bằng cách sử dụng đa tác vụ hợp tác.
Tất cả các I/O sau đó chạy ở đâu?
Nó là khá dễ dàng chỉ cần loại bỏ các khối thực thi I/O từ sơ đồ. Tuy nhiên câu hỏi đặt ra là nó thực sự xảy ra trong một hệ thống thực sự ở đâu? Vâng, đây là một câu hỏi và câu trả lời thực sự tốt là "Nó phụ thuộc". Chủ đề của non-blocking I/O là rất lớn và cơ chế phụ thuộc vào thời gian chạy, thư viện, hệ điều hành vv. Một số thư viện I/O sử dụng các nhóm luồng riêng của chúng (libuv, Java NIO), một số sử dụng các tính năng OS ở mức thấp (epoll, kqueue) Điều tốt nhất là đây là chi tiết triển khai và có thể được quản lý bên ngoài mã của ứng dụng.
Coroutine trả về quyền kiểm soát ở đâu?
Bây giờ là lúc để đề cập đến một khái niệm rất quan trọng trong thế giới non-blocking coroutines - event loop (vòng lặp sự kiện). Để hiểu nó, chúng ta cần tự hỏi mình một câu hỏi đơn giản. Khi chúng ta nói 'coroutine trả về sự kiểm soát đối với một chuỗi hiện tại', nó thực sự trả về sự kiểm soát ở đâu? Hãy xem xét một ứng dụng web từ ví dụ của chúng tôi - cần có một đoạn mã mà lắng nghe các kết nối mạng và sau đó gọi các trình xử lý thích hợp. Tương tự trong các ứng dụng giao diện người dùng - sẽ có một chuỗi giao diện người dùng xử lý tất cả các tương tác của người dùng và sau đó gọi một số trình xử lý nhất định làm phản ứng với điều này. Vì vậy, về cơ bản, mục đích chính của mã này cho cả ứng dụng web và giao diện người dùng là chờ sự kiện (yêu cầu http, nút bấm) và sau đó gửi nó đến mã ứng dụng. Và đó là vòng lặp sự kiện là gì - một số mã chạy trong một vòng lặp trong chuỗi ứng dụng chính và gửi các sự kiện. Trong hầu hết các trường hợp, chúng tôi thậm chí không cần quản lý vòng lặp sự kiện theo cách thủ công, các khuôn khổ cơ bản (ví dụ: Spring hoặc JavaFX) tạo và kiểm soát nó.
Làm thế nào để khai báo một coroutine?
Như chúng tôi đã tìm thấy ở trên, các coroutine cần hợp tác để sử dụng hiệu quả luồng mà họ đang chạy. Để đạt được điều này, họ có thể tạm đình chỉ (và kiểm soát yield) và tiếp tục (continue) thực hiện sau. Và câu hỏi thực tế tiếp theo là - làm thế nào trình biên dịch có thể 'cắt' chức năng thành các khối, còn được gọi là sự tiếp tục? Vâng, có rất ít cách để làm điều đó.
-
Manual: Để làm cho cuộc sống của trình biên dịch dễ dàng hơn, một nhà phát triển có thể chăm sóc việc xây dựng và nối tiếp chuỗi. Cách phổ biến để làm điều đó là sử dụng callback bằng cách đơn giản cung cấp một hàm để gọi khi hoạt động I/O hoàn tất. Vì vậy, mã có thể trông như thế này:
fun handler() { val promise = Promise() openFile(url, file -> { sendBytes(file, image_url -> { d.resolve(image_url) }) }) return promise }Vẫn không chính xác những gì chúng ta cần, mã rất khó đọc và bảo trì. Sử dụng promises và xây dựng một chuỗi cuộc gọi với when(...) có thể giúp, nhưng vẫn không hoàn hảo. Điều tồi tệ nhất về nó là thay vì mã lệnh bắt buộc tuyến tính, chúng tôi mã hóa với các kết hợp callbacks.
-
Implicit: Chúng ta có thể giả định rằng bất kỳ hàm gọi yields. Trong trường hợp này, phương thức hàm sẽ có mã tuyến tính. Cách tiếp cận này có những ưu điểm nhất định, nhưng khó thực hiện hơn trong thời gian chạy, vì đôi khi cuộc gọi hàm không phải là chỉ báo tốt nhất mà hàm sẽ trả về quyền kiểm soát đối với luồng. Ví dụ, goroutines trong Golang sử dụng cách tiếp cận này.
-
Explicit: Phương pháp này bao gồm sử dụng từ khóa ngôn ngữ đặc biệt để cung cấp cho trình biên dịch một gợi ý - "đây là một điểm mà bạn có thể trích xuất tiếp tục". Các ngôn ngữ như C # (từ khóa
async) và Kotlin (xem chi tiết bên dưới) sử dụng phương pháp này. Mã của chúng tôi có thể trông giống như sau:fun handler() { val file = openFile(url) val image_url = sendBytes(file) return image_url } ... async fun openFile(url) { ... } async fun sendBytes(file) { ... }
Coroutines trong Kotlin
Bây giờ khi chúng ta biết coroutine là những gì, hãy nhìn vào cách thực hiện của Kotlin. Kotlin sử dụng từ khóa suspend để xác định chức năng bị treo. Vì vậy, nếu chúng ta viết lại mã ví dụ của chúng ta vào nguồn Kotlin thực, nó sẽ như thế này:
fun handler(): String {
val file = openFile(url)
val image_url = sendBytes(file)
return image_url
}
...
suspend fun openFile(url) { ... }
suspend fun sendBytes(file) { ... }
Và bây giờ là lúc nói về vẻ đẹp của việc thực hiện các coroutines của Kotlin. Bí quyết là trình biên dịch Kotlin chỉ quan tâm đến bước đầu tiên - tự động trích xuất liên tục từ mã chức năng và tạo một set của lớp kotlin.experimental.coroutines.Continuation. Làm thế nào và ở đâu để chạy các phần nối tiếp này được quản lý bởi việc triển khai runtime!
Về cơ bản, theo mặc định, Kotlin không buộc một nhà phát triển sử dụng thời gian chạy cụ thể cho coroutines (như C # làm với Task Parallel Library, một phần của .NET) nhưng sẽ uỷ nhiệm thực hiện một coroutine cho thư viện của bên thứ ba. Tuy nhiên nó vẫn làm công việc dơ bẩn của việc tách một mã chức năng thành các khối để nhà phát triển chỉ có thể viết mã lệnh bắt buộc tuyến tính mà không cần gọi lại. Theo mặc định, Kotlin cung cấp coroutines runtime của riêng nó - kotlinx.experimental.coroutines (lưu ý x trong tên gói gốc).
Contexts
Và chúng ta vừa nói về các coroutine đơn luồng. Tuy nhiên có giới hạn rằng mỗi lần tiếp tục (hàm ‘chunk’) sẽ chạy trên cùng một luồng. Như kotlinx.coroutines quản lý state của coroutines này khá tốt, coroutine chính nó có thể chạy trên đầu của thread pool! Để đạt được điều này, Kotlin sử dụng contexts. Để biết thêm về nó, vui lòng tham khảo tài liệu chính thức của Kotlin - https://github.com/Kotlin/kotlinx.coroutines/blob/master/coroutines-guide.md
Đây có phải chỉ là về IO?
Có và không. Có - bạn có thể sử dụng coroutines cho bất kỳ mã người dùng nào. Và không - không có vòng lặp sự kiện bên ngoài cho IO, và chạy các hoạt động CPU bị ràng buộc trong luồng coroutines pool sẽ bị cạn kiệt nhanh chóng và toàn bộ hệ thống bị chặn.
Bài viết được dịch từ: http://blog.alexnesterov.com/post/coroutines/
All rights reserved
