[Elasticsearch Series] P3: Documents, Types và Indices trong ElasticSearch
Bài đăng này đã không được cập nhật trong 6 năm
Hi các bạn, nếu như Phần 1 và Phần 2 mình đã giới thiệu một cách tổng quát nhất về Elasticsearch là gì, Elasticsearch có gì hấp dẫn và các trường hợp (bối cảnh) sử dụng Elasticsearch thì từ Phần 3 này, mình sẽ đi vào cụ thể hơn các định nghĩa cũng các ví dụ để giúp các bạn dễ hiểu hơn. Nội dung của Phần 3:
■ Các định nghĩa về Documents, Types và Indices
Nhìn qua phần mục giới thiệu có thể khiến bạn hơi sợ hãi và khó hiểu vì có nhiều thuật ngữ mới mẻ đối với một newbie, song xuyên suốt bài viết này, chúng ta sẽ cùng tìm hiểu và làm rõ từng thứ một cho đến hết thì thôi. OK Let's get started!
Chắc hẳn bây giờ bạn đã biết Elaticsearch là một công cụ giúp tìm kiếm hiệu quả và đơn giản hóa việc tìm kiến thông qua một số tính năng chính của nó đã được giới thiệu ở phần trước. Hãy tiếp tục chuyển sang khía cạnh thực tế và xem nó hoạt động như thế nào nhé. Tưởng tượng xem bạn có nhiệm vụ tạo ra một tính năng tìm kiếm trong một dataset hàng triệu tài liệu cho một trang web cho phép mọi người xây dựng các nhóm sở thích chung và tập hợp họ lại với nhau. Trong phần này, tôi sẽ hướng dẫn cách xử lý tình huống như vậy bằng cách giải thích cách tổ chức dữ liệu của Elaticsearch. Sau đó, bạn sẽ bắt đầu lập chỉ mục (indexing) và tìm kiếm một số dữ liệu thực cho một trang web. Tất cả các hoạt động sẽ được thực hiện bằng cURL, một công cụ dòng lệnh để gửi các yêu cầu HTTP. Sau này bạn có thể dịch những gì cURL làm sang ngôn ngữ lập trình ưa thích của bạn nếu bạn cần.
Chúng ta sẽ nhìn nó từ hai góc độ: logic và vật lý
■ Về mặt logic: Đơn vị bạn sử dụng để lập chỉ mục và tìm kiếm là một document (tài liệu) và bạn có thể nghĩ nó giống như một hàng(row) trong cơ sở dữ liệu quan hệ. Các document(tài liệu) được nhóm thành các type(loại), trong đó chứa các document(tài liệu) theo cách tương tự như cách các bảng chứa các hàng. Cuối cùng, một hoặc nhiều types(loại) tồn tại trong một index(chỉ mục), index được coi như một thùng chứa lớn nhất, tương tự như cơ sở dữ liệu trong thế giới SQL vậy.
■ Về mặt vật lý: Elaticsearch chia mỗi index thành các shards(có thể tạm dịch là phân đoạn), shards có thể di chuyển giữa các servers(máy chủ) tạo thành một cluster(cụm). Thông thường, các ứng dụng không liên quan đến vấn đề này bởi vì chúng hoạt động với Elaticsearch theo cách tương tự, cho dù đó là một hoặc nhiều máy chủ. Nhưng khi bạn quản lý cụm, bạn cần quan tâm bởi vì cách bạn định cấu hình bố cục vật lý sẽ xác định hiệu suất, khả năng mở rộng và tính khả dụng của nó.
 Đầu tiên hãy đi tìm hiểu và phân tích từ góc nhìn logic: những gì ứng dụng thấy
Đầu tiên hãy đi tìm hiểu và phân tích từ góc nhìn logic: những gì ứng dụng thấy
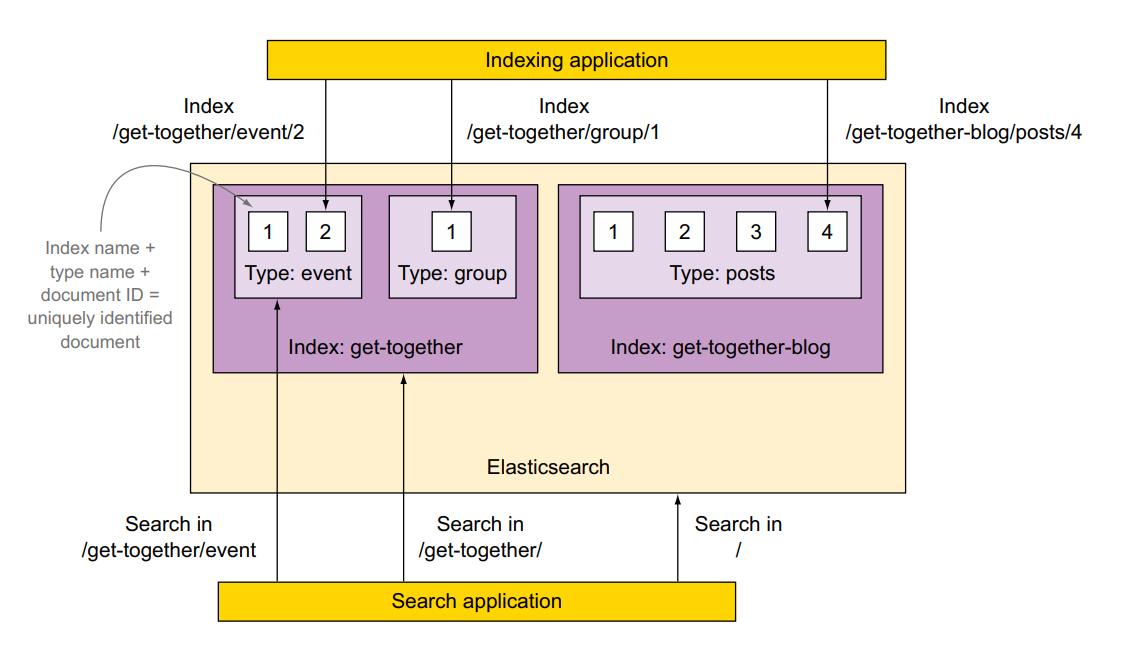
Khi bạn lập chỉ mục một tài liệu trong Elaticsearch, bạn đẩy các tài liệu vào một loại trong một index. Bạn có thể thấy ý tưởng này trong hình dưới đây, trong đó index kết hợp chứa hai loại: event(sự kiện) và grop(nhóm). Các type thì có chứa document (tài liệu), chẳng hạn như loại có label 1(nhãn 1)
Sự kết hợp index-type-ID giúp xác định duy nhất một document trong data Elaticsearch của bạn. Khi bạn tìm kiếm, bạn có thể tìm tài liệu theo type cụ thể đó, của index cụ thể đó hoặc bạn có thể tìm kiếm trên nhiều loại hoặc thậm chí nhiều indices
Bây giờ câu hỏi hiện ra trong đầu của các bạn liệu có phải là: chính xác documents, types và indices là gì? Hãy cùng đi tìm hiểu tiếp nhé.
Documents
Chúng ta đã từng nói trong chương 1 rằng Elaticsearch document-oriented (hướng tài liệu), nghĩa là đơn vị dữ liệu nhỏ nhất mà bạn lập index hoặc tìm kiếm là một tài liệu. Một document(tài liệu) có một vài thuộc tính quan trọng như sau:
- Document có tính khép kín. Mộtdocument chứa cả các trường và các giá trị của chúng
- Document có thể được phân cấp. Điều này có thể hiểu như là tài liệu trong các tài liệu hay tài liệu chứa tài liệu - lồng nhau. Giá trị của một trường có thể đơn giản, như giá trị của trường vị trí có thể là một chuỗi, nó cũng có thể chứa các trường và giá trị khác. Ví dụ: trường vị trí có thể chứa cả thành phố và địa chỉ đường phố trong đó.
- Document có cấu trúc linh hoạt. Document thì không phụ thuộc vào một schema (lược đồ) được xác định trước. Ví dụ: không phải tất cả các even(sự kiện) đều cần các giá trị mô tả, do đó trường đó có thể được bỏ qua hoàn toàn. Nhưng nó có thể yêu cầu các trường mới, chẳng hạn như vĩ độ và kinh độ của vị trí, điều này thể hiện document trong ES có cấu trúc cực kì linh hoạt và hạn chế tối đa sự ràng buộc.
Một document có cấu trúc như một chuỗi JSON vậy, như chúng ta đã thảo luận trong chương 1, JSON được gửi qua HTTP là cách được sử dụng rộng rãi nhất để giao tiếp với Elaticsearch và nó sẽ là phương pháp chúng ta sử dụng trong suốt các phần loạt bài hướng dẫn của mình. Ví dụ: một evetnt (sự kiện) trong trang web của bạn có thể được trình bày trong document sau:
{
"name": "Elasticsearch HN",
"organizer": "Nam",
"location": "Me Tri, Nam Tu Liem, Ha Noi"
}
Bạn cũng có thể tưởng tượng một bảng có ba cột: tên, người tổ chức và vị trí. Document sẽ là một hàng chứa các giá trị. Nhưng thật ra có một số khác biệt làm cho sự so sánh này không thật sự chính xác. Một sự khác biệt là, không giống như các hàng, tài liệu có thể được phân cấp. Ví dụ: vị trí có thể chứa tên và vị trí địa lý kinh độ vĩ độ chẳng hạn:
{
"name": "Elasticsearch HN",
"organizer": "Nam",
"location": {
"name": "Me Tri, Nam Tu Liem, Ha Noi",
"geolocation": "50.7392, -104.9897"
}
}
Một document cũng có thể chứa các mảng giá trị, ví dụ như:
{
"name": "Elasticsearch HN",
"organizer": "Nam",
"members": ["Nam", "Hung", "Thanh"]
}
Các document trong Elaticsearch là schema-free (không có lược đồ), có thể hiểu điều này theo nghĩa là không phải tất cả các document(tài liệu) của bạn cần phải có cùng các trường, vì vậy chúng không bị ràng buộc với cùng một lược đồ, bạn hoàn toàn có thể bỏ qua vị trí chẳng hạn.
Types
Có thể nói Types là các thùng chứa các document, tương tự như bảng là thùng chứa cho các hàng. Bạn đặt các document với các cấu trúc khác nhau vàp các types khác nhau.
Định nghĩa của các trường trong mỗi loại được gọi là mapping-types. Ví dụ: tên sẽ được ánh xạ dưới dạng chuỗi, nhưng trường định vị địa lý theo vị trí sẽ được ánh xạ dưới dạng loại Geo_point đặc biệt. Bạn có thể tự hỏi: nếu Elaticsearch không có lược đồ, tại sao mỗi tài liệu thuộc về một loại và mỗi loại chứa một mapping-types, giống như một lược đồ, có điều gì đó sai sai chăng?
Nói là phi lược đồ vì các tài liệu không bị ràng buộc với lược đồ. Chúng yêu cầu phải có tất cả các trường được xác định trong ánh xạ của bạn và có thể đưa ra các trường mới thoải mái. Vậy, nó hoạt động thế nào? Đầu tiên, ánh xạ tập hợp và chứa tất cả các trường của tất cả các tài liệu được lập index cho đến nay trong type đó. Nhưng không nhất thiết phải tất cả các documents phải có tất cả các fields(trường).
Ngoài ra, nếu một tài liệu mới được lập chỉ mục với một trường mà không có trong mapping-types, Elaticsearch sẽ tự động thêm trường mới đó vào ánh xạ của bạn. Để thêm trường đó, nó phải quyết định loại dữ liệu cho trường đó là gì, ES sẽ tự đoán. Ví dụ: nếu giá trị là 7, thì nó giả sử nó sẽ xác định đây là kiểu long. Việc tự động phát hiện các trường mới này tất nhiên sẽ có nhược điểm riêng của nó bởi vì Elaticsearch hoàn toàn có thể không đoán đúng. Thực tế trong sản phẩm, cách an toàn nhất là xác định ánh xạ của bạn trước khi lập chỉ mục dữ liệu. Mapping-types chỉ phân chia các tài liệu về mặt logic. Về mặt vật lý, các tài liệu từ cùng một chỉ mục sẽ được ghi vào đĩa bất kể loại ánh xạ mà chúng thuộc về.
Indices
Các indice là các thùng chứa cho các types. Một index Elaticsearch là một khối tài liệu độc lập, giống như một cơ sở dữ liệu trong thế giới quan hệ: mỗi index được lưu trữ trên đĩa trong cùng một tập hợp các tệp; nó lưu trữ tất cả các trường từ tất cả các loại ánh xạ trong đó và nó có các cài đặt riêng. Ví dụ: mỗi chỉ mục có một cài đặt được gọi là refresh_interval, xác định khoảng thời gian mà các tài liệu mới được lập index sẵn sàng cho các tìm kiếm. Thao tác làm mới này khá tốn kém về mặt hiệu năng và đây là lý do tại sao nó được thực hiện theo cách mặc định, theo từng giây một, thay vì thực hiện sau mỗi tài liệu được đánh index.
Một ví dụ về cài đặt dành riêng cho index là số lượng shards. Bạn đã thấy trong chương 1 rằng một chỉ mục có thể được tạo thành từ một hoặc nhiều khối được gọi là shards. Việc này tốt cho khả năng mở rộng: bạn có thể chạy Elaticsearch trên nhiều máy chủ và có các shards có cùng chỉ mục sống trên tất cả chúng.
Okay, ở bài viết này, bạn đã được giới thiệu về Documents, Types cũng như Indices thông qua ví dụ hết sức cơ bản, phần tiếp theo mình sẽ giới thiệu các định nghĩa về các thành phần cấu thành ES tiếp theo là nodes, shards và clusters. Have fun! Bài viết được tham khảo từ cuốn sách ElasticSearch In Action (Matthew Lee Hinman and Radu Gheorghe)
All rights reserved
