
Giải thích cách thức mô hình hoạt động với Layer-Wise Relevance Propagation
Bài đăng này đã không được cập nhật trong 4 năm
Để một mô hình học máy có thể khái quát hóa tốt, người ta cần đảm bảo rằng các quyết định của nó được hỗ trợ bởi các mẫu có ý nghĩa trong dữ liệu đầu vào. Tuy nhiên, điều kiện tiên quyết là để mô hình có thể tự giải thích, ví dụ: bằng cách làm nổi bật các đặc trưng đầu vào mà nó sử dụng để hỗ trợ dự đoán của nó. Layer-Wise Relevance Propagation hay LRP là một kỹ thuật mang lại khả năng giải thích cho các Deep Neural Network có độ phức tạp cao. Bài viết này trình các khái niệm cơ bản về kĩ thuật trên cũng như cung cấp một ví dụ nhỏ về việc áp dụng phương pháp này nhằm giải thích cách thức hoạt động của một mô hình phân loại ảnh
Explainable AI và Explainable machine learning
Trong khi trí tuệ nhân tạo (AI) thâm nhập ngày càng sâu rộng vào mọi lĩnh vực của đời sống thì việc xây dựng và củng cố niềm tin ở AI càng trở nên quan trọng. Tuy nhiên, hầu hết người dùng đều không thể quan sát trực quan hay nhận biết cách thức AI đưa ra quyết định. Phần lớn các thuật toán đang được sử dụng cho học máy cũng gặp hạn chế trong việc thiết lập các lý giải cụ thể, làm ảnh hưởng tiêu cực đến sự tin tưởng của con người đối với các hệ thống trí tuệ nhân tạo. Nhu cầu hiện nay là AI phải vừa có khả năng hoạt động hiệu quả, vừa có thể đưa ra các giải thích minh bạch cho các quyết định của mình. Đây được gọi là Explainable AI (XAI).
Có thể nói rằng, các kỹ thuật học máy như mạng Deep Neural Network đã đạt được nhiều thành công trong các ứng dụng khoa học và công nghiệp. Động lực chính cho việc áp dụng các kỹ thuật này là sự gia tăng của các bộ dữ liệu lớn, cho phép trích xuất các mối tương quan và phi tuyến tính phức tạp trong thế giới thực.
Tuy nhiên, bên cạnh việc khó thiết lập các lý giải cụ thể, làm ảnh hưởng tiêu cực đến sự tin tưởng củangười dùng, việc phát triển các mô hình với các bộ dữ liệu lớn thường bị cản trở bởi sự hiện diện của các tương quan giả giữa các biến khác nhau. Tương quan giả khiến máy học gặp khó khăn khi phải quyết định nên sử dụng biến đầu vào tương quan nào trong số ít biến đầu vào tương quan để hỗ trợ dự đoán. Việc không tìm hiểu các đặc trưng đầu vào chính xác có thể dẫn đến các công cụ dự đoán kiểu ‘Clever Hans’.
Một số phương pháp như lựa chọn đặc trưng cung cấp một giải pháp tiềm năng bằng cách chỉ trình bày cho máy học một số lượng hạn chế các đặc trưng đầu vào ‘tốt’. Tuy nhiên, cách tiếp cận này khó áp dụng, ví dụ như trong nhận dạng hình ảnh, nơi mà vai trò của các pixel riêng lẻ không cố định.
Bên cạnh phương trên, học máy có thể giải thích được nhìn vấn đề theo hướng khác: Thứ nhất, một mô hình được đào tạo mà không quan tâm quá nhiều đến việc lựa chọn đặc trưng. Chỉ sau khi đào tạo, ta mới xem xét các đặc trưng đầu vào nào mà mạng nơ-ron đã học được. Dựa trên kết quả của quá trình giải thích này, các đặc trưng ‘xấu’ có thể bị loại bỏ và mô hình có thể được đào tạo lại trên dữ liệu đã được làm sạch. Với ý niệm chung như vậy, một số các phương pháp đã được phát triển mà đơn giản có thể kể đến Phân tích Taylor.
Một số phương pháp áp dụng cho Explainable machine learning
Kĩ thuật Phân tích Taylor (Taylor Decomposition), tạo ra các giải thích bằng cách thực hiện khai triển Taylor của dự đoán tại một số điểm tham chiếu :
Trong đó, các thành phần bậc nhất (các phần tử của tổng) định lượng mức độ liên quan của từng đặc điểm đầu vào với dự đoán và hình thành lời giải thích. Mặc dù đơn giản và dễ hiểu, phương pháp này không ổn định khi áp dụng cho các deep neural networks. Sự không ổn định có thể bắt nguồn từ các thiếu sót khác nhau đã biết của các chức năng mạng nơron sâu:
-
Shattered gradients: Trong khi giá trị hàm nói chung là chính xác, thì gradient của hàm lại bị nhiễu.
-
Adversarial examples: Một số nhiễu loạn nhỏ của đầu vào có thể khiến giá trị hàm thay đổi đáng kể.
Những thiếu sót này gây khó khăn cho việc chọn điểm tham chiếu có ý nghĩa với gradient có ý nghĩa và điều này đã ngăn cản việc xây dựng một lời giải thích đáng tin cậy. Vậy nên một số các kỹ thuật giải thích khác đã được đề xuất để giải quyết tốt hơn sự phức tạp của mạng nơ-ron sâu có thể kể đến là tích hợp một số lượng lớn các ước tính đạo hàm theo hướng cục bộ hay thay thế gradient bằng một ước tính thô hơn về hiệu ứng, ví dụ: phản ứng của mô hình đối với những xáo trộn giống như bản vá lỗi. Nhìn chung, tất cả các kỹ thuật này liên quan đến nhiều đánh giá mạng nơ-ron, có thể tốn kém về mặt tính toán.
Trong phần tiếp theo, ta sẽ tập trung vào Layer-wise Relevance Propagation, một kỹ thuật tận dụng cấu trúc đồ thị của mạng nơ-ron sâu để tính toán các giải thích một cách nhanh chóng và đáng tin cậy.
Layer-Wise Relevance Propagation
Layer-Wise Relevance Propagation (LRP) là một kỹ thuật giải thích áp dụng cho các mô hình có cấu trúc như mạng nơ-ron, trong đó đầu vào có thể là ví dụ: hình ảnh, video hoặc văn bản. LRP hoạt động bằng cách truyền ngược dự đoán trong mạng nơron, bằng các quy tắc lan truyền cục bộ được thiết kế có chủ đích.
Thủ tục lan truyền được thực hiện bởi LRP phải tuân theo thuộc tính bảo toàn, trong đó những gì đã được nhận bởi một tế bào thần kinh phải được phân phối lại cho lớp dưới với số lượng bằng nhau. Hành vi này tương tự như các định luật bảo toàn của Kirchoff trong các mạch điện và được chia sẻ bởi các công trình giải thích khác như Interpreting Individual Classifications of Hierarchical Networks. Gọi và là các nơron ở hai lớp liên tiếp của mạng nơ-ron. Việc truyền điểm liên quan tại một lớp nhất định lên các nơ-ron của lớp dưới đạt được bằng cách áp dụng quy tắc:
Trong đó, mô hình hóa mức độ mà nơron đã đóng góp để làm cho nơron có liên quan trong khi việc sử dụng mẫu số là tổng với mọi được thực hiện nhằm đảm bảo việc bảo toàn thông tin. Quá trình truyền kết thúc khi đã truyền đến các đặc trưng đầu vào. Nếu sử dụng quy tắc trên cho tất cả các nơron trong mạng, ta có thể dễ dàng xác minh thuộc tính bảo toàn theo lớp và bằng cách mở rộng thuộc tính bảo toàn toàn cục . Quy trình LRP tổng thể được minh họa trong hình dưới đây:
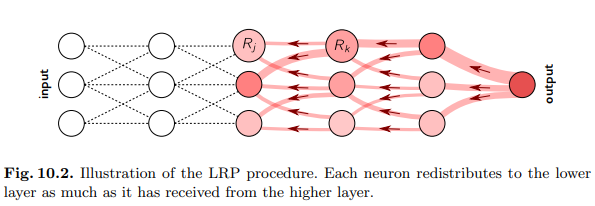
Mặc dù LRP rõ ràng khác với cách tiếp cận phân rã Taylor đơn giản được đề cập trong phần giới thiệu, chúng ta sẽ thấy trong phần tiếp theo rằng mỗi bước của quy trình lan truyền có thể được mô hình hóa như một phép phân rã Taylor riêng được thực hiện trên các đại lượng cục bộ trong đồ thị .
LRP đã được áp dụng để phát hiện ra các sai lệch trong các mô hình ML và bộ dữ liệu thường được sử dụng. Nó cũng được áp dụng để trích xuất thông tin chi tiết mới từ các mô hình ML hoạt động tốt, ví dụ: trong nhận dạng nét mặt. Phần tiếp theo trong bài viết này trình bày cách thức triển khai đối với các mô hình thị giác máy cũng như một số biến thể của LRP hay được sử dụng.
Áp dụng LRP với mạch chỉnh lưu sâu
Việc áp dụng LRP cho các mạng nơ-ron sâu có bộ chỉnh lưu (ReLU), được cho là lựa chọn phổ biến nhất trong các ứng dụng ngày nay. Nó bao gồm các kiến trúc nổi tiếng để nhận dạng hình ảnh như VGG-16 và Inception v3, hoặc mạng nơ-ron được sử dụng trong học tăng cường. Mạng chỉnh lưu sâu bao gồm các nơron thuộc loại:
Tổng chạy trên tất cả các kích hoạt lớp dưới , cộng với một nơ-ron phụ đại diện cho độ lệch. Chính xác hơn, chúng ta đặt và định nghĩa là độ lệch nơron.
Các quy tắc lan truyền
Quy tắc cơ bản
Quy tắc này phân phối lại tương ứng với sự đóng góp của mỗi đầu vào cho việc kích hoạt nơ-ron khi chúng xảy ra được thể hiện qua công thức sau:
Quy tắc này thỏa mãn các thuộc tính cơ bản, chẳng hạn như , làm cho các khái niệm trùng khớp như trọng số không, vô hiệu hóa và không có kết nối. Mặc dù quy tắc này trông có vẻ trực quan, nhưng có thể chỉ ra rằng việc áp dụng thống nhất quy tắc này cho toàn bộ mạng nơ-ron sẽ tạo ra lời giải thích tương đương với Gradient × Input. Như đã đề cập trong phần giới thiệu, gradient của mạng nơron sâu thường nhiễu, do đó người ta cần thiết kế các quy tắc lan truyền mạnh mẽ hơn.
Quy tắc Epsilon
Cải tiến đầu tiên của quy tắc LRP-0 cơ bản bao gồm thêm một số hạng dương nhỏ trong mẫu số:
Vai trò là nhằm giải quyết một số trường hợp khi những đóng góp vào việc kích hoạt nơron k là yếu (mẫu số bằng 0.
Quy tắc Gamma
Một cải tiến khác có thể kể đến là việc ưu tiên ảnh hưởng của những đóng góp tích cực hơn những đóng góp tiêu cực:
Tham số kiểm soát mức độ ủng hộ các đóng góp tích cực. Khi tăng, các đóng góp tiêu cực bắt đầu biến mất. Mức độ phổ biến của các đóng góp tích cực có ảnh hưởng hạn chế đến mức độ liên quan tích cực và tiêu cực lớn có thể phát triển trong giai đoạn lan truyền và điều này sẽ giúp đưa ra những lời giải thích ổn định hơn.
Cài đặt LRP
Với các quy tắc được trình bày ở phần trên, việc cài đặt có thể được thực hiện dễ dàng và hiệu quả. Xem xét quy tắc tổng quát sau:
trong đó là trường hợp đặc biệt. Việc tính toán quy tắc lan truyền này có thể được phân tích theo bốn bước như thế hiện trong hình dưới đây:

Bước đầu tiên là forward bản sao của lớp nơi các trọng số và bias đã được áp dụng cho ánh xạ , mà chúng tôi thêm vào đó các gia số nhỏ . Bước thứ hai và thứ tư là các thao tác đơn giản về phần tử. Đối với bước thứ ba, một lưu ý rằng cũng có thể được biểu thị dưới dạng tính toán gradient:
trong đó là vectơ của các kích hoạt lớp thấp hơn, trong đó là một hàm của nó và thay vào đó được coi là hằng số. Gradient này có thể được tính toán thông qua đạo hàm tự động, có sẵn trong hầu hết các thư viện mạng nơ-ron. Trong PyTorch, quy tắc lan truyền này có thể được thực hiện bằng đoạn mã sau:
def relprop(a,layer,R):
z = epsilon + rho(layer).forward(a)
s = R/(z+1e-9)
(z*s.data).sum().backward()
c = a.grad
R = a*c
return R
Mã có thể áp dụng cho cả lớp convolution và lớp dense với kích hoạt ReLU. Hàm “rho” trả về một bản sao của lớp, trong đó trọng số và bias đã được áp dụng cho ánh xạ . Giá trị trong bộ phận chỉ đơn giản là thực thi hành vi . Trong khi đó, cách truy cập.data cho phép biến s trở nên không đổi để gradient không được truyền qua nó. Hàm back gọi cơ chế đạo hàm tự động và lưu trữ gradient kết quả trong a.
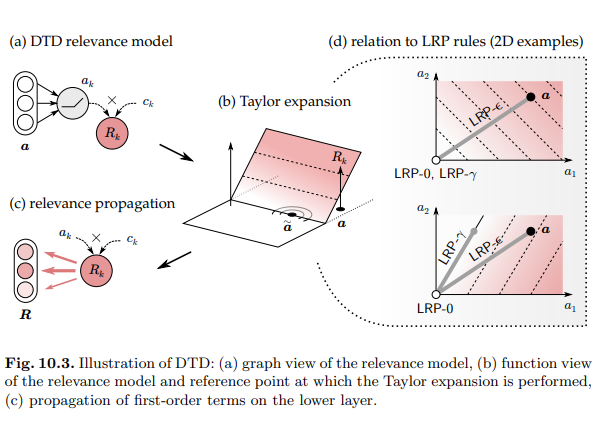
LRP như Deep Taylor Decomposition
Bên cạnh việc tính toán như trrn, có thể được giải thích với Deep Taylor Decomposition. DTD xem LRP như một chuỗi mở rộng Taylor được thực hiện cục bộ tại mỗi nơ-ron. Cụ thể hơn, điểm phù hợp được biểu thị dưới dạng hàm của các kích hoạt cấp thấp hơn được biểu thị bằng vectơ , và sau đó chúng tôi thực hiện khai triển Taylor bậc nhất của Rk (a) tại một số điểm tham chiếu trong không gian của các kích hoạt:
Các số hạng bậc nhất (các phần tử tổng hợp) xác định có bao nhiêu nên được phân phối lại trên các nơron của lớp dưới. Do mối quan hệ phức tạp tiềm ẩn giữa và , việc tìm điểm tham chiếu thích hợp và tính toán cục bộ gradient là rất khó.
Vậy nên, để có được một biểu thức dạng đóng cho các số hạng của phương trình trên, người ta cần thay thế hàm liên quan thực sự bằng một mô hình phù hợp dễ phân tích hơn. Một trong những mô hình như vậy là modulated ReLU activation:
Trong đó được đặt không đổi và theo cách tại điểm dữ liệu hiện tại. Việc coi là hằng số có thể hợp lý khi là kết quả của việc áp dụng ở các lớp cao hơn. Sự mở rộng Taylor của mô hình liên quan trên miền kích hoạt cho:
Các số hạng bậc hai và bậc cao hơn bằng 0 do tính tuyến tính của hàm ReLU trên miền được kích hoạt của nó. Các số hạng bậc 0 cũng có thể được làm nhỏ tùy ý bằng cách chọn điểm tham chiếu gần bản lề ReLU. Khi một điểm tham chiếu được chọn, các thuật ngữ bậc nhất có thể dễ dàng được tính toán và phân phối lại cho các nơ-ron ở lớp dưới. Hình sau sẽ minh họa một cách hình dung hơn cách phân rã Taylor sâu được áp dụng tại một nơron nhất định:
Giải thích cách thức hoạt động của VGG16 với iNNvestigate
Với 1 tỷ thứ lý thuyết được trình bày ở trên, có vẻ mọi người cũng muốn chuyển sang thứ gì đó thực tiễn một chút, bởi vậy phần này trình bày một ví dụ nhỏ được thực hiện với thư viện iNNvestigate nhằm giải thích cách thức mô hình VGG16 trích xuất thông tin và phân loại ảnh đầu vào. Để thực hiện điều đó, ta cần cài đặt thư viện iNNvestigate qua câu lệnh sau (lưu ý rằng thư viện này hoạt động dựa trên TensorFlow):
pip install innvestigate
Tiếp theo, với việc sử dụng thư viện trên với một hình ảnh bất kì trên Internet như trong notebook này ta thu được hình ảnh giải thích một cách tường minh hơn cách thức các mô hình sử dụng các đặc trưng từ ảnh đầu vào để đưa ra kết quả đoán nhận. Chi tiết hơn, ta có thể thấy rằng, trong hình bên phải, các pixel có độ đậm càng lớn thì càng đóng góp nhiều vào kết quả đoán nhận.
 Ví dụ trên chỉ là một ví dụ nhỏ nhằm minh họa quá trình thực hiện của việc sử dụng một thư viện khá phổ biến nhằm giải thích cách thức mô hình hoạt động cũng như kết quả thu được. Với các mô hình phức tạp hơn, ta cần có các công thức tính toán phù hợp cho quá trình lan truyền của LRP do mỗi loại lớp lại có các đặc điểm chung khác nhau.
Ví dụ trên chỉ là một ví dụ nhỏ nhằm minh họa quá trình thực hiện của việc sử dụng một thư viện khá phổ biến nhằm giải thích cách thức mô hình hoạt động cũng như kết quả thu được. Với các mô hình phức tạp hơn, ta cần có các công thức tính toán phù hợp cho quá trình lan truyền của LRP do mỗi loại lớp lại có các đặc điểm chung khác nhau.
Tổng kết
Bài viết này trình các khái niệm cơ bản về LRP hay Layer-Wise Relevance Propagation, kĩ thuật thường được sử dụng nhằm giải thích cách thức hoạt động của các mô hình học máy cũng như cung cấp một ví dụ nhỏ về việc áp dụng phương pháp này nhằm giải thích cách thức hoạt động của một mô hình phân loại ảnh. Bên cạnh việc có hiệu năng cũng như độ chính xác tốt, các mô hình AI hiện nay nên có thể đưa ra các giải thích minh bạch cho các quyết định của mình, nhất là khi chúng càng ngày càng được sử dụng nhiều trong hầu hết các lĩnh vực của đời sống. Bài viết của mình đến đây là hết, cảm ơn mọi người đã giành thời gian đọc.
Tài liệu tham khảo
All rights reserved
