Giải thuật Adaboost ứng dụng trong nhận dạng biển số xe(Data Mining)
Bài đăng này đã không được cập nhật trong 7 năm
Mở đầu
Xin chào các bạn như mọi lần mình chia sẻ về chủ đề thiết kế website, hôm nay mình sẽ nói về một chủ để mới về Data Mining(Khai phá dữ liệu), mình cũng chỉ biết về một phần của nó thì bài chia sẻ này sẽ giúp các bạn hiểu về phần nào đó và rất mong mọi người có thể cùng chia sẻ những hiểu biết mới của bạn về lĩnh vực này nhé.
Như mọi người đã biết ngày nay với cách mạng 4.0 hướng đến phát triển trí tuệ nhân tạo (AI), vạn vật kết nối với Internet of Things(IoT), và dữ liệu lớn (Big Data). Việc nhận dạng trong trí tuệ nhân tạo được sử dụng rất phổ biến và hữu ích trong cuộc sống hiện nay như nhận dạng mặt người, nhận dạng biển số xe ... Nó rất hữu ích phải không nào, như nhận dạng mặt người giúp cho ngành công an dễ dàng tìm ra tội phạm thông qua mô tả, nhận dạng biển số xe thì giúp chúng ta không phải ghi giấy tờ biến số mà chỉ cần dùng thẻ quẹt vé xe và có phần mềm chụp ảnh lại biển số và nhận dạng.
Có rất nhiều thuật toán được hỗ trợ trong phân lớp nhận dạng như thuật toán naive bayes, kmeans… Nhưng hôm nay mình muốn giới thiệu với các bạn về thuật toán Adaboost có các đặc trưng hear-like, cascade of classifiers được áp dụng đồng thời vào bài toán nhận dạng biển số xe.
1. Tìm hiểu về khai phá dữ liệu (Data Mining)
Data Mining là quá trình khai phá, trích xuất, khai thác và sử dụng những dữ liệu có giá trị tiềm ẩn từ bên trong lượng lớn dữ liệu được lưu trữ trong các cơ sở dữ liệu (CSDL), kho dữ liệu, trung tâm dữ liệu… lớn hơn là Big Data dựa trên kĩ thuật như mạng nơ ron, lí thuyết tập thô, tập mờ, biểu diễn tri thức… Đây là một công đoạn trong hoạt động “làm sạch” dữ liệu.
Hay có thể hiểu đơn giản nó chính là một phần của quá trình trích xuất những dữ liệu có giá trị tốt, loại bỏ dữ liệu giá trị xấu trong bộn bề thông tin trên Internet và các nguồn dữ liệu đang có.
Khai phá dữ liệu là một trong các bước trong khai phá tri thức hình ảnh.
1.1 Các bước của quá trình khai phá dữ liệu
Xác định vấn đề và không gian dữ liệu để giải quyết vấn đề (Problem understanding and data understanding).
Chuẩn bị dữ liệu (Data preparation), bao gồm các quá trình làm sạch dữ liệu (data cleaning), tích hợp dữ liệu (data integration), chọn dữ liệu (data selection), biến đổi dữ liệu (data transformation).
Khai thác dữ liệu (Data mining): xác định nhiệm vụ khai thác dữ liệu và lựa chọn kỹ thuật khai thác dữ liệu. Kết quả cho ta một nguồn tri thức thô.
Đánh giá (Evaluation): dựa trên một số tiêu chí tiến hành kiểm tra và lọc nguồn tri thức thu được.
Triển khai (Deployment).
Quá trình khai thác tri thức không chỉ là một quá trình tuần tự từ bước đầu tiên đến bước cuối cùng mà là một quá trình lặp và có quay trở lại các bước đã qua.
1.2 Các phương pháp khai thác dữ liệu
Phân lớp (Classification): Là phương pháp dự báo, cho phép phân loại một đối tượng vào một hoặc một số lớp cho trước.
Hồi qui (Regression): Khám phá chức năng học tập dự đoán, sẽ ánh xạ một mục dữ liệu thành một biến dự đoán giá trị thực.
Phân nhóm (Clustering): Một nhiệm vụ mô tả phổ biến trong đó người ta tìm cách xác định một tập hợp các loại hoặc cụm hữu hạn để mô tả dữ liệu.
Tổng hợp (Summarization): Một nhiệm vụ mô tả bổ sung liên quan đến các phương pháp để tìm một mô tả nhỏ gọn cho một tập hợp (hoặc tập hợp con) dữ liệu.
Mô hình ràng buộc (Dependency modeling): Tìm mô hình cục bộ mô tả các phụ thuộc đáng kể giữa các biến hoặc giữa các giá trị của đối tượng địa lý trong tập dữ liệu hoặc trong một phần của tập dữ liệu.
Dò tìm biến đổi và độ lệch (Change and Deviation Dectection): Khám phá những thay đổi quan trọng nhất trong tập dữ liệu.
2. Thuật toán adaboost.
2.1 Đặc trưng Haar-like
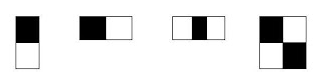
Do viola và Jones công bố, gồm 4 đặc trưng cơ bản để xác định khuôn mặt người. Mỗi đặc trưng của Haar-like là sự kết hợp của hai hay ba hình chữ nhật trắng và đen như các hình sau:
- Đặc trưng cơ bản:
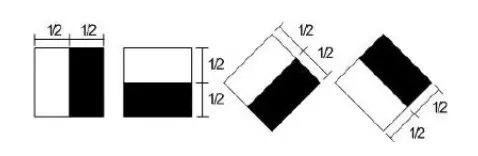
- Đặc trưng cạnh:
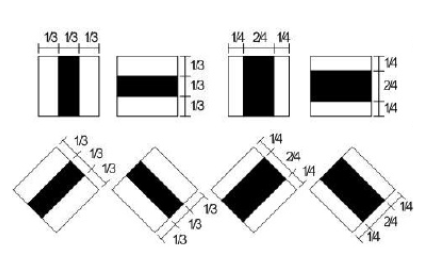
- Đặc trưng đường:
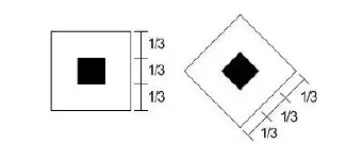
- Đặc trưng xung quanh tâm:
- Đặc trưng đường chéo:

Giá trị của đặc trưng Haar-like được xã định bởi độ chếnh lệch giữa tổng các giá trị pixel mức xám nằm trong vùng đen so với vùng trắng.
f(x) = Tổng vùng đen(các mức xám của pixel) - Tổng vùng trắng(các mức xám của pixel)
Sử dụng giá trị này, so sánh với các giá trị của các giá trị pixel thô, các đặc trưng Haar-like có thể tăng/giảm sự thay đổi in-class /out-of-class(bên trong hay bên ngoài lớp biển số xe), do đó sẽ làm cho bộ phân loại dễ hơn.
Cách dùng “ảnh chia nhỏ” (integral image) giúp tính toán nhanh chóng các đặc trưng Haar-like.
Hình chia nhỏ ở vị trí (x,y) bằng tổng các giá trị pixel phía bên trái của tọa độ (x,y) bao gồm :
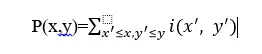
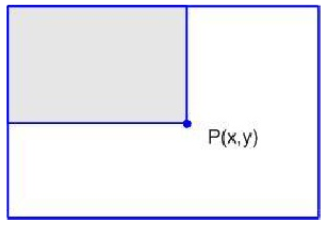
Tổng các giá trị pixel trong vùng “A”:
P1 = A1; P2 = A2; P3 = A1 + A3;
P = A + A1 + A2 + A3;
A = P + P1 - P2 - P3;
Tiếp theo để chọn các đặc trưng Haar-like dùng cho việc thiết lập ngưỡng. Viola và Jones sử dụng phương pháp máy học gọi là Adaboost. Adaboost sẽ kết hợp các bộ phân loại yếu để tạo thành các bộ phân loại mạnh. Với bộ phân loại yếu chỉ cho ra câu trả lời chính xác chỉ hơn việc đoán một cách ngẫu nhiên một chút, còn bộ phân loại mạnh có thể đưa ra câu trả lời chính xác trên 60%.
2.2 Thuật toán tăng tốc AdaBoost
Kỹ thuật Boosting: Boosting là thuật toán học quần thể bằng cách xây dựng nhiều thuật toán học cùng lúc (ví dụ như cây quyết định) và kết hợp chúng lại. Mục đích là có thể có một cụm hoặc một nhóm các weak learner sau đó kết hợp chúng lại để tạo ra một strong learner duy nhất.
AdaBoost (Adaptive Boost) là một thuật toán học mạnh, giúp đẩy nhan việc tạo ra một bộ phân loại mạnh (strong classifier) bằng cách chọn các đặc trưng tốt trong một họ các bộ phân loại yếu (weak classifer - bộ phân loại yếu) và kết hợp chúng lại tuyến tính bằng cách sử dụng các trọng số. Điều này thật sự cải thiện dần độ chính xác nhờ áp dụng hiệu quả một chuỗi các bộ phân loại yếu.
Sơ đồ cơ bản về Adaboost:
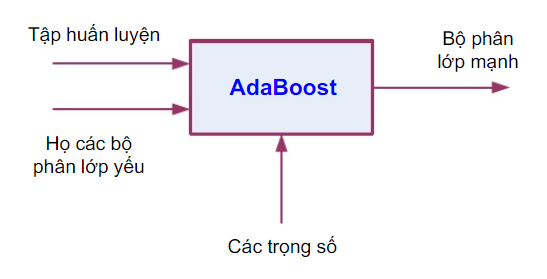
Thuật toán học này ban đầu duy trì một phân bố chuẩn (tương đồng nhau) các trọng số trên mỗi một mẫu huấn luyện. Trong bước lặp đầu tiên thuật toán huấn luyện một bộ phân loại yếu bằng cách dùng một đặc trưng Haar-like đã thực hiện tốt nhất việc phát hiện các mẫu thử huấn luyện. Trong lần lặp thứ hai, các mẫu thử dùng cho huấn luyện nhưng bị phân loại nhầm bởi bộ phân loại yếu đầu tiên được nhận trọng số cao hơn sao cho đặc trưng Haar-like được chọn lần này phải tập trung khả năng tính toán cho các mẫu thử bị phân loại nhầm này. Sự lặp lại tiếp tục thực hiện và các kết quả cuối cùng sẽ là một chuỗi cascade các kết hợp tuyến tính của các bộ phân loại yếu, tạo ra một bộ phân loại mạnh giúp được độ chính xác mong muốn. Thuật toán học AdaBoost sau 3 lần lặp được minh họa dưới đây là một ví dụ thuật toán AdaBoost sau ba lần lặp.
Thuật toán học adaboost:
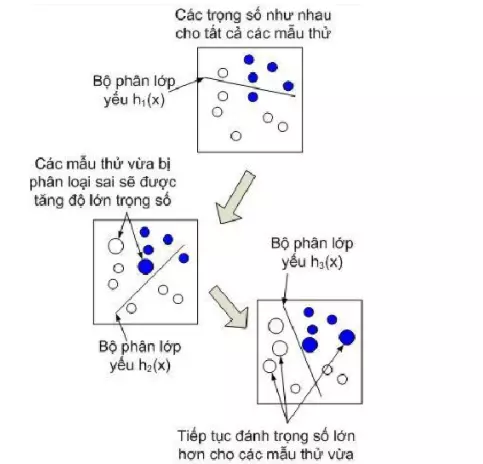
Là một cải tiến của tiếp cận Boosting, Adaboost sử dụng khái niện trọng số (weight) để đánh dấu các mẫu nhận dạng. Trong quá trình huấn luyện, cứ mỗi bộ phân loại yếu được xây dựng, thuật toán sẽ tiến hành cập nhật lại trọng số để chuẩn bị cho việc xây dựng bộ phân loại yếu kế tiếp thông qua việc tăng trọng số của các mẫu bị nhận dạng và giảm trọng số của các mẫu được nhận dạng đúng bởi bộ phân loại yếu vừa xây dựng. Bằng cách này, các bộ phân loại yếu sau có thể tấp trung vào các mẫu mà các bộ phân loại yếu trước đó làm chưa tốt. Sau cùng, các bộ phân loại yếu dẽ được kết hợp tùy theo mức độ “ tốt” của chúng để tạo dụng nên bộ phân loại mạnh.
Có thể hình dung một cách trực quan như sau : để biết một ảnh có phải là mặt người hay không, ta hỏi T người (tương đương với T bộ phân loại yếu xây dựng từ T vòng lặp của thuật toán Adaboost), đánh giá của mỗi người (tương đương với một bộ phân loại yếu) chỉ cần tốt hơn ngẫu nhiên một chút (tỉ lệ sai dưới 50%). Sau đó, ta sẽ đánh trọng số cho các đánh giá của từng người (thể hiện qua hệ số α), người nào có khả năng đánh giá tốt các mẫu khó thì mức độ quan trọng của người đó trong kết luận cuối cùng sẽ cao hơn những người chỉ đánh giá tốt các mẫu dễ. Việc cập nhật lại trọng số của các mẫu sau mỗi vòng tăng cường chính là để đánh giá độ khó của các mẫu (mẫu càng có nhiều người đánh giá sai là mẫu càng khó). Mỗi đặc trưng fi bộ phân lớp yếu xây dựng một hàm phân lớp tối ưu ngưỡng hj(x).
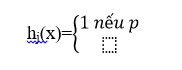
Thuật toán Adaboost:
- Cho một tập gồm n mẫu có đánh dấu (x1, y1), (x2, y2),…., (xn, yn) với xk ∈ (xk1, xk2,…, xkm) là vector đặc trưng và yk ∈ (-1,1) là nhãn của mẫu (1 ứng với object, -1 ứng với backgound).
- Khởi tạo trọng số ban đầu cho tất cả các mẫu: với m là số mẫu đúng (ứng với object và y = 1) và l là số mẫu sai (ứng với background và y = -1)
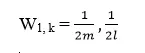
- Xây dựng T weak classifiers Lặp t=1,..., T Với mỗi đặc trưng trong vector đặc trưng, xây dựng một weak classifier hj với ngưỡng θj và lỗi εj:
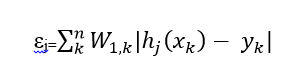
- Chọn ra hj với εj nhỏ nhất, ta được ht: ht: X→{1, -1} Cập nhật lại trọng số:
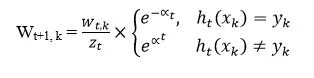
- Trong đó:
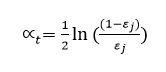
- Zt: Hệ số dùng để đưa Wt+1 về đoạn [0, 1]
- Strong classifier được xây dựng:
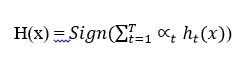
Giải thích:
Quá trình huấn luyện bộ phân loại được thực hiện bằng một vòng lặp mà ở mỗi bước lặp, thuật toán sẽ được chọn ra bộ phân loại yếu ht thực hiện việc phân loại với mỗi εt nhỏ nhất (do đó sẽ là bộ phân loại tốt nhất) để bổ sung vào bọ phân loại mạnh. Mỗi khi chọn được 1 bộ phân loại ht, Adaboost sẽ tính được giá trị ∝t theo công thức ở trên, ∝t cũng được chọn trên nguyên tắc giảm giá trị lỗi εt. Hệ số ∝t nói lên mức độ quan trọng của Ht.
- Trong công thức phân loại H(x):
ta thấy tất cả các bộ phân loại ht đều có đóng góp vào kết quả phân loại của H(x), và mức độ đóng góp của chúng phụ thuộc vào giá trị ∝t tương ứng: ht với ∝t càng lớn thì nó càng có vai trò quan trọng H(x).
Trong công thức tính ∝t:
Ta thấy giá trị ∝t tỉ lệ nghịch với εj bởi ht được chọn với tiêu chí εj là nhỏ nhất do đó nó sẽ đảm bảo giá trị ∝t lớn nhất.
Sau khi tính được giá trị ∝t, Adaboost tiến hành cập nhật lại trọng số của các mẫu thông qua việc tăng trọng số của các mẫu mà ht phân loại sai, giảm trọng số mà các ht phân loại đúng. Bằng cách này, trọng số của mẫu phản ánh được mức độ khó nhận dạng của mẫu đó và H(t+1) sẽ được ưu tiên học cách phân loại những mẫu này.
Vòng lặp xây dựng bộ phân loại mạnh (strong classifer) sẽ dừng lại sau T lần lặp. Trong thực tế, người ta ít sử dụng giá trị T vì không có công thực nào đảm bảo tính được giá trị T tối ưu cho quá trình huấn luyện . Thay vào đó, người ta sử dụng giá trị max False Positive (tỉ lệ nhận dạng sai tốt đa các mẫu positive) hay max False Alarm (tỉ lệ nhận dạng sai tốt đa các mẫu negative). Tỉ lệ này của các bộ phân loại cần xây dựng không được phép vượt qua giá trị này. Khi đó, qua các lần lặp, tỉ lệ nhận dạng sai các mẫu âm tính (false alarm) của bộ phân loại mạnh Ht(x) xây dựng được (tại lần lặp thứ t) sẽ giảm dần, và vòng lặp kết thúc khi tỉ lệ này thấp hơn tỉ lệ nhận dạng sai tốt đa các mẫu âm tính.
Kết luận
Trên đây là những gì mình tìm hiểu được về khai phá dữ liệu - giải thuật Adaboost mình muốn chia sẻ đến các bạn. Cám ơn các bạn đã theo dõi bài viết !!!
Tham khảo :
All rights reserved
