Functional Programming in JavaScript - Function Composition
Bài đăng này đã không được cập nhật trong 4 năm

Introduction
Trong Functional Programming, một hàm sẽ đảm nhận một công việc nhất định. Tuy nhiên nếu chúng ta kết hợp các hàm lại với nhau một cách đúng đắn thì có thể thực hiện được rất nhiều thứ hay ho. Trong bài viết này chúng ta sẽ cùng tìm hiểu về function composition trong FP nói chung và ngôn ngữ JavaScript nói riêng. Tuy nhiên, trước khi trở thành một composer, một phần khá quan trọng cần được đề cập đến đó là các cách để quản lý tham số trong FP. Đây là một yêu cầu căn bản trước khi chúng ta có thể kết hợp các hàm lại với nhau. Function composition có thể coi là một yếu tố nền tảng trong FP, và việc nắm chắc các lý thuyết cơ bản sẽ là cần thiết trước khi tìm hiểu sâu hơn về FP.
Let's start! 

Function Parameters
Khi xây dựng các ứng dụng sử dụng FP, chúng ta thường phải kết hợp các hàm lại với nhau. Tuy nhiên, một vấn đề thường gặp đó là tính không thống nhất giữa các tham số của các hàm về cả số lượng, thứ tự và kiểu dữ liệu. Một trong những cách để giải quyết vấn đề trên là việc định nghĩa tham số cho các hàm một cách hợp lý. Trong phần này chúng ta sẽ cùng tìm hiểu một số phương pháp để thực hiện việc đó.
Unary
Giả sử chúng ta có một mảng các số tự nhiên ở dạng text như sau:
var numbers = ["4", "5", "6"];
Công việc của chúng ta là chuyển mảng trên thành mảng các số tự nhiên ở dạng số thông thường. Việc này khá đơn giản và chúng ta có thể sử dụng hàm parseInt của JavaScript.
Hàm map() sẽ nhận tham số đầu vào là một callback function thường được gọi là mapper function hay transformer function. Ở đây callback function sẽ nhận vào giá trị của element hiện tại đang được xử lý và trả về một giá trị mới sẽ được thay thế cho giá trị gốc.
Ngoài giá trị của element hiện tại có hai đối số mà callback function trên có thể nhận vào đó là index của element và array gốc.
var upper = function(val, idx, arr) {
console.log(val, idx, arr);
return val.toUpperCase();
};
var characters = ["a", "b", "c"];
var upperCharacters = characters.map(upper);
// "a" 0 ["a", "b", "c"]
// "b" 1 ["a", "b", "c"]
// "c" 2 ["a", "b", "c"]
// ["A", "B", "C"]
Quay trở lại với ví dụ ban đầu, chúng ta có thể thực hiện việc chuyển đổi như sau:
var actualNumbers = numbers.map(function(number) {
return parseInt(number);
});
console.log(actualNumbers); // 4 5 6
Boom! We've done!
Câu hỏi đặt ra là chúng ta có thể sử dụng hàm parseInt trực tiếp thay cho callback function hay không?.
Let's try that!
numbers.map(parseInt) // 4 NaN NaN
Kết quả trả về là sai, tuy nhiên lý do ở đây là gì?
Chú ý function signature của hàm parseInt là parseInt(string, radix). Nếu ta sử dụng parseInt như trong ví dụ trên, index của element hiện tại sẽ được hiểu là giá trị của tham số radix. Chúng ta có thể kiểm tra như sau:
Nếu radix là 0 thì JavaScript engine sẽ tự động tìm giá trị của radix dựa trên định dạng của số đầu vào. Ở đây "4" là một số tự nhiên thông thường nên radix sẽ là 10:
parseInt("4", 0) // 4
Giá trị của radix phải nằm giữa 2 và 36 và không có hệ số 5:
parseInt("5", 1) // NaN
Sai định dạng cho binary number:
parseInt("6", 2) // NaN
Để sử dụng hàm parseInt như trong ví dụ trên chúng ta cần thêm một bước nhỏ nữa. Chúng ta sẽ sử dụng hàm tiện ích sau đây:
// ES5
function unary(arg) {
return function (arg) {
func(arg);
};
}
// ES6
var unary = func => arg => func(arg); // Cool!?
Mục đích của hàm unary là wrap lời gọi hàm của chúng ta sao cho chỉ có một argument duy nhất được truyền cho hàm. Chúng ta sẽ sử dụng hàm unary như sau:
numbers.map(unary(parseInt)) // 4 5 6
Job done!
Identity
Giả sử chúng ta có mảng sau:
var mix = [1, True, False, NaN, null, "", "a", "0", "1"];
Nhiệm vụ của chúng ta là loại bỏ các giá trị falsy/empty. Chắc hẳn hàm filter sẽ là lựa chọn đầu tiên trong danh sách.
Cách đơn giản nhất là sử dụng Boolean object (một wrapper cho cách giá trị boolean). Giá trị truyền vào sẽ được ép kiểu - coercion về boolean. Ở đây chúng ta có thể hiểu Boolean có chức năng giống như hàm unary đã đề cập ở phần trước.
mix.filter(Boolean) // [1, true, "a", "0", "1"]
Một cách khác được sử dụng khá nhiều trong FP đó là idenity function. Hàm đồng nhất này nhận vào một giá trị và trả về chính giá trị đó (không có bất cứ một sự thay đổi nào).
// ES5
function identity(val) {
return val;
}
// ES6
var identity = val => val;
Chúng ta có thể sử dụng hàm identity trên như sau:
mix.filter(identity) // [1, true, "a", "0", "1"]
Kết quả trả về cho hai cách làm là như nhau.
Constant
Khi sử dụng phương thức then trong Promise của JavaScript, chúng ta thường phải truyền một callback function thay vì giá trị trực tiếp ngay cả khi callback function đó chỉ có nhiệm vụ duy nhất là trả về giá trị mà đối tượng promise đã resolved hay một giá trị nào đó khác. Trong ví dụ bên dưới val là một giá trị có sẵn nào đó.
// ES5
p.then(function () {
return val;
});
// ES6
p.then(() => val);
Việc sử dụng callback function cho phương thức then như trong ví dụ trên là hoàn toàn hợp lý đặc biệt khi sử dụng arrow function thì cấu trúc sẽ đơn giản hơn rất nhiều. Tuy nhiên trong FP, chúng ta có một khái niệm khá cơ bản là pure function (hàm chỉ hoạt động dựa trên các tham số của chính nó mà thôi). Dễ thấy () => val không phải là một pure function. Do đó trong FP, cách làm trên là không được khuyến khích.
Thay vào đó, chúng ta sẽ sử dụng hàm tiện ích sau đây:
// ES5
function constant(val) {
return function (val) {
return val;
};
}
// ES6
var constant = val => () => val;
Và chúng ta có thể sử dụng hàm constant với Promise như sau:
p.then(constant(val))
constant sẽ giúp đơn giản hóa callback bên trong hàm then trong trường hợp chúng ta muốn trả về một giá trị nào đó trực tiếp. Tuy nhiên trong trường hợp này hàm constant không giúp ta loại bỏ các side effects.
Arguments and Parameters
Đôi khi sự không thống nhất giữa khai báo hàm và lời gọi hàm sẽ làm cho việc sử dụng các hàm cùng nhau trở nên khó khăn hơn.

Trong bài viết lần trước chúng ta đã từng đề cập đến việc sử dụng destructuring trong JavaScript cho các khai báo hàm. Mục đích là chúng ta sẽ chỉ cần truyền vào một argument duy nhất khi thực hiện lời gọi hàm. Tuy nhiên trên thực tế không phải lúc nào chúng ta cũng sẽ gộp các đối số thành một mảng và truyền cho hàm của chúng ta, đôi khi chúng ta cần tách các giá trị đó riêng biệt và truyền cho hàm.
function foo([x, y, ...args] = []) {
//
}
Xét ví dụ đơn giản sau:
function sum(x, y) {
return x + y;
}
function foo(func) {
return func([5, 6]);
}
foo(sum) // Failed!!!
Ở đây tham số func của hàm foo là một hàm nhận vào một giá trị duy nhất là mảng [5, 6]. Tuy nhiên hàm sum yêu cầu hai đối số phải được truyền vào khi thực hiện lời gọi hàm. Có hai cách để việc sử dụng foo(sum) được chính xác:
Thay đổi khai báo của hàm sum:
function sum([x, y] = []) {
return x + y;
}
Thay đổi lời gọi hàm trong hàm foo:
function foo(func) {
return func(...[5, 6]);
}
Nếu bạn sử dụng thư viện FP cho JavaScript như: Ramda chẳng hạn. Các vấn đề trên có thể được giải quyết bằng cách sử dụng các hàm apply và unapply. Tuy nhiên chúng ta sẽ cùng tự xây dựng hai hàm đó trong phần này. Ý tưởng chung là chúng ta sẽ sử dụng spread operator cho hàm apply và rest operator cho hàm unapply. Cụ thể như sau:
Hàm apply:
// ES5
function apply(func) {
return function (args) {
return func(...args);
};
}
// ES6
var apply = func => args => func(...args);
Hàm unapply:
// ES5
function unapply(func) {
return function(...args) {
return func(args);
};
}
// ES6
var unapply = func => (...args) => func(args);
Chúng ta sẽ sử dụng các hàm tiện ích trên như sau:
foo(apply(sum)); // 11
var nums = [1, 42, 6, 7];
var max = apply(Math.max)(nums); // 42
function multiply([x, y] = []) {
return x * y;
}
var product = unapply(multiply)(4, 5); // 20
Feeling Incomplete
Nếu bạn đã từng lập trình sử dụng ngôn ngữ Python, chắc hẳn bạn cũng đã quen với hàm partial trong functools module. Hàm này cho phép chúng ta khởi tạo trước một số tham số của hàm và trả về cho chúng ta một đối tượng mới có thể được sử dụng như một hàm bình thường.
Chúng ta hoàn toàn có thể thực hiện việc trên trong JavaScript bằng cách nhóm một hàm bên trong một hàm khác - wrapper function với một số tham số được khởi tạo sẵn (đây là cách đơn giản và thường được sử dụng).
Xét ví dụ đơn giản sau liên quan đến việc thực hiện AJAX request.
Giả sử chúng ta có một hàm tổng quát để thực hiện việc gửi request như sau:
function ajax(url, data, callback) {
//
}
Ở đây chúng ta hoàn toàn có thể sử dụng hàm trên lặp lại nhiều lần. Tuy nhiên, tưởng tượng rằng trong logic của chúng ta có tới 10 lần cần gửi request lên để lấy về danh sách các bài post chẳng hạn. Thay vì lặp lại việc truyền URL của API cho hàm ajax, chúng ta hoàn toàn có thể tạo một wrapper function như sau:
function getPosts(data, callback) {
ajax('https://viblo.asia/api/posts', data, callback);
}
Khi sử dụng hàm getPosts chúng ta sẽ không cần ghi nhớ URL của API nữa - một cải thiện nhỏ nhưng cũng khá tốt.
Tuy nhiên trên thực tế hàm của chúng ta có thể thay đổi rất nhiều về cấu trúc. Thay vì định nghĩa wrapper function một cách thủ công, chúng ta nên tìm quy tắc chung hay pattern này và xây dựng một hàm tiện ích tổng quát dựa trên pattern đó. Việc này không chỉ đúng trong FP mà còn trong lập trình nói chung.
Vậy pattern trong trường hợp này của chúng ta là gì?
Mục đích là làm giảm số lượng tham số cần khởi tạo so với hàm gốc. Do đó có thể hiểu pattern của chúng ta là làm giảm số arity của hàm (mình đã đề cập đến arity trong bài viết trước).
Chúng ta có thể định nghĩa hàm partial như sau (tất nhiên nếu dùng Ramda thì hàm này cũng đã được cung cấp sẵn):
// ES5
function partial(func, ...initialArgs) {
return function(...subsequentArgs) {
return func(...initialArgs, ...subsequentArgs);
}
}
// ES6
var partial = (func, ...initialArgs)
=> (...subsequentArgs)
=> func(...initialArgs, ...subsequentArgs);
Một lần nữa chúng ta lại tận dụng spread/rest operator. Tham số đầu tiên của hàm partial - func là hàm mà chúng ta cần khởi tạo trước một hoặc nhiều tham số. initialArgs sẽ là danh sách các đối số tương ứng với các tham số cần khởi tạo trước. Ở đây chúng ta sẽ sử dụng rest operator để thu thập các đối số đó thành một mảng duy nhất. Tương tự subsequentArgs sẽ là các đối số truyền vào khi chúng ta thực hiện lời gọi hàm trên partial function. Cuối cùng spread operator sẽ được sử dụng và các đối số truyền vào sẽ là tổng hợp của initialArgs và subsequentArgs. Việc inner function của hàm partial có thể ghi nhớ initialArgs và func là do chúng ta đang sử dụng closure ở đây.
Hãy cùng xét một ví dụ đơn giản sử dụng hàm partial trên của chúng ta:
var double = partial(Math.imul, 2);
double(2) // 4
double(10) // 20
Và với hàm ajax của chúng ta:
var getPosts = partial(ajax, 'https://viblo.asia/api/posts');
Chúng ta có thể sử dụng hàm
bind()trong JavaScript để thực hiện việc chỉ địnhthiscontext và khởi tạo cho một số tham số. Tuy nhiên khi sử dụng FPpartialsẽ vẫn là lựa chọn tốt hơn.
Để ý rằng trong việc sử dụng hàm partial với hàm ajax ở trên, các đối số truyền vào sẽ phụ thuộc vào vị trí của tham số trong hàm ajax. Giả sử chúng ta muốn khởi tạo tham số callback trước tiên và hai tham số url và data sẽ được chỉ định sau đó.
Chúng ta sẽ thực hiện việc đó như thế nào?
Một cách khá đơn giản là chúng ta sẽ đảo ngược thứ tự của các tham số trong hàm gốc sử dụng hàm tiện ích sau đây:
// ES5
function reverseArgs(func) {
return function(...args) {
return func(...args.reverse());
};
}
// ES6
var reverseArgs = func => (...args) => func(..args.reverse());
Xét ví dụ sau đây:
var squared = partial(reverseArgs(Math.pow), 2);
squared(4) // 16
squared(5) // 25
Đối với hàm ajax chúng ta có thể làm như sau:
var partialAjax = reverseArgs(
partial(reverseArgs(ajax), function(obj) {
//
})
);
partialAjax('https://viblo.asia/api/tags', {})
Để ý rằng reverseArgs được gọi 2 lần nhằm đảm bảo thứ tự của các tham số sau khi đã thực hiện việc khởi tạo một phần được chính xác. Chúng ta có thể tóm gọn quá trình này trong một hàm tiện ích khác đơn giản hơn partialRight (theo tên đặt trong thư viện Ramda):
function partialRight(func, ...initialArgs) {
return reverseArgs(
partial(reverseArgs(func), ...initialArgs.reverse())
);
}
Đơn giản hơn chúng ta chỉ cần đổi vị trí của initialArgs và subsequentArgs trong hàm partial ở phía trên:
function partialRight(func, ...initialArgs) {
return function(...subsequentArgs) {
return func(...subsequentArgs, ...initialArgs);
};
}
Ở đây hàm
partialRightchỉ đảm bảo các giá trị khởi tạo sẽ xuất hiện ở cuối cùng (rightmost, last) khi truyền cho hàm gốc chứ không đảm bảo vị trí chính xác của các đối số đó.
function bar(x, y, ...args) {
console.log(x, y, args);
}
var partialBar = partialRight(bar, "last-argument")
partialBar(1) // 1 "last-argument"
partialBar(1, 2) // 1 2 ["last-argument"]
Currying
Currying có ý tưởng tương tự với hàm partial mà chúng ta đã bàn luận ở trên khi nó cho phép chúng ta khởi tạo giá trị cho các tham số của hàm gốc. Tuy nhiên điểm khác biệt là các tham số sẽ được khởi tạo tách biệt nhau theo thứ tự từng tham số một.
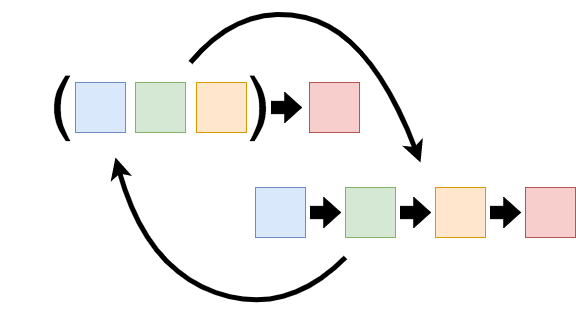
Hiểu đơn giản nếu hàm gốc của chúng ta yêu cầu một danh sách các đối số, khi thực hiện currying mỗi đối số sẽ được truyền cho một hàm trong chuỗi các hàm liên tiếp nhau. Hàm đầu tiên trong chuỗi sẽ khởi tạo cho tham số đầu tiên và trả về một hàm nhận vào đối số thứ hai. Hàm thứ hai trong chuỗi sẽ khởi tạo cho tham số thứ hai và trả về một hàm nhận vào đối số thứ 3, vân vân và mây mây 
Currying là quá trình phân tách một hàm với arity cao thành chuỗi các unary function.
Curried function là một hàm chỉ nhận vào một đối số duy nhật tại một thời điểm xác định (khi thực hiện lời gọi hàm).
Chúng ta có thể sử dụng hàm curry trong thư viện Ramda. Tuy nhiên hãy thử tạo hàm đó một cách thủ công như sau:
function curry(func, arity = func.length) {
return (function nextCurried(prevArgs) {
return function curried(nextArg) {
var args = [...prevArgs, nextArg];
if (args.length >= arity) {
return func(...args);
} else {
return nextCurried(args);
}
};
})([]);
}
Trong hàm trên, prevArgs sẽ được khởi tạo là một mảng rỗng. Với mỗi lần gọi hàm, nextArg sẽ được thêm vào danh sách này.
- Nếu số lượng đối số hiện tại nhỏ hơn số
arityđược truyền vào, chúng ta sẽ tạo và trả về một hàm với nhiệm vụ nhận vào đối số tiếp theo (danh sách các đối số hiện tại cũng sẽ được truyền theo). - Trường hợp ngược tại ta sẽ gọi hàm gốc với các đối số đã thu thập được.
Trong hàm
curryở trên giá trịarityđược xác định dựa vàolengthproperty của hàm. Tuy nhiên việc xác định số arity dựa trên property này sẽ không còn chính xác khi hàm có các giá trị default hoặc sử dụng destructuring hoặc là một variadic function. Trong trường hợp này chúng ta cần xác định chính xác số arity và truyền vào theo tham số thứ hai của hàmcurry.
Hãy cùng xét một số ví dụ sử dụng hàm curry nói trên:
var curriedMax = curry(Math.max, 3)
curriedMax(45)(60)(25) // 60
curriedMax(45)(60)(25)(100) // Error!!!
function add(x, y) {
return x + y;
}
var nums = [1, 2, 3];
nums.map(curry(add)(3)) // 4 5 6
function sum(...nums) {
var total = 0;
for (var num of nums) {
total += num;
}
return total;
}
var curriedSum = curry(sum, 3);
curriedSum(1)(2)(3); // 6
partial(sum, 1, 2)(3)
Nếu muốn khởi tạo từng tham số của hàm, việc sử dụng curry sẽ hiệu quả hơn so với sử dụng hàm partial!
Hai hàm
curryvàpartialđều sử dụng closure để ghi nhớ các đối số đã được truyền vào cho đến khi số lượng đối số đã đầy đủ (lúc này hàm gốc sẽ được thực thi)
Một câu hỏi được đặt ra là tại sao chúng ta cần sử dụng partial function và currying function thay vì sử dụng trực tiếp các hàm đã có?
- Sử dụng các hàm gốc đòi hỏi chúng ta phải truyền toàn bộ các đối số cần thiết khi thực hiện lời gọi hàm. Khi sử dụng hai phương pháp trên, chúng ta có thể khởi tạo trước các tham số nếu cần thiết.
- Sử dụng hai phương pháp trên giúp cho việc composing các hàm trở nên dễ dàng hơn (chúng ta sẽ cùng bàn luận về function compositon trong phần sau của bài viết).
Hàm curry ở trên chỉ cho phép thực hiện trên một đối số, tuy nhiên khi sử dụng các thư viện như Ramda, chúng ta có thể thực hiện currying trên nhiều đối số cùng lúc (http://ramdajs.com/docs/#curry)
Chúng ta cũng có thể uncurrying một hàm về dạng cơ bản. Tuy nhiên các bạn có thể tìm hiểu thêm do bài viết có vẻ đã khá dài (http://ramdajs.com/docs/#uncurryN)
Ordering
Một nhược điểm của việc sử dụng partial function và currying function như phần trước là sự phụ thuộc vào vị trí của tham số cần khởi tạo. Đôi khi thứ tự của các tham số trong khai báo hàm không thật sự thuận tiện khi sử dụng currying. Trong Python chúng ta sẽ không gặp phải vấn đề này do ngôn ngữ có sử dụng named arguments.
Thứ tự của các tham số là quan trọng trong việc sử dụng currying một cách hiệu quả.
Như đã đề cập trong bài viết trước, chúng ta có thể sử dụng destructuring và object để thực hiện named arguments trong JavaScript. Trong trường hợp đó, vị trí của các tham số không còn là một vấn đề quan trọng khi thực hiện lời gọi hàm.
Để sử dụng partial / currying function với named arguments chúng ta sẽ dùng một phương thức khá phổ biến khi làm việc với các đối tượng trong JavaScript - Object.assign()
Với partial function thì sẽ khá đơn giản do initialArgs và subsequentArgs đều đã ở dạng object. Chúng ta có thể sử dụng trực tiếp phương thức Object.assign()
function partial(func, initialArgs) {
return function(subsequentArgs) {
return func(Object.assign({}, initialArgs, subsequentArgs));
};
}
Ở đây subsequentArgs có thể ghi đè một số giá trị khởi tạo trước trong initialArgs.
Chúng ta có thể sử dụng hàm partial trên như sau:
function add({x, y} = {}) {
return x + y;
}
var add10 = partial(add, {x: 10});
add10({y: 15}) // 25
Đối với currying function thì công việc có thể phức tạp hơn khi sử dụng named arguments. Trong phần trước, currying function của chúng ta đơn giản merging các tham số cho đến khi đặt được số arity cần thiết và thực hiện lời gọi hàm. Khi sử dụng named arguments, sẽ có một chút thay đổi trong hai công đoạn này.
function curry(func, arity = 1) {
return (function nextCurried(prevArgs) {
return function curried(nextArg = {}) {
var [key] = Object.keys(nextArg);
var args = Object.assign({}, prevArgs, {[key]: nextArg[key]});
if (Object.keys(args).length >= arity) {
return func(args);
} else {
return nextCurried(args);
}
};
})([]);
}
Ở đây thay vì kết hợp trực tiếp nextArg vào prevArgs, chúng ta sẽ sử dụng Object.keys() để lấy ra tên của property trong nextArgsvà sử dụng Object.assign() để mở rộng prevArgs (thêm hoặc ghi đè các property).
Chú ý chúng ta sử dụng {[key]: nextArg[key]} do key là một biến thông thường nên không thể sử dụng trực tiếp như tên của một property.
Trong phiên bản trước của hàm curry, nếu chúng ta currying quá số lượng arity sẽ có lỗi xảy ra (trong hầu hết các trường hợp). Tuy nhiên khi sử dụng named arguments đôi khi chúng ta có thể làm vậy mà không gặp lỗi (do bản chất của hàm Object.assign())
Hãy cùng xem xét một số ví dụ sử dụng hàm curry với hàm add của chúng ta ở trên:
var curriedAdd = curry(add, 2)
curriedAdd({x: 1})({y:2}) // 3
curriedAdd({x: 1})({y:2})({z: 3}) // Error!!!
curriedAdd({x: 1})({y:2})({y: 4}) // Error!!!
curriedAdd({x: 1})({x:2})({y: 4}) // 6
Kĩ thuật này cũng có thể được sử dụng khi các tham số của hàm được liệt kê riêng biệt thay vì sử dụng destructuring. Tuy nhiên việc này yêu cầu thêm một bước preprocessing đối với hàm của chúng ta để chuyển các tham số về dạng destructuring. Tuy nhiên trong thực tế rất ít khi chúng ta làm việc này. Do vậy bạn có thể tìm hiểu thêm trong các tài liệu khác.
You're Free
Bạn có thể tham khảo một số nguồn sau:
Composing Functions
Khi viết code chúng ta thường cố gắng để logic DRY nhất có thể. Mục đích cuối cùng là những việc lặp lại nhiều lần sẽ được cài đặt một lần và được sử dụng lại trong các phần khác nếu cần thiết - code reuse.
Code reuse có ý tưởng rất đơn giản tuy nhiên thực hiện nó không phải là điều dễ dàng. Nếu code của chúng ta quá chi tiết nó sẽ không thể sử dụng lại. Ngược lại nếu code quá tổng quát thì sẽ khó sử dụng ngay từ những bước đầu tiên.
Công việc của người lập trình nói chung là cân bằng giữa hai yếu tố đó. Xây dựng các mảnh ghép nhỏ có khả sử dụng lại một cách hiệu quả. Sau đó sử dụng các mảnh ghép cơ bản đó để xây dựng lên những hình khối phức tạp hơn.
Trong FP, các hàm (function) chính là các nốt nhạc và nhiệm của người sử dụng FP là tìm cách để sáng tác ra một bản nhạc từ các nốt nhạc đó. Nói cách khác, nhiệm vụ của chúng ta là tìm cách kết hợp các hàm riêng lẻ thành các hàm ghép compound functions phục vụ cho một nhiệm vụ nào đó khi xây dựng logic.
Function composition là một khái niệm nền tảng trong FP do nó cho phép người sử dụng khai báo các mô hình dữ liệu và các thay đổi trong trang thái.
Trong toán học, hợp của hai hàm và được kí hiệu là và định nghĩa là

Right-to-left Composition
Giả sử chúng ta có hai hàm như sau:
let getName = (firstName, lastName) => firstName + " " + lastName;
let greeting = (fullName) => 'Hello, ' + fullName;
Cách đơn giản nhất để kết hợp hai hàm này là sử dụng đầu ra của một hàm như đầu vào của hàm còn lại. Trong ví dụ bên dưới, đầu ra của hàm getName sẽ là đầu vào của hàm greeting.
greeting(getName('Vinh', 'Nguyen')); // "Hello, Vinh Nguyen"
Thứ tự thực hiện các hàm sẽ là từ phải qua trái (ngược với cách đọc thông thường) do vậy ta gọi cách này là right-to-left composition. Cụ thể:
Hãy cùng xét một ví dụ khác - string tokenizer (simple & stupid) sử dụng regular expression:
let tokenize = (text) => {
return String(text)
.toLowerCase()
.split(/\s|\b/)
.filter(token => /^[\w]+$/.test(token));
};
Hàm tokenize dùng để tách một đoạn text thành một mảng các từ (word) riêng biệt. Hãy cùng dùng thử hàm tokenize trên:
let text = "Taking that first step to understanding Functional Programming concepts
is the most important and sometimes the most difficult step.
But it doesn’t have to be. Not with the right perspective.";
let words = tokenize(text);
// "taking", "that", "first", "step", "to", "understanding", "functional",
// "programming", "concepts", "is", "the", "most", "important", "and",
// "sometimes", "the", "most", "difficult", "step", "but", "it", "doesn", "t",
// "have", "to", "be", "not", "with", "the", "right", "perspective"
Simple enough!
Giả sử chúng ta cần phải tìm danh sách các từ không lặp lại trong danh sách các từ đã được tách ra từ câu trong ví dụ trên. Chúng ta có thể viết một hàm tiện ích đơn giản sau:
let unique = (list) => {
let data = [];
for (let item of list) {
if (data.indexOf(item) === -1) {
data.push(item);
}
}
return data;
};
let uniqueWords = unique(words);
Chúng ta có thể loại bỏ biến trung gian words và ghép hai hàm unique và tokenize trong cùng một lời gọi hàm. Hơn nữa, nếu việc sử dụng hai hàm này cùng nhau là thường xuyên, chúng ta có thể tạo một compound function. Thứ tự thực thi các hàm sẽ vẫn từ phải qua trái hay từ các hàm bên trong qua các hàm bên ngoài. Trong phần sau của bài viết, chúng ta sẽ tìm hiểu cách thực hiện các hàm theo thứ tự giống với thứ tự đọc - left-to-right (hay pipe).
let uniqueWords = unique(tokenize(text));
function uniqueWords(text) {
return unique(tokenize(text));
}
Chúng ta có thể tổng quát hóa việc kết hợp của hai hàm bằng cách tạo một hàm tiện ích như sau:
// ES5
function compose(outerFunc, innerFunc) {
return function(value) {
return outerFunc(innerFunc(value));
};
}
// ES6
var compose = (outerFunc, innerFunc) => value => outerFunc(innerFunc(value));
Và sử dụng nó cho ví dụ ở trên:
let uniqueWords = compose(unique, tokenize)(text);
Trong hầu hết các thư viện FP, việc composing các hàm sẽ được thực hiện theo thứ tự từ phải qua trái. Hàm compose của chúng ta có tham số đầu tiên là outerFunc giống với thứ tự mà các hàm được viết trong code hay thứ tự đọc thông thường - từ trái qua phải.
Cách kết hợp hàm này không phải là mới, nó là cách mà chúng ta thường sử dụng hàng ngày trong lập trình. Điều quan trọng là chúng ta tìm ra được pattern của phương pháp và tổng quát hóa nó sử dụng hàm compose (cho trường hợp có hai hàm).
Extending to Multiple Functions
Trong phần trước chúng ta mới chỉ xét trường hợp kết hợp hai hàm. Tuy nhiên trên thực tế việc kết hợp nhiều hơn hai hàm với nhau là hoàn toàn khả thi.
Chúng ta cần thay đổi hàm compose ở phần trước để nhận vào một danh sách các hàm thay vì hai hàm:
function compose(...funcs) {
return function(value) {
var copiedFuncs = funcs.slice();
while(copiedFuncs.length > 0) {
value = copiedFuncs.pop()(value);
}
return value;
};
}
Ở đây chúng ta sử dụng rest operator để tập hợp các hàm truyền vào thành một mảng. Trong callback trả về, các hàm sẽ được lấy ra theo thứ tự từ phải qua trái (so với thứ tự truyền vào) sử dụng hàm pop của JavaScript array. value của chúng ta sẽ lần lượt đi qua các hàm theo thứ tự đó.
Một câu hỏi đặt ra là tại sao chúng ta phải sử dụng funcs.slice() thay vì sử dụng trực tiếp funcs?
Trước tiên funcs.slice() có nhiệm vụ sao chép mảng funcs gốc và lưu vào biến có tên copiedFuncs.
Trước khi tìm hiểu nguyên nhân, hãy thử bỏ dòng code đó và sử dụng hàm compose nhiều hơn một lần:
function compose(...funcs) {
return function(value) {
while(funcs.length > 0) {
value = funcs.pop()(value);
}
return value;
};
}
let operations = compose(x => x * 3, x => x + 2, x => x - 1);
operations(10); // 33 (Right)
operations(10); // 10 (Wrong)
Có thể thấy kết quả chỉ đúng khi gọi hàm operations lần đầu tiên, đến lần thứ hai giá trị truyền vào 10 sẽ được trả về trực tiếp mà không đi qua các hàm đã được composing.
Vấn đề ở đây có liên quan đến immutability. funcs không phải là một mảng khi truyền đối số cho hàm. Chúng ta sử dụng rest operator để tập hợp các hàm truyền vào. Do funcs ở đây là local đối với hàm compose nên sẽ không cần lo lắng các side effects khi sử dụng. Nói cách khác chúng ta có thể thay đổi funcs bên trong hàm compose một cách an toàn mà không sợ ảnh hưởng đến các logic khác. Tuy nhiên callback bên trong hàm compose - một closure có truy cập và sử dụng funcs không phải là local đối với hàm compose. Trong lần gọi hàm đầu tiên, chúng ta đã thay đổi funcs, khi hàm kết thúc funcs sẽ là một mảng rỗng. Do đó trong lần gọi thứ hai, giá trị của value sẽ được trả về nguyên vẹn - tất nhiên không phải điều chúng ta mong muốn.
Mình sẽ đề cấp đến immutability và side effects trong một bài viết khác gần nhất có thể.
Nếu sử dụng hàm compose có sử dụng slice (hoặc bất cứ cách nào có thể tạo một bản copy của array) kết quả trả về sẽ là 33 qua các lần gọi.
Xét một ví dụ nữa sử dụng hai hàm tokenize và unique ở phần trước. Giả sử vì một lý do nào đó, chúng ta cần chuyển mảng các từ thành dạng in hoa sử dụng hàm tiện ích đơn giản sau:
let uppercase = (words) => words.map(unary(toUpperCase));
Chúng ta có thể thực hiện đơn giản như sau:
let uniquelyUppercase = compose(uppercase, unique, tokenize);
uniquelyUppercase("There are many benefits from using the point-free notation");
// "THERE", "ARE", "MANY", "BENEFITS", "FROM",
// "USING", "THE", "POINT", "FREE", "NOTATION"
Chúng ta có thể sử dụng hàm
partialRight(compose, ...)hoặccurry(reverseArgs(compose), ...)để truyền trước một số hàm chocomposefunction - tạo sự mềm dẻo khi viết code.
Thư viện Ramda cung cấp cho chúng ta một số hàm phục vụ cho function composition, các bạn có thể tham khảo thêm:
Other Implementations
Trong cách viết hàm compose ở phần trước, chúng ta sử dụng một vòng for để duyệt qua danh sách các hàm từ phải qua trái, sử dụng hàm đó trên value và gán lại giá trị cho nó. Đây là một ví dụ mà chúng ta có thể thay thế vòng for bằng việc sử dụng reduction. Trong JavaScript, chúng ta sẽ sử dụng hàm reduce của Array.
But, wait a minute!
Nhớ rằng các hàm của chúng ta được thực thi từ phải qua trái. Do đó nếu sử dụng reduce thì thứ tự sẽ không có đúng. Ở đây chúng ta có hai cách thực hiện:
- Sử dụng
funcs.reverse().reduce() - Sử dụng
funcs.reduceRight()
Để ngắn gọn, chúng ta sẽ sử dụng cách thứ hai như sau:
function compose(...funcs) {
return function composing(value) {
return funcs.reduceRight(function(value, func) {
return func(value);
}, value);
};
}
Ưu điểm của cách này là code được viết theo đúng tinh thần của FP hơn. Tuy nhiên, hiệu năng không có gì thay đổi so với cách làm trong phần trước. Nhược điểm ở đây và hàm composing (callback bên trong hàm compose) chỉ nhận vào duy nhất một đối số. Tuy nhiên thông thường chúng ta sẽ có nhiều đối số khác nhau. Cách làm này hoàn toàn ổn nếu các hàm đều ở dạng unary. Tuy nhiên nếu muốn truyền nhiều hơn một đối số trong lần gọi hàm đầu tiên chúng ta cần thay đổi cách viết hàm compose như các cách sau đây.
Để giải quyết vấn đề giới hạn số lượng đối số cho lần gọi hàm đầu tiên trong cách trước, chúng ta sẽ vẫn sử dụng hàm reduceRight. Tuy nhiên, vị trí của nó được đổi cho hàm composing. Giá trị trả về của hàm reduceRight ở đây là một hàm (không phải là một giá trị đã được tính toán). Do đó chúng ta có thể truyền một hoặc nhiều đối số cho lần gọi hàm đầu tiên thông qua args.
Thay vì tính toán giá trị của từng lời gọi hàm và truyền giá trị đó cho hàm tiếp theo như trong cách sử dụng vòng for. Ở đây reduceRight sẽ được chạy một lần khi composing tạo thành một lớp các hàm xếp chồng nhau. Giá trị mong muốn chỉ được xác định khi chúng ta thực hiện lời gọi hàm trên composed function với các đối số cụ thể.
Về hiệu năng thì cách này tốt hơn cách ban đầu do reduceRight chỉ được thực hiện một lần duy nhất để tạo ra một composed function duy nhất. Khi các đối số được truyền vào các hàm trong composed function sẽ được thực thi từ trong ra ngoài. Trong cách đầu tiên reduceRight sẽ được chạy cho mỗi lần thực hiện lời gọi hàm.
Dưới đây là cách viết hàm compose và ví dụ sử dụng:
function compose(...funcs) {
return funcs.reduceRight(function(func1, func2) {
return function composing(...args) {
return func2(func1(...args));
};
});
}
let fullName = (firstName, lastName) => firstName + " " + lastName;
let uppercase = text => text.toUpperCase();
let greeting = name => "Hello " + name;
let sayHello = compose(uppercase, greeting, fullName);
sayHello('Vinh', 'Nguyen'); // HELLO VINH NGUYEN
Chúng ta cũng có thể cài đặt hàm compose sử dụng đệ quy recursion. Tuy nhiên hãy cùng tìm hiểu điều này trong bài viết về recusion 
Left-to-right Composition
Nếu bạn đã từng sử dụng Linux và làm việc sử dụng các shell commands, chắc hẳn bạn đã từng nghe đến khái niệm pipe - |. Trong đó đầu ra của một lệnh sẽ là đầu vào của một lệnh khác. Điều quan trọng là các lệnh được liệt kê theo thứ tự thực hiện từ trái qua phải - thuận tiện cho việc đọc của chúng ta.
Chúng ta sẽ áp dụng ý tưởng đó để viết lại hàm compose của chúng ta với thứ tự các hàm truyền vào đúng theo thứ tự được thực thi. Để thuận tiện chúng ta sẽ gọi hàm là pipe thay vì compose (ở đây mình chỉ viết ở dạng sử dụng vòng for):
function pipe(...funcs) {
return function(value){
var copiedFuncs = funcs.slice();
while (copiedFuncs.length > 0) {
value = copiedFuncs.shift()(value);
}
return value;
};
}
Điểm khác biệt duy nhất ở đây là thứ tự các tham số và chúng ta sử dụng hàm shift thay vì pop như trong hàm compose ở trên.
Chúng ta cũng có thể định nghĩa hàm pipe đơn giản như sau:
let pipe = reverseArgs(compose);
Để khởi tạo sẵn một số hàm cho pipe chúng ta có thể sử dụng hàm partial thay vì hàm partialRight.
Thư viện Ramda cũng đã cung cấp sẵn cho chúng ta hàm pipe: http://ramdajs.com/docs/#pipe
Point-Free
Trong phần trước, mình có để một số đường link tham khảo đến Point-free. Nói một cách ngắn gọn, Point-free programming hay Point-free notation là một cách viết hàm sử dụng composition  Khi sử dụng phương pháp này chúng ta sẽ hạn chế việc sử dụng các biến trung gian (temporary variables) từ đó làm cho logic trở nên đơn giản hơn và hạn chế bugs. Hơn nữa việc sử dụng các module nhỏ và chuyên biệt giúp cho việc test các module đó dễ dàng hơn và mang lại sự tin cậy cao hơn.
Khi sử dụng phương pháp này chúng ta sẽ hạn chế việc sử dụng các biến trung gian (temporary variables) từ đó làm cho logic trở nên đơn giản hơn và hạn chế bugs. Hơn nữa việc sử dụng các module nhỏ và chuyên biệt giúp cho việc test các module đó dễ dàng hơn và mang lại sự tin cậy cao hơn.
Vậy nó có liên quan gì đến function composition ở đây?
Hãy cùng xét một ví dụ. Giả sử chúng ta có một danh sách các users và mỗi user sẽ có một địa chỉ e-mail cũng như một role nhất định. Công việc của chúng ta là lọc ra địa chỉ e-mail của các users có role là editor.
OK, nếu sử dụng imperative programming chúng ta sẽ viết một hàm như sau:
var getEditorEmails = function(users) {
var emails = [];
for (var i = 0; i < users.length; i++) {
if (users[i].role === 'editor') {
emails.push(users[i].email);
}
}
return emails;
}
Hàm khá đơn giản nên mình sẽ không giải thích ở đây. Để hiểu được đoạn logic trên, chúng ta cần đi qua từng dòng lệnh và xem nó đang thực hiện việc gì. Tuy nhiên việc này không đúng theo ý tưởng của FP.
Hãy dừng lại một chút để xem yêu cầu của task và liệt kê các công việc cần làm. Có hai việc như sau:
- Lấy ra email của một người dùng
- Kiểm tra xem người dùng có phải là một editor hay không
Nếu sử dụng function composition chúng ta sẽ định nghĩa như sau:
let getEditorEmails = compose(getEmailsOf, editors);
Ở đây getEmailsOf và editors chúng ta chưa biết chúng sẽ thực hiện như thế nào. Tuy nhiên khi lập trình, một cách khá phổ biến là định nghĩa trước interface (mình không có ý nói đến các interface trong các ngôn ngữ lập trình) mà bạn muốn code của bạn sẽ giống như vậy khi hoàn thành. Sau đó sẽ xây dựng các logic khác dựa trên interface đó.
Bắt đầu với hàm getEmailsOf. Hàm này có nhiệm vụ trả về danh sách các địa chỉ e-mail từ danh các users. Vậy chúng ta cần thực hiện hai việc nhỏ hơn: lấy ra property của một đối tượng và mapping danh sách các đối tượng. Hãy cùng định nghĩa các hàm tổng quát cho hai việc trên:
let prop = p => obj => obj[p];
let map = callback => list => list.map(callback);
Và sử dụng chúng để định nghĩa hàm getEmailsOf như sau:
let getEmailsOf = map(prop('email'));
Simple enough!
Đối với hàm editors mọi thứ phức tạp hơn một chút do chúng ta phải thực hiện việc kiểm tra property. Trong Ramda chúng ta có hàm propEq. Tuy nhiên hãy cùng cài đặt thủ công ở đây.
let propEq = val => p => obj => prop(p)(obj) === val;
Tiếp đến chúng ta cần lọc danh sách các users dựa trên role của họ. Đây là lúc thích hợp để định nghĩa hàm filter. Cụ thể:
let filter = predicate => list => list.filter(predicate);
Sử dụng propEq và filter chúng ta có thể cài đặt hàm editors như sau:
let editors = filter(propEq('editor')('role'));
Chúng ta có thể viết lại hàm getEditorEmails như sau:
let getEditorEmails = compose(map(prop('email')), filter(propEq('editor')('role')));
Not too complicated!
Hãy cùng sử dụng hàm getEditorEmails qua một ví dụ đơn giản:
let users = [
{ email: 'foo@bar.com', role: 'admin' },
{ email: 'bar@baz.com', role: 'editor' },
{ email: 'baz@fizz.com', role: 'editor' },
{ email: 'fizz@fuzz.com', role: 'editor' },
];
let editorEmails = getEditorEmails(users);
// bar@baz.com
// baz@fizz.com
// fizz@fuzz.com
Điều cần ghi nhớ ở đây là chúng ta phân tách một hàm phức tạp bằng cách sử dụng các hàm nhỏ và tổng quát (có thể hiểu trong vòng 1 vài giây ). Tuy nhiên bạn cũng không nên biến tất cả các hàm thành dạng point-free.
Please, make up your own mind, and choose the right decision!
Thoughts
Sử dụng function composition là một phương pháp để thực hiện được mục tiêu của declarative programming thay vì imperative programming
Hiểu một cách đơn giản, imperative cho chúng ta biết các bước để thực hiện một việc - how, trong khi đó declarative cho chúng ta biết về đầu ra, kết quả (outcome) của việc đó - what.
Composing các hàm sử dụng hàm compose cho chúng ta biết cách một công việc được thực hiện (imperative). Tuy nhiên việc composing không diễn ra lặp đi lặp lại, kết quả của nó sẽ được sử dụng trong các phần khác. Ở đây cách thức thực hiện đã được ẩn đi bởi hàm compose, chúng ta chỉ quan tâm đến đầu ra của composed function mà thôi (declarative).
Chúng ta nên sử dụng quy tắc DRY, tuy nhiên không nên lạm dụng nó do code của chúng ta sẽ trở nên quá trừu tượng (abstraction) dẫn đến khó khăn trong việc đọc hiểu và đôi khi là sử dụng lại sau này.
Việc thêm các lớp trừu tượng (abstraction) cho code là cần thiết. Tuy nhiên trừu tượng ở đây không có nghĩa là ẩn đi càng nhiều code càng tốt. Trừu tượng giúp chúng ta tập trung vào một chi tiết nhất định nào đó thay vì phải quan tâm đến các chi tiết phức tạp khác. Nói cách khác trong mỗi phân đoạn, một chi tiết nào đó sẽ có độ ưu tiên cao hơn, những chi tiết khác coi như đã chính xác và chúng ta chỉ cần quan tâm đến outcome của chúng mà thôi.
Composition là một công cụ hữu ích để chuyển đổi imperative code thành declarative code.
A Recap

References
All rights reserved
