Đôi chút về Label Assignment trong Object Detection
Mở đầu
Label assignment đóng vai trò quan trọng trong việc huấn luyện các mô hình object detection, quyết định cách gán các ground-truth boxes cho các anchor boxes hoặc các vị trí dự đoán trên feature map. Đây được xem như "cầu nối" quan trọng giữa dữ liệu ground-truth và các dự đoán của mô hình, trực tiếp ảnh hưởng đến chất lượng của quá trình học.
Từ các phương pháp truyền thống sử dụng các quy tắc cứng dựa trên IoU, đến các kỹ thuật thống kê và chi phí, và gần đây là các phương pháp tự học dựa trên neural network, label assignment đã trải qua nhiều giai đoạn phát triển đáng kể. Mỗi cải tiến trong label assignment không chỉ nâng cao độ chính xác của việc phát hiện đối tượng mà còn góp phần tối ưu hóa quá trình huấn luyện, đặc biệt trong việc xử lý các thách thức như sự mất cân bằng mẫu và đa dạng kích thước đối tượng.
Nội dung của bài viết này tập trung vào việc làm rõ Label Assignment (LA) ở các khía cạnh khái niệm, mục đích, ứng dụng và giải thích qua một số phương pháp LA phổ biến. Hi vọng các bạn tìm được gì đó mới mẻ qua bài viết này.
Tổng quan
Trong khoảng 10 năm trở lại đây, Label Assignment (LA) là một trong những kĩ thuật cực kì quan trọng giúp tối ưu hiệu suất của mô hình nhận diện vật thể (object detection) trong cả nhiệm vụ phân loại nhãn và hồi quy bounding box.
Về khái niệm, hãy hiểu đơn giản rằng, mô hình object detection có 2 nhiệm vụ: phân loại nhãn đối tượng (classification) và xác định vị trí của vật thể (localization). Để có thể vẽ được bounding box bao quanh đối tượng thì trong quá trình huấn luyện, nó sẽ cố gắng điều chỉnh vị trí và kích thước của những "base of bounding box" (được mô hình khởi tạo ban đầu: anchor boxes/points, các special points,...) về vị trí của ground truth. Tuy nhiên, việc điều chỉnh số lượng nhiều "bounding box" như vậy có thể khiến mô hình bị chậm lại và giảm độ chính xác của bounding box cuối cùng. Do đó, label assignment ra đời nhằm giải quyết vấn đề này bằng cách phân loại xem "bounding box" nào nên được điều chỉnh (positive) và phần còn lại thì bỏ qua (negative).
Label Assignment có thể được chia làm 2 loại: anchor-based với anchor boxes và anchor-free với anchor points. Mỗi loại đều có những ưu nhược điểm riêng và mình sẽ từ từ giải thích ở các phần sau.
Quá trình phát triển
Ý tưởng của Label Assignment đã xuất hiện từ khá sớm, quan điểm của mỗi người có thể khác nhau nhưng đối với mình, LA bắt đầu được định hình từ những năm 2013-2014, với sự ra mắt của R-CNN 1; sự phân chia giữa positive/negative samples thông qua vùng quan tâm (region proposals) là một ví dụ của LA.
Anchor-based
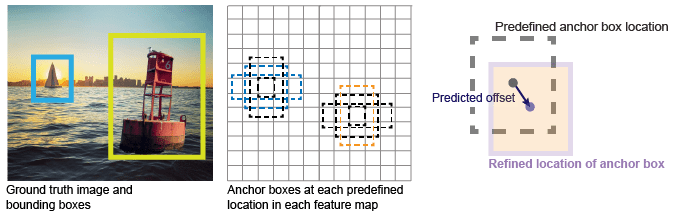
Năm 2015, Faster R-CNN 2 ra đời và đóng vai trò quan trọng trong việc tiêu chuẩn hóa và phổ biến quy trình label assignment trong phát hiện đối tượng, đặc biệt thông qua việc sử dụng anchor boxes. Anchor boxes trong mô hình anchor-based (Faster R-CNN, SSD, RetinaNet,...) thực tế là những hình chữ nhật có các kích thước khác nhau được ta quy định sẵn ngay từ lúc bắt đầu huấn luyện, mục đích huấn luyện của mô hình là "kéo" những anchors này về vị trí của ground truth từ đó tạo ra bounding boxes cuối cùng mà chúng ta nhìn thấy.
Các "hình chữ nhật" này được đặc trưng bởi 2 yếu tố: vị trí và kích thước - đây cũng là 2 yếu tố ta phải định nghĩa cho mô hình ngay từ đầu. Trong khi vị trí thường được chọn ở trung tâm của các ô grid (với đa số các mô hình), thì kích thước được xác định qua 2 tham số khác: tỉ lệ (ratio) và độ phóng đại (scale). Tỉ lệ là tỉ lệ giữa 2 chiều của anchor box thường được quy định dựa trên dataset nghĩa là nếu dataset chứa nhiều đối tượng con người ta nên có anchor box có tỉ lệ 1:2. Còn scale quy định kích thước của các anchor phóng to, thu nhỏ đi bao nhiêu lần so với anchor base.
Một thông tin ngoài lề một chút, trong thời gian này cũng xuất hiện phiên bản đầu tiên của YOLO - họ mô hình rất nổi tiếng hiện tại - YOLOv1. YOLOv1 chia ảnh thành các grid cell, dự đoán xem cell nào chứa tâm của đối tượng và cell đó sẽ có nhiệm vụ dự đoán, điều chỉnh bounding box. Điều đó dẫn đến một hạn chế rằng nếu có nhiều hơn 1 đối tượng trong 1 cell thì mô hình sẽ khó nhận diện được cả 2 đối tượng, tỉ lệ recall thấp và phải đến YOLOv2 (2016) anchor boxes mới được sử dụng, giúp khắc phục đáng kể tình trạng này.
Anchor-free

Sau đó, đến năm 2018 với phát súng đầu tiên là CornerNet, sau đó đến CenterNet (2019) và nổi bật là mô hình FCOS (2019) gây được sự chú ý lớn của cộng đồng tới mô hình anchor-free. Hãy lưu ý rằng, anchor-free không phải tên một loại chiến lược gán nhãn cụ thể mà nó là tập hợp của các phương pháp LA không sử dụng đến anchor boxes. Chính vì thế, mà ta có thể chia anchor-free ra thành 2 loại chính 3:
- Các mô hình Keypoint-based methods
- Các mô hình Center-based method
Đối với các mô hình Keypoint-based, mô hình sẽ phát hiện những điểm đặc biệt được xác định trước hoặc tự học, sau đó vẽ bounding box từ những điểm này. Ví dụ như CornerNet xác định bounding box từ 2 điểm top-left và bottom-right. ExtremeNet phát hiện 4 điểm cực trị (trên cùng, ngoài cùng bên trái, dưới cùng và ngoài vùng bên phải). RepPoints 4 xác định các điểm đại diện (representation points) cho hình dạng và kích thước của vật thể, từ đó có thể tính toán được tọa độ tối ưu cho bounding box.
Còn với các mô hình thuộc Center-based method, ý tưởng chung khá giống với ý tưởng của anchor boxes: đều xác định các positive/negative samples để điều chỉnh bounding box. Điểm khác biệt giữa 2 phương pháp nằm ở chỗ: Anchor-based sử dụng anchor boxes là những hình chữ nhật được định sẵn vị trí và kích thước - khiến chúng trở thành 2 loại hyper-parameters - trong khi, anchor-free sử dụng anchor point để dự đoán khoảng cách từ điểm đó tới 4 cạnh của bounding box, mặc dù vẫn định sẵn vị trí (thường là gần tâm của object) nhưng siêu tham số về kích thước đã được giảm đi. (Nếu các bạn để ý thì YOLOv1 cũng có thể được coi là một mô hình thuộc loại này 3)
RetinaNet & FCOS
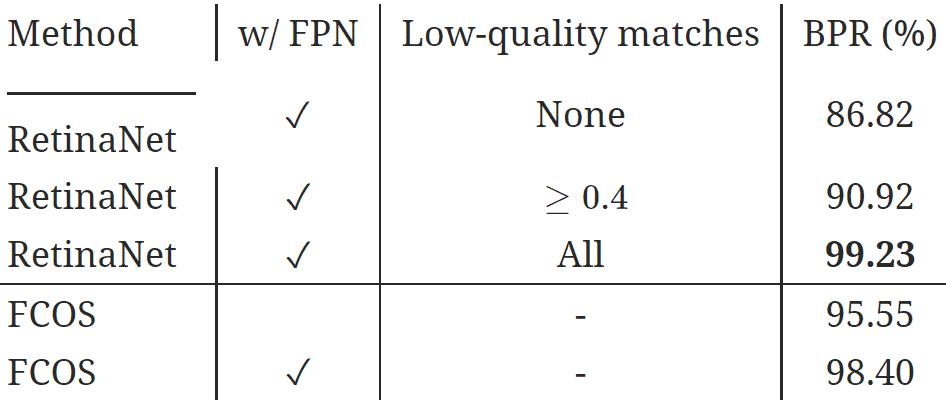
Trong khoảng từ 2017-2019, RetinaNet 5 và FCOS 6 có lẽ là 2 đại diện nổi bật cho xu hướng của Label Assignment giai đoạn này. RetinaNet cải thiện việc mất cân bằng giữa positive và negative anchor boxes bằng Focal Loss, sử dụng 9 loại anchor boxes và lấy ngưỡng IoU là 0.5. FCOS đặt ra những quy chuẩn về khoảng hồi quy từ candicate positve points ở các stride khác nhau nhằm chọn ra những positive samples tốt nhất đồng thời kết hợp Classification với Centerness để khắc phục tình trạng classification tốt mà bounding box hồi quy chưa tốt. Dù có nhiều cải tiến nhưng các mô hình này vẫn dựa vào các quy tắc được định sẵn như kích thước anchor boxes, khoảng hồi quy ,... khó tối ưu cho nhiều bài toán khác nhau.
ATSS

Những nghiên cứu sau, từ 2019 - 2021, chủ yếu nhằm khắc phục tình trạng khó kiểm soát hyperparameters của những mô hình trước. ATSS 7 (Adaptive Training Sample Selection) nhận thấy điểm hạn chế của RetinaNet và FCOS nên đã đề xuất 1 phương án LA kết hợp ưu điểm của 2 mô hình trên: với mỗi ground truth ta chọn được các candicate positive samples (như FCOS); sau đó chọn k anchor boxes trong đó có center gần với gt nhất ở mỗi stride; tính IoU của k anchor boxes đó với gt và threshold được xác định bằng tổng giá trị trung bình với độ lệch chuẩn của phân phối IoU đó. ATSS đã biến từ một tham số khó điều chỉnh như IoU threshold trở thành một tham số dễ nắm bắt hơn (k) và ngoài ra còn tận dụng được lợi thế về khoảng cách với tâm của gt. Ngoài ra còn các phương pháp khác có thể kể tới như PAA (Point-based Anchor Assignment) hay OTA.
TOOD
Gần đây hơn, xu hướng của LA thiên về việc làm sao để mô hình tự học cách label. Có thể kể tới như TOOD 8 (Task-aligned One-stage Object Detection). Các tác giả của TOOD giải thích rằng với các mô hình one-stage detector hiện tại chia 2 nhiệm vụ classification và localization thành 2 branches riêng biệt. Điều này có thể dẫn đến một tình huống khi anchor (anchor points cho anchor-free và anchor boxes cho anchor-based) tối ưu của 2 nhiệm vụ không nhất quán và sai lệch đáng kể tùy thuộc vào hình dạng và đặc điểm của đối tượng.
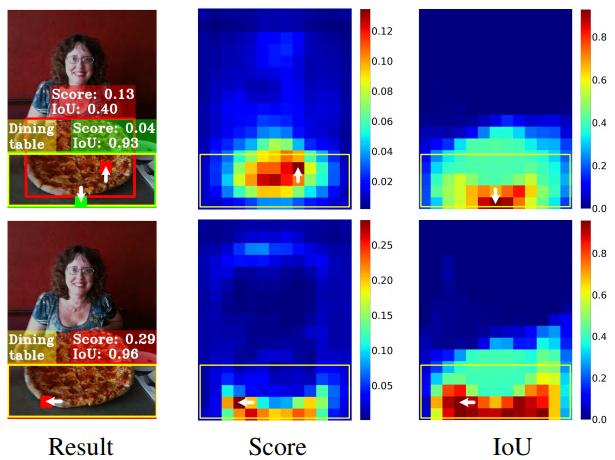
Hình ảnh trên so sánh score và IoU giữa ATSS (trên) và TOOD (dưới). Ở cột Result, box màu vàng là gt, mũi tên màu trắng thể hiện hướng đi chủ yếu của optimal anchor từ tâm của object, box đỏ (result)/vàng (score) thể hiện best anchor for classificaton, box xanh (result)/xanh (IoU) thể hiện bets anchor for bounding box. Với ATSS ta dễ nhận ra đối tượng Dining table được detect nhầm sang cả pizza trong khi TOOD không gặp tình huống như vậy.
Để tránh dài dòng, mình sẽ tóm tắt lại ý tưởng LA của TOOD khi đã biết mục đích của nó như trên. TOOD giới thiệu một cách sắp xếp mới cho Task-aligned head (T-head) và Task Alignment Learning (TAL) để tạo ra một phương pháp phát hiện đối tượng với sự tham gia đồng thời của cả 2 branches chứ không phải độc lập như trước khi. Khi đó, ta tính:
Trong đó, , là các ma trận dự đoán lần lượt của classification và bounding box branches. , là các hyperparameter để điều chỉnh tác động của mỗi branches.
Sau đó với mỗi ground truth ta sẽ chọn m anchors có giá trị t cao nhất làm positive samples. Các anchors còn lại sẽ coi là negative. Mục tiêu của chiến lược gán nhãn này là anchor tốt phải có khả năng dự đoán score cao và localization chính xác. Chú ý rằng, đây chỉ là ý tưởng chính của LA trong TOOD, về cụ thể hơn mình khuyến khích các bạn hãy tìm đọc paper gốc 8.
Lời kết
Cho tới hiện tại, với sự xuất hiện của mô hình DETR (DEtection TRansformer) - đã loại bỏ việc sử dụng anchors cũng như các cơ chế gán nhãn truyền thống tuy vậy vẫn còn hạn chế về tốc độ hồi quy, khó phát hiện vật thể nhỏ, yêu cầu chi phí tính toán cao hơn,... Tóm lại, Label Assignment vẫn đóng một vai trò nhất định trong lĩnh vực nghiên cứu, và tạo nền móng cho những nghiên cứu sau này.
Bài viết của mình còn có thể chứa nhiều chỗ sai sót, mong sự đóng góp từ các bạn để mình có thể chỉnh sửa bài viết tốt hơn.
Reference
- Rich feature hierarchies for accurate object detection and semantic segmentation
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
- RepPoints: Point Set Representation for Object Detection
- Focal Loss for Dense Object Detection
- FCOS: Fully Convolutional One-Stage Object Detection
- Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
- Task-aligned One-stage Object Detection
All rights reserved
