Design pattern - Cây, Chim và các cuộc tập trận
Có một chi tiết khá thú vị trong software engineering đó là nhiều deployment pattern phổ biến nhất lại xuất phát từ những quan sát trong tự nhiên và lịch sử. Sau đây là 3 pattern khá thú vị tôi muốn giới thiệu với anh em:
- Strangler Fig lấy ý tưởng từ một loài cây ở rừng nhiệt đới Australia.
- Canary Deployment đến từ cách thợ mỏ dùng chim hoàng yến để phát hiện khí độc.
- Blue/Green Deployment mượn ngôn ngữ từ các cuộc tập trận quân sự.
Ba pattern này ra đời trong ba bối cảnh hoàn toàn khác nhau. Nhưng nếu nhìn kỹ thì chúng đều giải quyết cùng một bài toán:
Làm sao thay đổi một hệ thống đang chạy mà không tự bắn vào chân mình.
Thay vào đó hệ thống cũ vẫn còn sống một thời gian, traffic được chuyển dần, và luôn chừa đường lui nếu có vấn đề xảy ra.
Vì production luôn có quá nhiều biến số mà không môi trường nào khác kể cả staging có thể mô phỏng lại hoàn toàn được. Và phần khó nhất của engineering thường không phải là làm cho hệ thống chạy được, mà là giữ cho nó vẫn ổn định khi mọi thứ bắt đầu đi ngược với tính toán ban đầu.
Có những thứ chỉ xuất hiện khi: traffic đủ lớn, data đủ đa dạng và users bắt đầu dùng hệ thống theo những cách mình chưa từng nghĩ tới.
Giờ thì thử nhìn kỹ hơn xem ba pattern này thực sự được tạo ra để giải quyết vấn đề gì, và tại sao mỗi cái lại chọn một cách rollout khác nhau nhé anh em.
I. Strangler Fig pattern
Năm 2004, Martin Fowler đi qua một khu rừng ở Queensland và được giới thiệu về strangler fig, một loại cây bắt đầu vòng đời của mình bằng cách sống bám trên thân cây khác.
Ban đầu nó chỉ là một hạt nhỏ nằm dưới gốc cây chủ. Sau đó nó mọc rễ dần xuống đất, lấy dinh dưỡng, phát triển lớn hơn và quấn quanh cây chủ theo thời gian. Cuối cùng cây chủ chết đi, còn lại hệ cây mới có hình dạng tương tự như cây chủ. Fowler nhìn thấy hình ảnh đó và ứng dụng để đưa ra giải pháp để thay thế legacy systems nhưng vẫn đảm bảo tính ổn định của hệ thống.
Không phải rewrite toàn bộ trong một lần. Mà là thay dần từng phần, trong khi hệ thống cũ vẫn tiếp tục chạy.
1. Strangler Fig Pattern là gì?
Strangler Fig Pattern là một chiến lược migrate hệ thống cũ bằng cách xây hệ thống mới bao bọc hệ thống cũ và chuyển traffic dần sang hệ thống mới.
 Ban đầu, mọi request vẫn đi vào legacy system. Sau đó, tuỳ theo chiến lược, từng endpoint, từng module, hoặc từng business domain được migrate sang service mới. Khi không còn traffic vào legacy nữa thì thực hiện decommission legacy system.
Ban đầu, mọi request vẫn đi vào legacy system. Sau đó, tuỳ theo chiến lược, từng endpoint, từng module, hoặc từng business domain được migrate sang service mới. Khi không còn traffic vào legacy nữa thì thực hiện decommission legacy system.
2. Vì sao pattern này tồn tại?
Phần lớn big rewrite (Big bang replacement) đều khó thành công hơn và mang rủi ro rất lớn, đặc biệt với những hệ thống không chấp nhận downtime.
Có 1 số lý do để sử dụng pattern này:
- Legacy chứa rất nhiều behavior không được document
- Production data luôn có edge case
- Rewrite hoàn toàn hệ thống mang rủi ro mất kiểm soát vì độ phức tạp quá lớn
3. Cách hoạt động
- Xây dựng hệ thống mới bao gồm gateway hoặc facade nhằm mục đích foward traffic về legacy system.
- Sau đó từng bước xây dựng những service mới. Có thể dựa vào những tiêu chí về rủi ro, hoặc các tính năng riêng biệt để có thể rollout và rollback nếu phát sinh lỗi
- Thực hiện route 1 lượng traffic sang service mới và monitor đảm bảo rằng cụm service mới này có thể thay thế các service của legacy system. Nếu phát sinh lỗi, thực hiện route traffic ngược lại legacy system.
- Thực hiện tương tự với những service khác cho đến khi toàn bộ traffic được route về các service của hệ thống mới. Lúc này, chúng ta thực hiện decomission legacy system
Ví dụ: giả sử chiến lược là thay thế từng phần theo API endpoint
T0: Traffic 100% đổ về legacy thông qua facade
/user → legacy
/payment → legacy
/loan → legacy
T1: Route traffic của /user sang service mới, giữ traffic các endpoint khác
/user → service mới
/payment → legacy
/loan → legacy
T2: Tiếp tục với /payment
/user → service mới
/payment → service mới
/loan → legacy
T3: Toàn bộ API được route sang service mới, có thể decommision legacy system
/user → service mới
/payment → service mới
/loan → service mới
T4: Decommission legacy
T: là khoảng thời gian tương đối, có thể tính bằng vài sprint hoặc vài tháng
4. Ưu nhược điểm
4.1. Ưu điểm
- Kiểm soát độ phức tạp của mỗi lần rollout và có thể rollback được. Nếu service mới có vấn đề, chỉ cần route traffic ngược về legacy. Không cần rollback toàn bộ hệ thống.
- Zero downtime: Hệ thống vẫn chạy trong suốt quá trình migration. Đặc biệt quan trọng với các hệ thống khó chấp nhận maintenance window dài.
- Team có thời gian học domain dần dần, phù hợp với những team phải đi hốt sản phẩm của team trước đó. Rewrite toàn bộ yêu cầu team hiểu gần như toàn bộ business logic ngay từ đầu.
- Có thể đồng thời phát triển thêm tính năng mới trên legacy system
4.2. Nhược điểm
- Hai hệ thống tồn tại song song trong thời gian dài dẫn đến cost duy trì cả 2 hệ thống cực lớn trong thời gian migration
- Rủi ro của việc phát triển tính năng đồng thời trên legacy system làm hệ thống mới không kịp catch up
- Xử lý vấn đề đồng bộ dữ liệu giữa 2 hệ thống, data consistency, đảm bảo khi rollback không làm ảnh hưởng đến legacy
- Cần xác định deadline cho quá trình migrate, tránh việc dàn trải migration dẫn đến techdebt phải maintain cả 2 hệ thống
5. Khi nào nên sử dụng?
Strangler Fig phù hợp khi:
- Monolith quá lớn để rewrite một lần
- Hệ thống không chấp nhận downtime
- Cần kiểm soát rollback theo từng phần nhỏ
- Hoặc business vẫn thay đổi liên tục trong lúc migrate.
- Đặc biệt hữu ích với những domain có nhiều unknown behavior trong production.
II. Canary Deployment
Để phát hiện khí độc trong hầm mỏ, ngày nay người ta dùng các sensor điện tử để cảnh báo sớm nguy hiểm cho công nhân. Nhưng trước khi có những thiết bị đó, thợ mỏ ở Anh từng mang theo chim hoàng yến (canary) xuống hầm mỏ như một hệ thống cảnh báo sống.
Lý do rất đơn giản bởi vì loài chim này nhạy cảm với methane và carbon monoxide hơn con người, nên sẽ phản ứng sớm hơn khi phát hiện chất độc trong không khí.
 Khoảng đầu những năm 2000, Google bắt đầu dùng từ “canary” cho một deployment strategy có ý tưởng gần giống như vậy:
Khoảng đầu những năm 2000, Google bắt đầu dùng từ “canary” cho một deployment strategy có ý tưởng gần giống như vậy:
- Cho một nhóm nhỏ users chạy version mới trước
- Quan sát production behavior
- Rồi mới rollout rộng hơn
1. Canary Deployment là gì?
Canary Deployment là kỹ thuật release version mới cho một phần nhỏ traffic trước khi rollout toàn bộ.
Ví dụ:
10% traffic → version mới
90% traffic → version hiện tại
-
Nếu bản rollout mới thoả mãn những tiêu chí được đề ra thì tiếp tục tăng traffic sang version mới.
- metrics ổn
- error rate bình thường
- latency không tăng
- không có alarm
-
Ngược lại, nếu phát hiện vấn đề thì stop deployment và route traffic về stable version trước đó.
Điểm cần lưu ý ở đây là canary dùng production traffic thật. Do đó, nó detect được rất nhiều vấn đề mà staging không cover hết được.
2. Vì sao cần Canary?
Vì các môi trường dưới không bao giờ giống production hoàn toàn. Dù test kỹ tới đâu thì production vẫn luôn có
- traffic pattern khác
- data đa dạng
- dependency timing
- cache behavior
- hoặc concurrency issue chỉ xuất hiện dưới load thật
Canary không cố “đảm bảo sẽ không có bug”. Nó chấp nhận rằng sẽ luôn có những vấn đề chỉ xuất hiện sau khi deploy thật
Và thay vì để 100% users gặp vấn đề cùng lúc, pattern này giảm blast radius xuống nhỏ nhất có thể.
3. Cách hoạt động
Rollout dần dần đồng thời monitor phát hiện vấn đề sớm nhất có thể. Nếu phát sinh vấn đề thì stop deployment và rollback về version stable trước đó.
Trong suốt quá trình rollout:
- stable version vẫn còn sống
- traffic chỉ được shift dần sang version mới
Chúng ta có thể rollback gần như ngay lập tức nếu phát hiện sự cố.
Trong ECS CodeDeploy, có thể được cấu hình bằng cách config deployment strategy:
- Canary10Percent5Minutes
- Linear10PercentEvery1Minutes
- hoặc custom deployment config
Ví dụ:
Minute 0
10% → new version
90% → stable
Minute 10
Nếu ổn → tăng 25%
Minute 20
Nếu ổn → tăng 50%
Minute 30
Nếu ổn → rollout 100%
4. Ưu nhược điểm
4.1. Ưu điểm
- Giảm blast radius: Nếu deployment có bug, chỉ một phần nhỏ users bị ảnh hưởng. Đây là khác biệt rất lớn giữa lỗi ảnh hưởng 5% traffic và lỗi làm toàn bộ production fail.
- Detect được lỗi production thật: Canary chạy với traffic thật, data thật, dependencies thật. Những thứ ở staging thường rất khó mô phỏng đầy đủ.
4.2. Nhược điểm
- Bắt buộc phải có observability tốt. Canary gần như vô dụng nếu metrics không chuẩn, monitoring thiếu hoặc alert quá chậm. Canary chỉ hiệu quả khi detect được abnormal behavior đủ sớm.
- Hai version phải compatible với nhau. Trong giai đoạn rollout version cũ và version mới cùng chạy song song. Để đảm bảo có thể rollback nhanh chóng thì database migration, event schema, message format phải backward compatible.
- Có thể xuất hiện false alert có thể làm latency tăng tạm thời dù application không thật sự lỗi. Ví dụ:
- JVM cold start
- cache chưa warm
- connection pool chưa ổn định
5. Khi nào nên sử dụng?
Canary phù hợp khi:
- Production traffic khó mô phỏng ở những môi trường dưới. Phụ thuộc vào các bên thứ 3 không thể kiểm soát được output
- Risk của deployment cao
- Cần detect issue sớm
- Team deploy thường xuyên cũng nên sử dụng pattern này để tự tin hơn trong mỗi lần release
Đặc biệt hữu ích với:
- Distributed systems
- Recommendation systems
- High-traffic APIs
- Các hệ thống phụ thuộc nhiều vào behavior thực tế của users
III. Blue/Green Deployment
Trong các cuộc tập trận quân sự, các phe tham gia thường được đánh dấu bằng màu khác nhau để tránh nhầm lẫn trong quá trình diễn tập. Một bên sẽ là Blue Force là lực lượng mình đóng vai “phe ta”. Bên còn lại là Red Force/ Green Force đóng vai đối thủ giả lập.
Khi nhiều lực lượng cùng hoạt động trên một chiến trường mô phỏng, chỉ cần nhận diện sai một chút là đủ tạo ra “friendly fire”. Vì vậy mọi thứ phải được tách biệt thật rõ ràng trước khi cuộc diễn tập bắt đầu.
Khi Jez Humble và Dave Farley viết về Continuous Delivery, họ dùng chính ý tưởng đó cho deployment systems.
- Luôn có hai trạng thái rõ ràng
- Không để hệ thống ở trạng thái nửa cũ nửa mới quá lâu
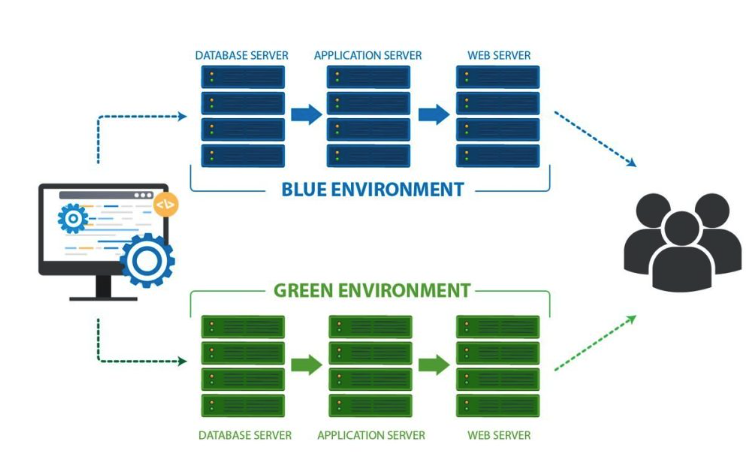
1. Blue/Green Deployment là gì?
Blue/Green Deployment là kỹ thuật duy trì hai production environments giống hệt nhau.
Tại một thời điểm: một environment đang live, environment còn lại idle.
Ví dụ
- Blue tương đương với production hiện tại và Green đang chứa version mới
- Deployment xảy ra trên Green trước
- Sau khi test xong load balancer switch toàn bộ traffic từ Blue sang Green
- Nếu có sự cố switch ngược lại
rollback không cần redeploy
2. Vì sao cần Blue/Green?
Với Canary vẫn có một khoảng thời gian version cũ và version mới cùng nhận traffic. Điều đó nghĩa là vẫn có users hit bug nếu deployment có vấn đề. Blue/Green giải quyết chuyện đó bằng cách:
- Chuẩn bị environment mới hoàn toàn ở background
- Thực hiện test trước, rồi switch traffic sau
3. Cách hoạt động
Flow cơ bản
- Duy trì 2 môi trường song song
- Blue → live traffic
- Green → deploy + smoke test
- Sau khi verify xong, config load balancer
- Blue → 0%
- Green → 100%
Đối với ECS CodeDeploy, thực tế hầu hết deployments đều là Blue/Green ở tầng infrastructure:
- CodeDeploy tạo task set mới
- Attach vào target group mới
- Rồi thực hiện shift traffic
4. Ưu nhược điểm
4.1. Ưu điểm
- Rollback nhanh. Nếu deployment fail chỉ cần switch traffic ngược lại. Không cần rebuild → redeploy → restart cluster.
- Zero downtime. Traffic switch xảy ra ở load balancer layer nên application gần như không bị gián đoạn.
- Green environment có thể warm-up trước. Trước khi nhận traffic thật, có thể preload cache, warm JVM, chạy smoke test, verify dependencies.
4.2. Nhược điểm
- Infrastructure cost cao hơn Trong thời gian deploy: phải chạy hai full environments cùng lúc.
- Large clusters
- Memory-heavy services
- GPU workloads
- Database migration khó. Nếu schema migration không backward compatible thì có thể phát sinh vấn đề nếu không có plan cho rollback database
- Không detect được issue dưới production load thật. Green environment được test trước khi live, nhưng chưa có traffic thật, chưa có production concurrency, chưa có real usage pattern. Nghĩa là một số vấn đề chỉ xuất hiện sau khi switch sang Green.
5. Khi nào nên sử dụng?
Blue/Green phù hợp khi:
- Hạn chế tối đa ảnh hưởng đến người dùng thật
- Zero downtime
- Infrastructure cost không phải constraint lớn nhất
- Service tương đối stateless
Pattern này đặc biệt phổ biến trong:
- Financial systems
- Internal platforms
- Các systems có strict SLA
Kết luận
Ba pattern này giải quyết ba bài toán khác nhau
- Strangler Fig: Migration dài hạn
- Canary: Giảm blast radius khi release
- Blue/Green: Rollback nhanh và zero downtime
Nhưng điểm thú vị là cả ba đều dựa trên cùng một nguyên lý: luôn chừa đường lui khi phát sinh vấn đề
Đảm bảo production vẫn sống khỏe, hạn chế ảnh hưởng đến end user, và quan trọng nhất: tờ A4 của anh em vẫn còn hiệu lực 😉
Nếu anh em cảm thấy bài viết hữu ích đừng ngần ngại click upvote cho bài viết, hoặc phát hiện ý nào chưa hợp lý hoặc cần giải thích thêm hãy comment cho tôi biết để cùng trao đổi nhé. Anh em có thể tham khảo các bài viết khác của tôi tại Blog cái nhân hoặc kết nối với tôi qua Linkedin
All rights reserved
