Đĩ Nghiện Code Thuật Vấn Đáp cách xây dựng một website hàng triệu người dùng P6 Monitor
Bài đăng này đã không được cập nhật trong 3 năm
Trời cuối thu Hà Nội đẹp hơn cả bức tranh, anh nghiện đang phê pha điếu thuốc, thả hồn mơ màng theo làn khói, nhìn cảnh hoàng hôn tươi đẹp bên hồ thì lại thấy bóng dáng kiều nữ thướt tha đi tới.
Link toàn bộ tại đây
Đĩ: Em chào anh, đã lâu không gặp.
Nghiện: Dạo này hệ thống chạy ngon giầu rồi nên không thấy hỏi han gì anh nữa rồi nhỉ?
Đĩ: Em đến cảm ơn anh đây, giờ em giầu rồi anh cần gì cứ bảo em một câu, chỉ có điều.
Nghiện: Điều gì?
Đĩ: Hệ thống của em thỉnh thoảng nó chết, lúc thì treo server, lúc thì nghẽn mạng, lúc lại treo DB. Mà em không biết xử lý làm sao.
Nghiện: Em đã có hệ thống monitor và ghi log nào cho cái hệ thống siêu to khổng lồ chưa?
Đĩ: Em chưa có, bên em toàn đường cong vun vút, làm gì có cái màn hình phẳng nào đâu mà phải monitor.
Nghiện: Đó là hệ thống cho em biết khi nào sắp lỗi để xử lý hoặc lỗi xảy ra khi nào và tại sao.
Đĩ: Hay thế nhỉ đúng cái em đang cần, có phải khi hệ thống mà trước khi treo như RAM tăng, CPU tăng thì nó báo về cho em biết trước để chuẩn bị, và nếu có lỗi xảy ra thì em biết được lỗi ở đâu đúng không anh?
Nghiện: Đúng rồi. Hệ thống sẽ có các phần
- Loging: Nó log lại các vấn đề trong hệ thống của em
- Monitoring: Nó sẽ lấy các thông tin cần monitor của hệ thống, lưu lại để xem hoặc phân tích dự đoán vấn đề trong tương lại
- Alerting : Nó sẽ bắn thông báo khi vấn đề sắp xảy ra hoặc đã xảy ra
Đĩ: Nhìn anh hút thuốc ngầu như Hứa Văn Cường vậy. Chi tiết xây dựng như thế nào ạ
Nghiện: Mày rủa tao chết sớm vì gái à. Xây dựng sẽ thường như thế này. Đàu tiên là về hệ thống loging. Đơn giản nhất và trước kia hay làm là log vào file, kiểu mỗi ngày log Error hay Info, Debug... vào file như file system_log.txt kiểu vậy. Nhược điểm là sẽ khó truy vấn ngay vấn đề mà phải vào đọc file, khó thống kê được tần suất lỗi.
Đĩ: Vậy em nghĩ ra rồi, mình chỉ cần log vào database của hệ thống là OK thôi, có thể thống kê, truy vấn nhanh gọn lệ.
Nghiện: Vấn đề là nếu log vào chung hệ thống database là số lượng log quá nhiều sẽ gây tăng dung lượng hệ thống khi log quá lớn cũng khó thống kê và truy vấn, và lượng connection quá lớn khi ghi log có thể gây ảnh hưởng tới db chính. Vì vậy người ta xây dựng một hệ thống log riêng ví dụ hệ thống ELK Stack để ghi log, vừa không ảnh hưởng tới hệ thống chính vừa dễ dàng truy vấn thống kê.
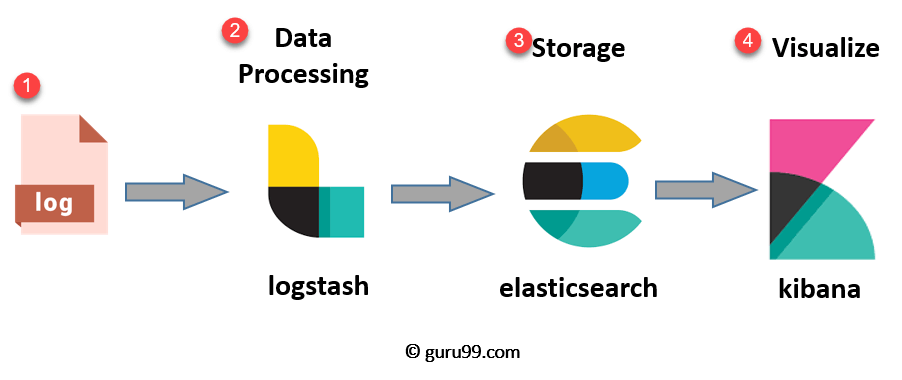
Đĩ: Ok vậy em sẽ dùng luôn con ELK Stack, vậy còn monitor
Nghiện: Loging còn bao gồm cả hành vi người dùng, để thống kê và đưa ra tính năng phù hợp, trường hợp đó có thể dùng Google Analytic. Còn về monitor cách đơn giản nhất là lâu lâu query vào server một lần xem trạng thái server thế nào, nhưng như thế rất mệt và tốn công, cũng nhờ mấy ông lười các ông nghĩ ra hệ thống monitor với Prometheus và Grafana. Bản chất thì Prometheus là một cơ sở dữ liệu thời gian thực, các server sẽ đẩy các dữ liệu vào đó (Nghe khác gì loging đâu) và Grafana mà một bộ tool hỗ trợ đọc dữ liệu từ đó ra và hiển thị lên.
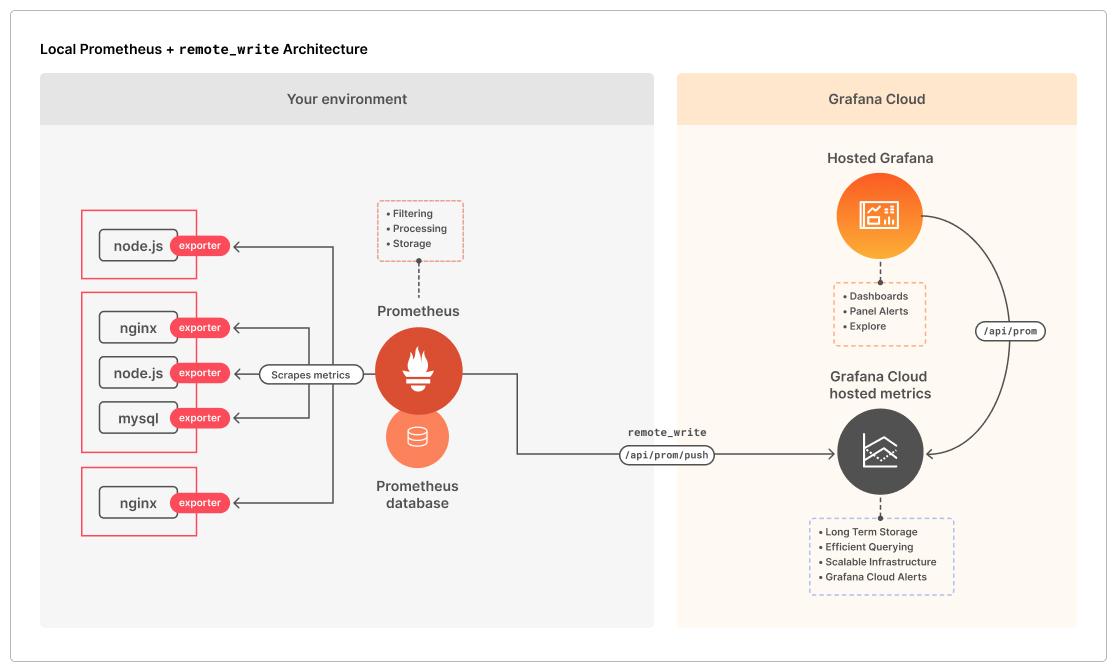
Đĩ: Nhưng nó chỉ log được thông tin CPU, RAM DISK thôi hả anh, em muốn nhiều hơn có được không?
Nghiện: Thực tế nó là một DB em thích ghi thêm cái gì vào đó thì ghi, và Grafana cũng là một tool hiển thị, nó hỗ trợ đọc từ nhiều nguồn chứ không chỉ Prometheus. Em có thể chọn đọc từ nhiều loại khác nhau.
Đĩ: Em có một nhu cầu thế này, em muốn log những request bị lỗi, những request bị chậm khi gọi từ client lên server thì làm thế nào?
Nghiện: Lúc đó em có thể dùng một hệ thống log là APM (application performance monitoring ), có tích hợp luôn trong ELK Stack hỗ trợ em ghi được thời gian phản hồi mỗi request và số lượng request lỗi. Giúp em tìm được các vấn đề hiệu quả hơn.
Đĩ: Ok vậy là xong phần monitor và log rồi, còn phần cảnh báo là thông báo khi có vấn đề đúng không anh?
Nghiện: Đúng rồi vấn đề thông báo là em thiết lập các tham số để cảnh báo về cho em biết khi vấn đề sặp xảy ra hoặc đang/ đã xảy ra. Thường em cấu hình băn vào slack hoặc email khi có vấn đề xẩy ra.
Đĩ: Ok vậy là với hệ thống này em có thể tìm ra các vấn đề cần giải quyết, còn giải quyết như thế nào anh nhỉ?
Nghiện: hút nốt rồi cười, vấn đề thì có vô số phải giải quyết từ từ thôi. Với hệ thống của em khi gặp vấn đề hiệu năng cần xem xét nhiều giải pháp. Như thiết kế database, cách dùng index chuẩn chưa, trên hệ thống có xử lý bất đồng bộ không? có xử lý song song không? Hệ thống AutoScaling hay không nữa... Nói chung cũng nhiều. Series này chủ yếu về thiết kế một hệ thống cơ bản các thành phần của một hệ thống lớn và các kỹ thuật đi kèm như loadbalancing, Queue, Cache, Replicate, Shading, Pubsub, HA, Leader election, monitor. Ngoài ra có thể có thêm hệ thống Stream polling ,MapReduce.
Chuỗi này kết thúc ở đây, các bài sau mình sẽ tập trung vào vấn đề hay gây ra hiệu năng nhất cho hệ thống, là database. Mong các bạn đón đọc. Mình mới tạo ra một group để các bạn thảo luận nhằm xây dựng lên một cộng đồng lập trình viên level quốc tế mong mọi người góp sức. Nhóm mới tinh nhé.
All rights reserved
